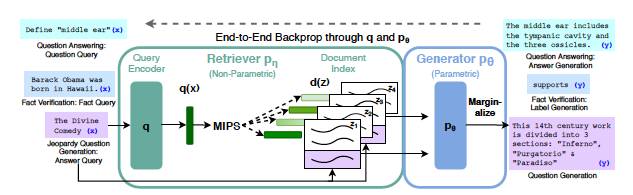
RAG
정의
대형 언어 모델(LLMs)이 외부 컨텍스트를 활용해 환각(hallucination) 현상을 줄이고 정확도**를 높이는 기술
- Retrieval (검색 단계)
- 사용자의 질문(query)을 기반으로 외부 지식 소스에서 추가적인 컨텍스트를 검색
- 외부 지식 소스는 여러 정보 조각과 그에 해당하는 벡터 임베딩을 저장
- 검색 시점에 사용자 질문은 동일한 벡터 공간에 임베딩되고, 가장 가까운 데이터 포인트를 계산하여 유사한 컨텍스트를 검색
- Augmentation (증강 단계)
- 사용자 질문과 검색된 추가 컨텍스트를 사용해 프롬프트 템플릿을 보강
- Generation (생성 단계)
- 보강된 프롬프트를 기반으로 더 사실적이고 정확한 답변을 생성
- 이 과정은 단순히 사용자 질문만을 사용했을 때보다 더 높은 정확도를 제공
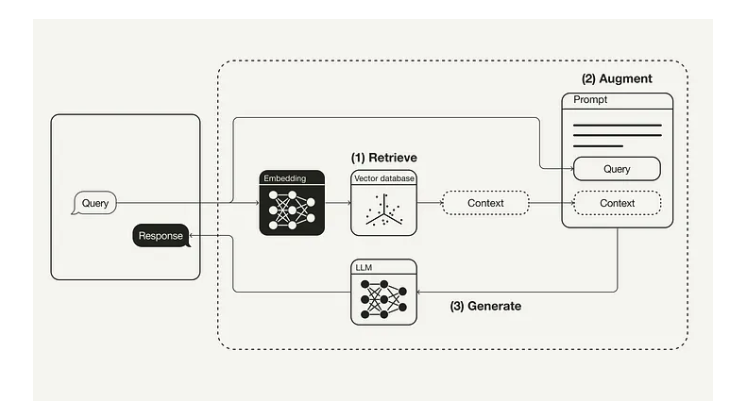
Retrieval-Augmented Generation forKnowledge-Intensive NLP Tasks
- RAG 모델에서 파라메트릭 메모리는 사전 학습된 seq2seq 모델이고, 비파라메트릭 메모리는 사전 학습된 신경 검색기(neural retriever)를 통해 접근할 수 있는 Wikipedia의 밀집 벡터 인덱스
- 두 가지 구조를 비교하며, 하나는 전체 시퀀스에 동일한 검색 결과를 사용하는 방식이고, 다른 하나는 토큰별로 다른 검색 결과를 사용하는 방식

LangChain
LangChain은 대규모 언어 모델(LLM)을 기반으로 애플리케이션을 구축하기 위한 프레임워크
- LLM을 기존 데이터 소스(데이터베이스, 문서 등)와 통합하거나, 사용자 정의 워크플로를 구성
- LangChain은 주로 RAG와 같은 LLM 기반 기술과 결합하여 정보를 검색하고 생성하는 데 자주 활용
참고자료

개발자를 위한 첫시작