seq 2 seq 는 2014년 등장해 비약적인 성능 향상을 보여주어 큰 관심을 끌었고, 핵심적인 LSTM Encoder - Decoder 구조가 Transformer 와 같은 아키텍쳐에도 활용되고 있는 획기적인 아이디어 입니다!
함께 공부해 보아용!
Introduction & Abstract
seq 2 seq 는 기본적으로 문장과 같은 연속형 데이터(sequencial data) 를 효과적으로 처리하기 위해 등장한 녀석임.
입력 데이터를 sequence의 형태로 받고, sequence의 형태로 내뱉는.
가장 간단하고 직관적인 예시로, 기계번역이 있음
🔺 나는 너를 사랑해 -> I Love You
이처럼 문장을 넣어, 문장이 나오는 형태의 Task 를 대표적인 예시로 들 수 있음
Seq2Seq 는 딥러닝 기반의 접근인데, 그 이전의 전통적 모델들 그리고 Seq2seq 이전의 딥러닝 기반 모델들 은 어떻게 이런 문제들을 다뤘을까? 그걸 먼저 살펴보자
전통적 언어모델
- 방대한 양의 언어 데이터베이스가 기반
- 어떤 문장이 input 으로 들어왔을 때, 그 문장을 tokenize 함
ex) 나는 사과를 먹었다 --> 나는 , 사과를 , 먹었다- 데이터 베이스를 기반으로, 확률이 높은 다음 token 을 선별
- 연쇄법칙이 활용됨 : 데이터베이스에 없는 문장이 엄청나게 많았을 것..! -> N-gram 으로 어느정도 해결했었음 (근처에 있는 토큰만 생각하여 확률 추출)
연쇄법칙 :
ex) P(나는 사과를 먹었다) = P(나는) x P(사과를|나는) x P(먹었다|나는,사과를)
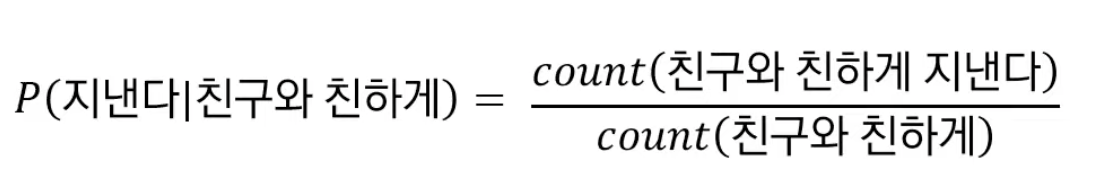
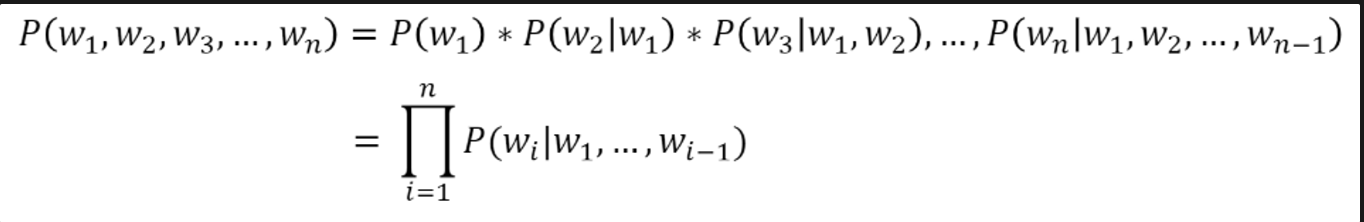
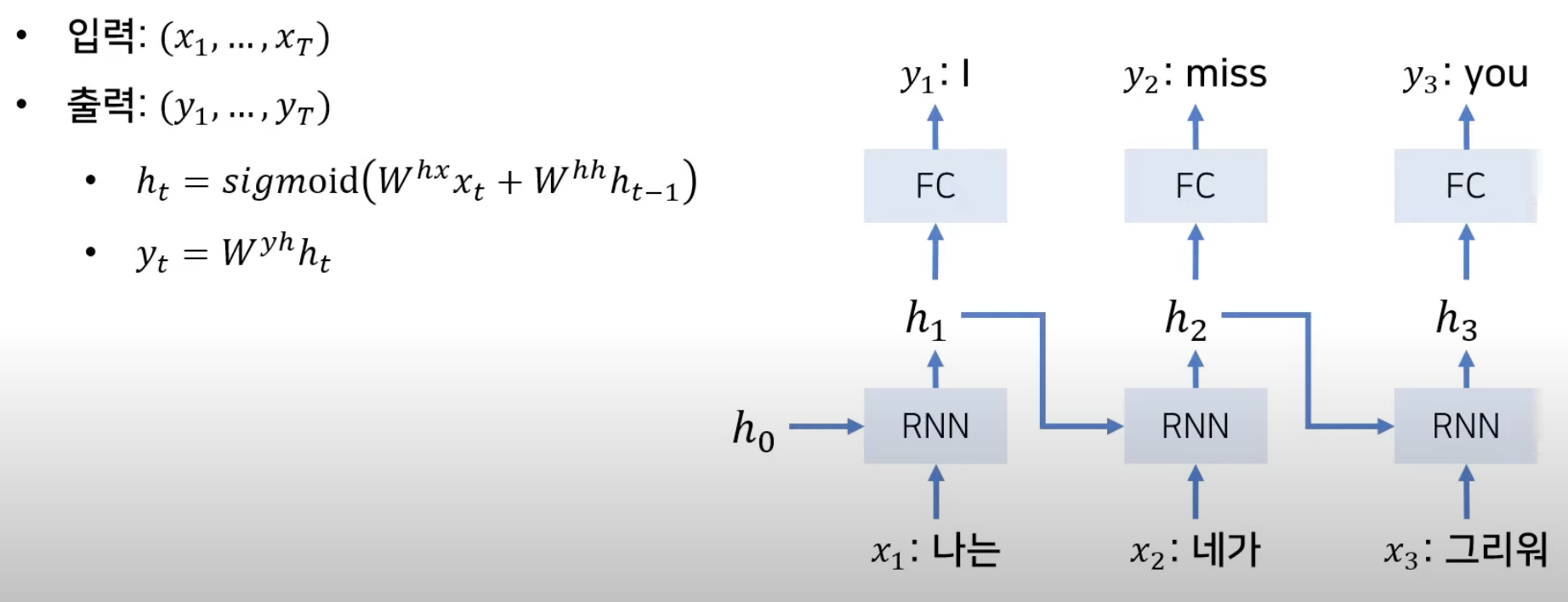
RNN 기반 언어모델 (Seq2seq 이전)
ex) 논문에서 말하는 DNN 등 (speech recognition 등의 task에서 효과적)
- Recurrent Network 를 활용하여, 이전 input 으로부터 문맥벡터를 추출하고, 그걸 다음 네트워크에 전달하는 방식
- 가중치는 전단계 (t 일때, t-1 번째) 의 것에 영향을 받으므로, 마지막 문맥벡터는 수학적으로 모든 sequence 의 정보를 함축하고 있음.
- 입출력의 사이즈가 동일하다는 가정하에 진행
- 매번 Input이 들어갈 때마다 번역 결과가 나오게 되면, 정확한 번역이 진행되지 않을 수 있다는 문제 존재
(저자들의 main task가 기계번역이었으므로 위와 같이 말합니다!)
About Model
그렇다면, Seq2seq Learning 은 무엇이 다를까?
현재까지 RNN 기반 모델의 단점은,
1. 입출력 사이즈가 동일하다는 가정
2. Token별로 나오는 output 의 정확도에 대한 의문
위 두가지 이다.
저자들은 해당 문제를 Encoder - Decoder 구조를 활용하여 해결한다.

Encoder
- Token 별로 나오는 output 은 해당 output 이 문맥벡터를 정확히 내포하고 있는지 등에 대한 의문으로 정확성의 문제가 있어보임.
- 그 Encoder는 input 으로부터 고정된 크기의 문맥벡터를 하나 가져옴
- 위에서 설명했던 RNN 구조의 마지막 문맥벡터 는 수학적으로 전체 sequence 의 정보를 함축하고 있어야 한다고 했다!
- 이때의 고정된 크기의 context vector V 는 그것을 말한다.
Decoder
- Decoder 는 해당 V 를 기반으로 번역 결과를 추론함.
- 이때 Decoder 와 Encoder의 parameter 는 서로 다르게 학습된다.
( 서로 다른 모델이기 때문에 Encoder는 입력 sequence와 관련된 도메인을 학습하고 Decoder는 출력 sequence와 관련된 도메인을 따로 학습 )
More about Model
기본적인 구조를 알았으니, 조금 더 들어가보자.
추가로 핵심적으로 이해할 것 한 가지는 LSTM 이다.
About LSTM (추가예정)
본 논문의 저자는, LSTM 을 활용하여 Seq2Seq 구조를 구성했다.
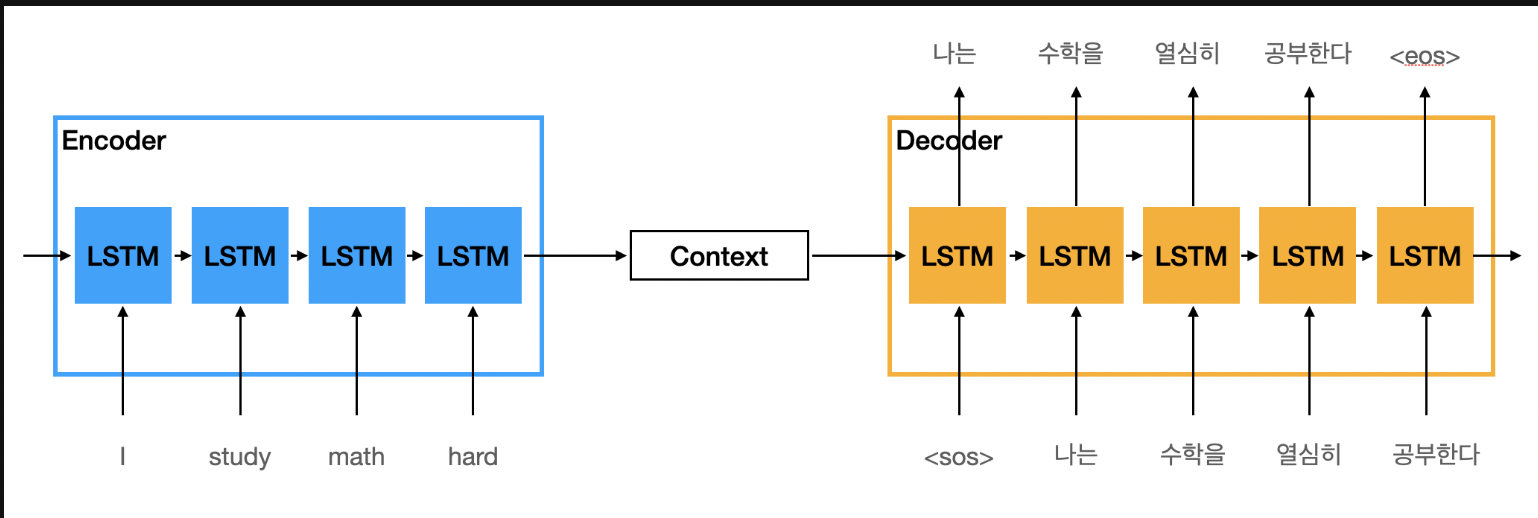
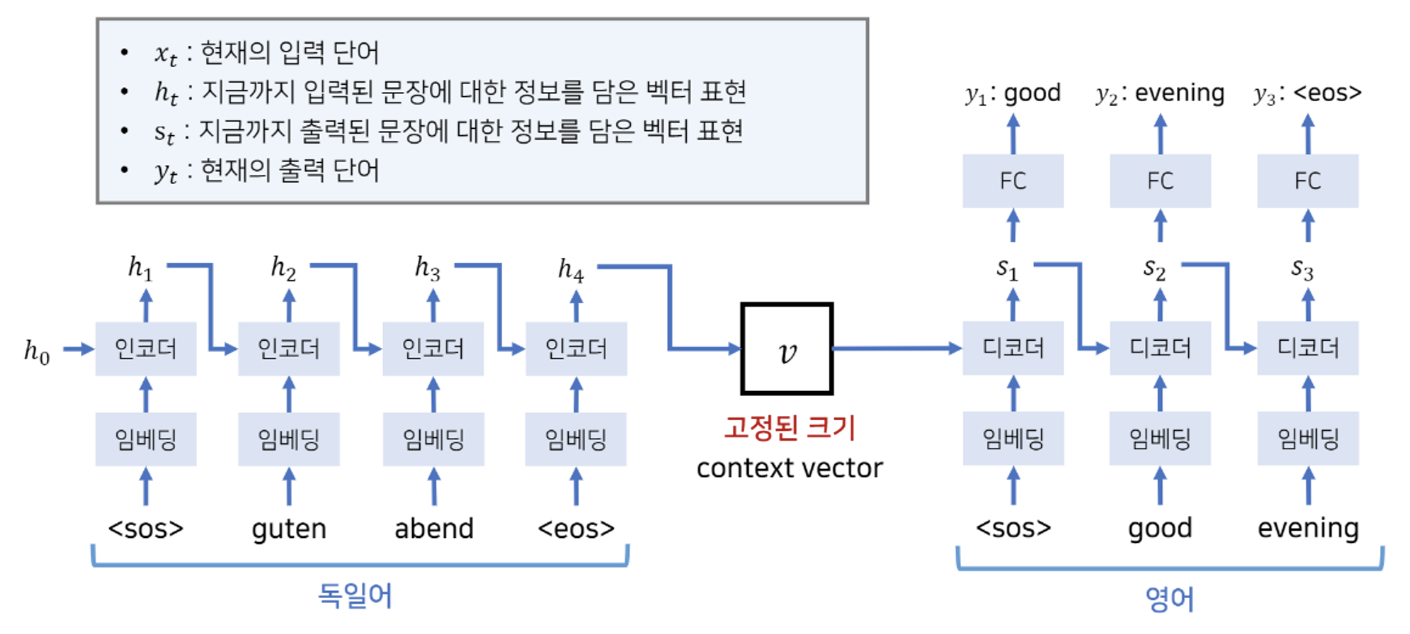
위 두 사진을 보면, 구조를 어느정도 심층적으로 알 수 있다.
Encoder 와 Decoder 에서 서로 다른 심층 LSTM 을 사용하여 서로 다른 가중치를 학습시킨다
- 여기서 Embedding 은 입출력 차원의 크기가 너무 큰 것을 대비하여 시켜주는 것이라고 보면 된다. (그냥 one - hot 으로 하면 차원이 너무 커질 경우가 존재하기 때문)
또 하나 신기한 점은, 수학적으로는 연계법칙에 의해 큰 차이가 없어야 하지만, input seq의 순서를 거꾸로 하여 학습시켰더니 성능 향상이 일어났다는 것이다!
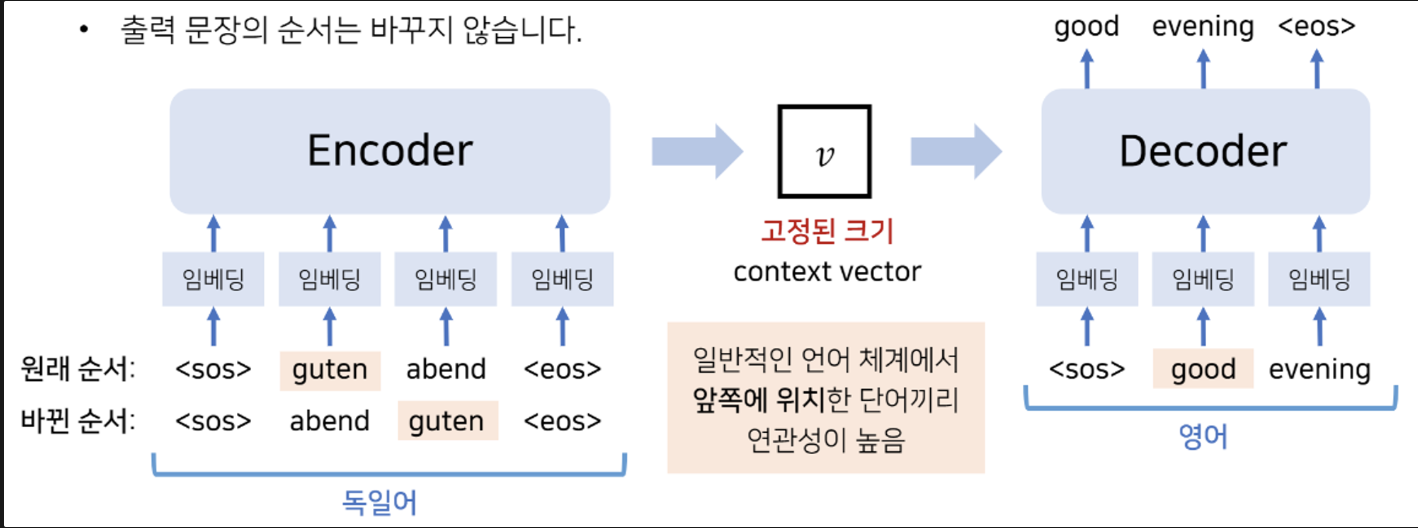
- 아무래도, Encoder 의 context vector 가 전체 seq 를 골고루 함축하기 보다는 output (vector) 에서 가까운 token 의 가중을 크게 한 것 같다.
- 그 말은 즉슨,
- 적어도 기계번역 task 에서는 앞 token 의 중요도가 높다는 것
- 아직은 Long - term dependency (장기의존성) 문제가 존재한다는 것
이후 Attention is all you need 에서 더 발전된 내용을 함께 살펴보자!
References
