Background
기존 attention 기반 알고리즘들은 context와 query 단어간의 연관성을 계산하고 가중합을 통해 요약벡터를 생성한다. 요약벡터로 압축되면서 세부적인 정보 손상이 발생한다.
또한 이렇게 요약된 벡터가 다음 timestep에 입력으로 들어가 은닉층의 출력에 영향을 미쳐 attention 계산에 영향을 주어 오류가 누적되는 문제 발생한다.
-> memory less, context-query 양방향 attention을 통해 해셜
key idea
1. character embedding layer: 각 단어들마다 character 단위로 임베딩 벡터 생성
2. word embedding layer: glove를 사용해서 고정된 길이의 임베딩 벡터 생성, two layer highway network를 사용하여 결합 진행
-> X(context): dXT, Q(query): dXJ
3. contextual embedding layer: bilstm을 통해 양방향 임베딩 생성, 양방향이기에 차원이 d -> 2d가 된다.
-> H: 2d X T, U: 2d X J
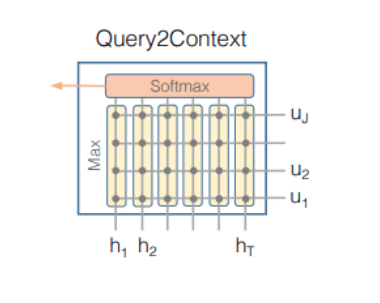
4. attention flow layer: context, query 벡터를 연결 및 결합, 기존 attention layer과 다르게 각 timestep에서 입력 벡터와 attention 벡터를 결합하여 다음 modeling layer에 전달함으로서 정보손실을 줄인다.
attention 벡터를 생성할 때, 양방향으로 생성한다.
4-1. context to query attention
아래 그림과 같이 t번째 context word에 대한 query word에 대한 attention weight 계산(당연히 softmax를 통해 합을 1로 만들어야) attented vector U'는 [U'1, U'2, ..... U'T]가 되어 2d X T가 된다.
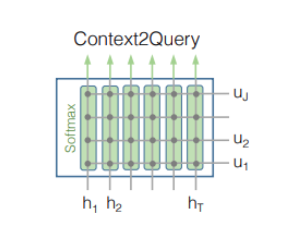
4-2 query to context attention