개인공부
1.Backpropagation

X: 입력 데이터 벡터/행렬W1, W2: 첫 번째 및 두 번째 층의 가중치 행렬b1, b2: 첫 번째 및 두 번째 층의 편향 벡터입력 데이터 X가 가중치와 편향을 거치면서 첫 번째 층을 통과하고, tanh 활성화 함수가 적용그 다음, 두 번째 층을 통과하면서 시그모이드
2.LoRA, QLoRA, DoRA, QDoRA
Parameter-Efficient Fine-Tuning (PEFT)은 모델의 모든 파라미터를 조정하지 않고, 특정 파라미터 집합만을 업데이트하여 모델을 튜닝하는 방법마이크로소프트에서 발표한 기술Full Fine-Tuning은 돈과 시간이 너무소요됨사전 훈련된 모델의
3.LoRA
브레인스토밍, 분류, 폐쇄형 QA, 생성, 정보 추출, 개방형 QA 및 요약을 포함한 여러 행동 범주에서 수천 명의 Databricks 직원이 생성한 지시 따르기 기록의 오픈 소스 데이터 세트databricks dolly 15k import osos.environ"KE
4.Text Classification using CNN
부제: Text classification using CNN acc 95% > ## 파일 설명 파일 설명
5.UK Population Data 2001/2011/2021
UK Regional Population Data.csv영국 인구 데이터Data resource - National Mammal Atlas Project.csv영국에서 목격한 포유류from urllib.request import urlopenwarnings.filter
6.News Category Dataset
2012년부터 2022년까지의 약 210,000개의 뉴스 헤드라인데이터 세트의 각 레코드는 다음과 같은 속성으로 구성카테고리: 기사가 게재된 카테고리헤드라인: 뉴스 기사의 헤드라인저자: 기사에 기여한 저자 목록링크: 원본 뉴스 기사로의 링크short_descriptio
7.Zero-shot, One-shot, Few-shot
Zero-shot (ZSL)모델이 학습 과정에서 본 적 없는 새로운 데이터를 인식할 수 있도록 하는 학습 방법모델이 클래스 간의 관계나 속성을 통해 일반화하는 능력 활용대규모 모델 사이즈로 대규모의 다양한 데이텃으로 학습한 경우 성능이 잘나옴training과 infer
8.RAG and LangChain
대형 언어 모델(LLMs)이 외부 컨텍스트를 활용해 환각(hallucination) 현상을 줄이고 정확도\*\*를 높이는 기술Retrieval (검색 단계)사용자의 질문(query)을 기반으로 외부 지식 소스에서 추가적인 컨텍스트를 검색외부 지식 소스는 여러 정보 조각
9.oLoRA, Trans-LoRA, VeLoRA, LoRA+
Parameter-Efficient Fine-Tuning (PEFT)은 모델의 모든 파라미터를 조정하지 않고, 특정 파라미터 집합만을 업데이트하여 모델을 튜닝하는 방법OLoRA는 QR 분해를 통해 직교 행렬(orthonormal matrix)을 초기화하여 모델 학습의
10.LtM(LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS)
쉬운 문제에서 어려운 문제로 일반화"를 가능과정Decomposition (문제 분해)과정: 주어진 문제를 여러 개의 하위 문제(subproblems)로 쪼개는 방법에 대한 예시를 프롬프트로 제시모델은 이러한 예시를 참고하여 복잡한 문제를 작고 해결 가능한 하위 문제들로
11.RAG에 관련된 기술
HyDE는 사용자의 질문을 토대로 가상문서를 생성하여, 이를 검색의 입력으로 사용함으로써 유사도 검색의 정확도를 높이는 방법가상의 문서는 질문의 의도를 명확히 반영하고 단순한 질문보다 더 많은 패턴을 제공여러개의 가상 문서를 생성한 뒤 평균화하여, 검색에 활용하기때문에
12.프롬프트
AI가 잘하는 것 : Semantics(단일성)사람이 잘하는 것 : Pragmatics(다의성),맥락파악 A : 지시문 + 출력문 항생제에 대해서 설명해줘B : 지시문 + 맥락 + 출력문 항생제를 주제로 대학교 생물학 수업 1장 짤리 레포터 를 제출해줘 C : 지시문
13.Vector Database
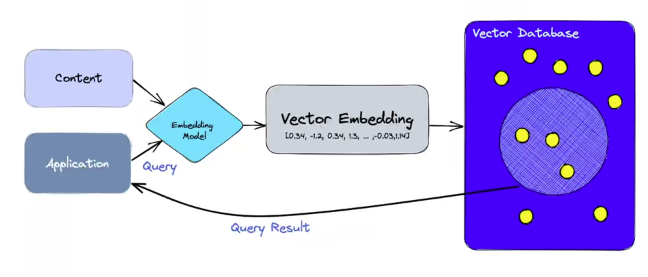
Vector 형태의 Embedding을 사용하여 데이터를 저장 인덱싱하는 데이터 베이스빠른 검색 및 대량의 데이터를 처리할 수있는 확장성복잡한 데이터에 특히 적합한 고차원 백터를 저장하고 처리하느데 중점을 둠Pinecone - API를 통해 사용자가 관리하는 클라우드
14.테디노트의 RAG 비법노트 : 랭체인을 활용한 GPT부터 로컬 모델까지의 RAG 가이드(후기)

구성요소파이프라인 구성요소메모리 데이터 로드RAGRAG 평가AgentLangGraph서비스배포총 72시간으로 되어있으며, RAG의 기초부터 응용까지 배울수 있음여러가지 작은 프로젝트를 함으로써 여러가지 기능을 실습할 수있음주주총회라고 매달마다 새로운 업데이트내용으로 라