부제: News Classification using BERT
파일 및 필드 설명
2012년부터 2022년까지의 약 210,000개의 뉴스 헤드라인
데이터 세트의 각 레코드는 다음과 같은 속성으로 구성
- 카테고리: 기사가 게재된 카테고리
- 헤드라인: 뉴스 기사의 헤드라인
- 저자: 기사에 기여한 저자 목록
- 링크: 원본 뉴스 기사로의 링크
- short_description: 뉴스 기사의 요약
- 날짜: 기사가 출판된 날짜
데이터 세트에는 총 42개의 뉴스 카테고리
형식:
- 영어 불용어 사전
- 예시 : a, about ,above, after, again, against, all라이브러리 및 패키지 설치
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set_style('darkgrid') import nltk from nltk import word_tokenize from nltk.stem import WordNetLemmatizer import tensorflow as tf from tensorflow.keras.models import Model, save_model, load_model from tensorflow.keras.layers import Dropout, Input, Dense, Lambda from transformers import DistilBertTokenizer, TFAutoModel, AdamW, TFDistilBertModel from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping from tensorflow.keras import backend as K from tensorflow.keras.layers import Layer from tensorflow.keras.layers import Dense from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix, classification_report import regex as re import pickle import warnings warnings.filterwarnings('ignore') nltk.download('punkt') nltk.download('wordnet') nltk.download('punkt_tab')
데이터로드 및 데이터 파악
# 데이터로딩
news = pd.read_json('/Users/taixi/Desktop/small_project/News Category Dataset/News_Category_Dataset_v3.json', lines=True)
news.head()
EDA
news = news[['headline', 'short_description', 'category']] # feature selection
news.head()
Category
news.category.unique()
news.category = news.category.replace({"HEALTHY LIVING": "WELLNESS",
"QUEER VOICES": "GROUPS VOICES",
"BUSINESS": "BUSINESS & FINANCES",
"PARENTS": "PARENTING",
"BLACK VOICES": "GROUPS VOICES",
"THE WORLDPOST": "WORLD NEWS",
"STYLE": "STYLE & BEAUTY",
"GREEN": "ENVIRONMENT",
"TASTE": "FOOD & DRINK",
"WORLDPOST": "WORLD NEWS",
"SCIENCE": "SCIENCE & TECH",
"TECH": "SCIENCE & TECH",
"MONEY": "BUSINESS & FINANCES",
"ARTS": "ARTS & CULTURE",
"COLLEGE": "EDUCATION",
"LATINO VOICES": "GROUPS VOICES",
"CULTURE & ARTS": "ARTS & CULTURE",
"FIFTY": "MISCELLANEOUS",
"GOOD NEWS": "MISCELLANEOUS"}
)
len(news['category'].unique())plt.figure(figsize=(10, 10))
plt.pie(x=news.category.value_counts(), labels=news.category.value_counts().index, autopct='%1.1f%%', textprops={'fontsize' : 8,
'alpha' : .7});
plt.title('The precentage of instance belonging to each class', alpha=.7);
plt.tight_layout();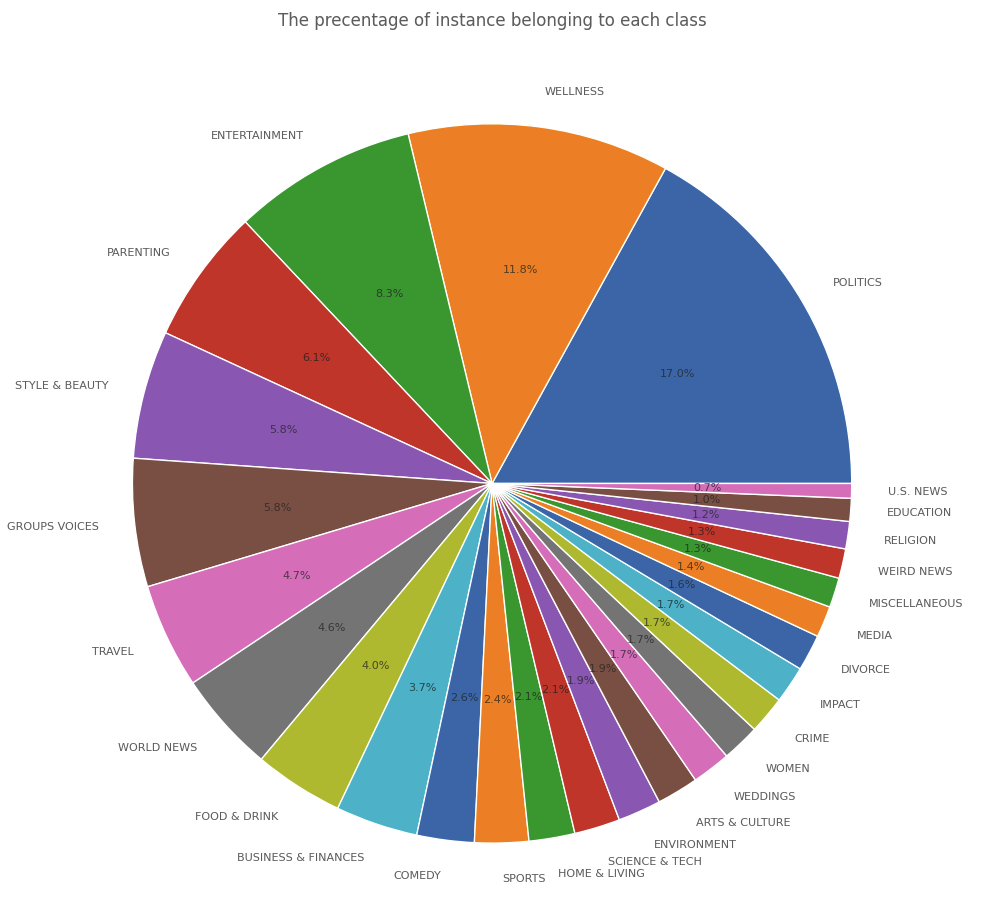
전처리
# 영어불용어사전 사용
with open('/Users/taixi/Desktop/small_project/News Category Dataset/EN-Stopwords.txt', 'r') as f:
stopwords = f.readlines()
f.close()
stopwords = [re.sub('\n', '', w) for w in stopwords]
def text_preprocessing(df:pd.DataFrame):
lem = WordNetLemmatizer()
new_df = pd.DataFrame(columns=['head_desc', 'category'])
max_len = 0
for index, row in df.iterrows():
head_desc = row.headline + " " + row.short_description
head_desc_tokenized = word_tokenize(head_desc) # Word Tokenization
punctuation_stopwords_removed = [re.sub(r'[^\w\s]', '', token) for token in head_desc_tokenized if not token in stopwords] # punctuations and stopwords removal
number_removed = [re.sub(r'\d+', '', token) for token in punctuation_stopwords_removed] # numbers removal
head_desc_lemmatized = [lem.lemmatize(token) for token in number_removed] # Word Lemmatization
empty_str_removed = [token for token in head_desc_lemmatized if token != ''] # empty strings removal
if len(empty_str_removed) > max_len:
max_len = len(empty_str_removed)
new_df.loc[index] = {
'head_desc' : " ".join(empty_str_removed),
'category' : row['category']
}
X, y = new_df['head_desc'], new_df['category']
return X, y, max_len
X, y, max_len = text_preprocessing(news)
def save_data(name, data):
with open(name, 'wb') as f:
pickle.dump(data, f)
f.close()
save_data('X.h5', X)
save_data('y.h5', y)
save_data('max_len', max_len)
def load_data(name):
return pickle.load(open(name, 'rb'))
max_len
X.shape, y.shape
y.head()
y = pd.get_dummies(y) # OHE
classes_name = y.columns.tolist()
y.head()
y = y.replace([True, False], [1, 0]).values
y.shape133
((209527,), (209527,))


(209527, 27)
데이터분할
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=.3, random_state=42)
X_eval, X_test, y_eval, y_test = train_test_split(X_temp, y_temp, test_size=.5, random_state=42)
# create a DistilBertTokenizer object
tokenizer = DistilBertTokenizer.from_pretrained(pretrained_model_name_or_path="distilbert-base-uncased")
save_data('tokenizer.h5', tokenizer)토큰화
def tokenizer_preprocessing(texts, tokenizer):
encoded_dict = tokenizer.batch_encode_plus(
texts,
return_token_type_ids=False,
pad_to_max_length=True,
max_length=max_len
)
return np.array(encoded_dict['input_ids'])
padded_train = tokenizer_preprocessing(X_train, tokenizer)
padded_eval = tokenizer_preprocessing(X_eval, tokenizer)
padded_test = tokenizer_preprocessing(X_test, tokenizer)
save_data('padded_train.h5', padded_train)
save_data('padded_eval.h5', padded_eval)
save_data('padded_test.h5', padded_test)
padded_train.shape, padded_eval.shape, padded_test.shape((146668, 133), (31429, 133), (31430, 133))
모델 설정 및 훈련
import shutil
import os
cache_dir = os.path.expanduser('~/.cache/huggingface/transformers')
if os.path.exists(cache_dir):
shutil.rmtree(cache_dir)
import torch_optimizer as optim
from tensorflow.keras.optimizers import Adam
with dist_strategy.scope():
pretrained_model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
if pretrained_model is not None:
# 모델 사용
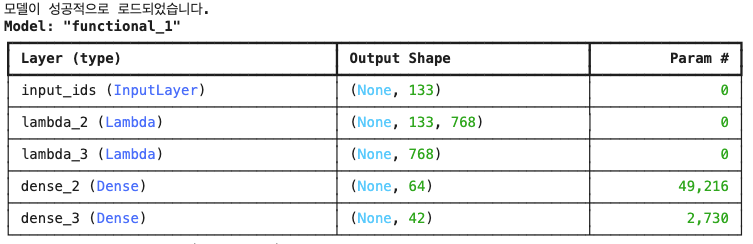
print("모델이 성공적으로 로드되었습니다.")
else:
print("모델 로드에 실패했습니다")
# 입력 레이어 정의
input_ids = Input(shape=(max_len,), dtype='int32', name='input_ids')
# Lambda 레이어에 DistilBERT 모델 적용
def apply_distilbert(x):
return pretrained_model(x)[0]
# 출력 형태 계산 함수
def distilbert_output_shape(input_shape):
return (input_shape[0], max_len, 768)
# Lambda 레이어 정의
bert_output = Lambda(apply_distilbert, output_shape=distilbert_output_shape)(input_ids)
# CLS 토큰 추출 함수
def extract_cls_token(x):
return x[:, 0, :]
# CLS 토큰 출력 형태 계산 함수
def cls_output_shape(input_shape):
return (input_shape[0], 768)
# CLS 토큰 추출을 위한 Lambda 레이어
cls_token = Lambda(extract_cls_token, output_shape=cls_output_shape)(bert_output)
# Dense 레이어 추가
x = Dense(64, activation='relu')(cls_token)
# 출력 레이어 (42개의 레이블에 대한 다중 레이블 이진 분류)
output_layer = Dense(42, activation='sigmoid')(x)
# 모델 정의
bert_tf = Model(inputs=input_ids, outputs=output_layer)
# 모델 컴파일 (다중 레이블 이진 분류에 적합한 손실 함수 사용)
bert_tf.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 요약
bert_tf.summary()
# 모델 훈련
EPOCHS = 50
BATCH_SIZE = 32 * dist_strategy.num_replicas_in_sync # 원래 배치 크기 설정
STEPS_PER_EPOCH = X_train.shape[0] // BATCH_SIZE # 치 수 계산
early_stopping = EarlyStopping(patience=10, restore_best_weights=True)
model_checkpoint = ModelCheckpoint(
'/content//model_weights.keras', # 확장자를 .keras로 변경
monitor='val_f1_score', # 모니터링할 메트릭
save_best_only=True
)
lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=2)
history = bert_tf.fit(
padded_train,
y_train,
validation_data=(padded_eval, y_eval),
epochs=EPOCHS,
steps_per_epoch=572,
callbacks=[lr, early_stopping, model_checkpoint]
)

plt.figure(figsize=(7, 7))
plt.plot(history.history['loss'], label='loss');
plt.plot(history.history['val_loss'], label='val_loss');
plt.legend();
plt.title('Loss vs Validation Loss');
plt.tight_layout();
plt.figure(figsize=(7, 7))
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.title('Accuracy vs Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.tight_layout()
plt.show()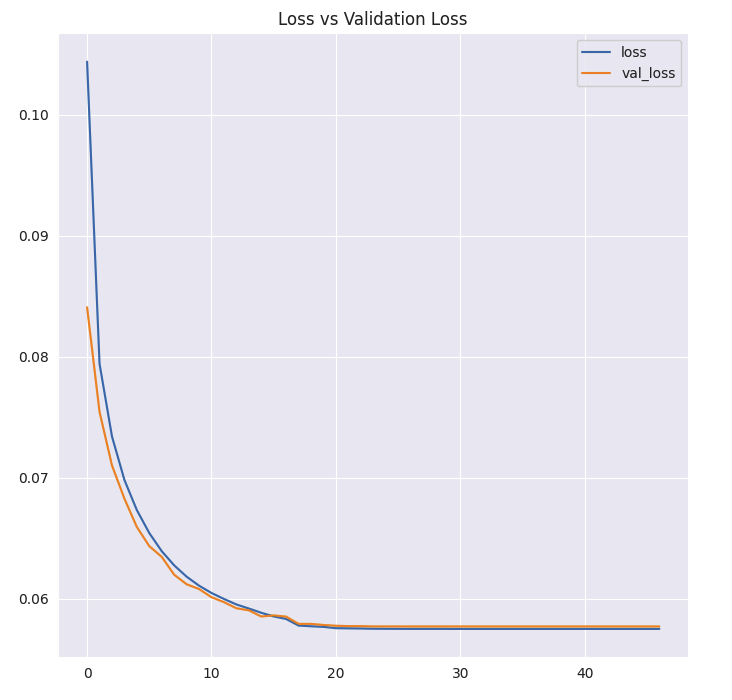
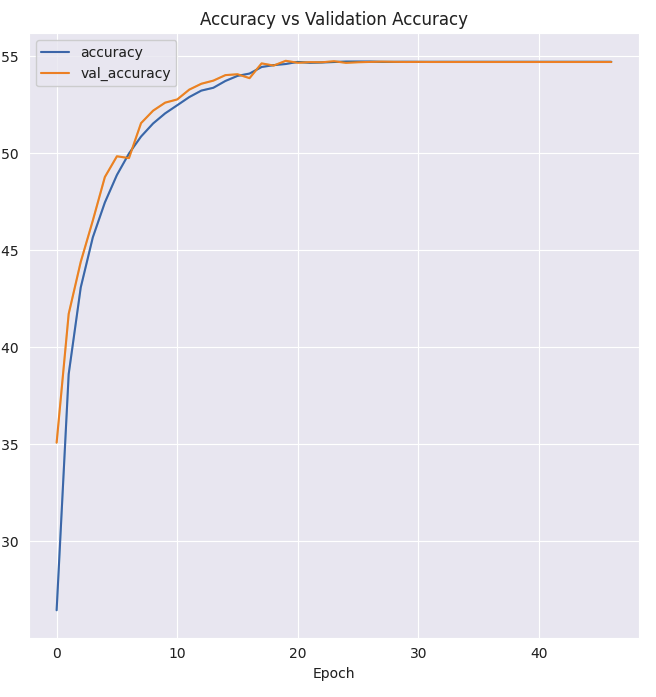
- loss는 낮은데 accuracy는 생각보다 높지않기때문에 개선이 필요함
y_pred = bert_tf.predict(padded_test)
y_pred_class = np.argmax(y_pred, axis=1) # 예측 클래스 추출
y_pred_class
y_test_class = np.argmax(y_test, axis=1)
y_test_class
print(classification_report(y_true=y_test_class, y_pred=y_pred_class))
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Oranges', cbar=False);
plt.tight_layout();
plt.xticks(range(conf_matrix.shape[0]), classes_name, rotation=90);
plt.yticks(range(conf_matrix.shape[0]), classes_name, rotation=360);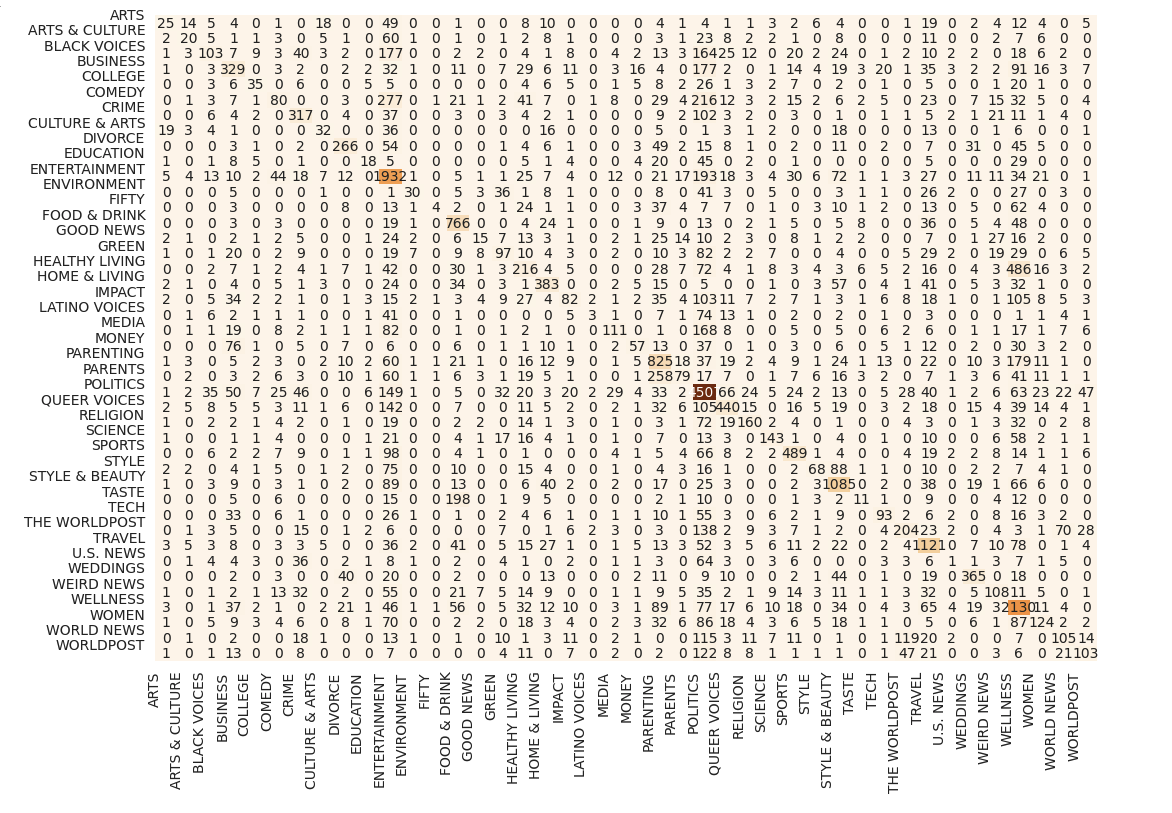
결론
💡 캐글을 통해 네이버 뉴스을 미리 경험함

개발자를 위한 첫시작