Background
object detection을 수행할 때, 컴퓨터 자원을 낮추고 다양한 크기의 객체를 인식하기 위하여 FPN을 고안
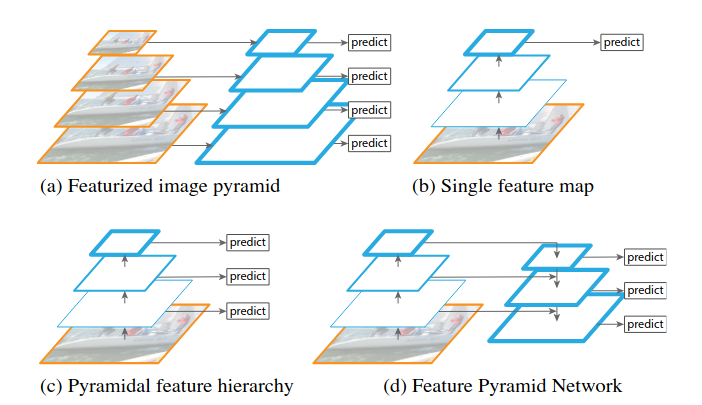
기존 방식에서 (a)는 입력이미지를 resize하여 네트워크에 입력하여 feature map을 생성하는 방법으로 추론 속도와 메모리 측면에서 비효율적, (b)는 하나의 입력 이미지에 대해 단일 scale feature map을 생성, 단일 scale에 대한 feature만 추출하므로 성능이 좋지 않다. (c)는 convlayer마다 featuremap을 추출하는 방법으로 서로 다른 scale에 대한 feature map을 생성하므로 성능이 좋으나, feaure map 간의 해상도 차이 때문에 semantic gap 문제 발생, 이를 해결하기 위해 (d)고안
Key Idea
1. Bottom up pathway
각 convlayer마다 해상도가 1/2로 줄어들면서 featuremap을 추출 ex) 512(c1) -> 256(c2)
2. Top down pathway
각 level의 featuremap에 1X1 conv을 통해 채널수를 256-d로 만들어줌, 그후 next level의 featuremap을 upsampling을 통해서 해상도를 2배로 만들어주고 그 후, elementwise addition을 통해서 요소별로 더해준 다음 3X3을 통해서 새로운 featuremap 생성 ex) (c2 + upsampled c3) 3X3 conv -> p2
고해상도 featuremap은 초기 layer의 featuremap이니까 low level feature를 담고 있지만 객체의 위치정보를 비교적 정확하게 보존하고 있는데 이를 저해상도 map에 더해 위치정보와 low-level, high level feature를 모두 담고 있는 better feature map 생성 가능
inspiration
resnet과 비슷한 듯 하면서도 뭔가 신박 이 concept 활용가능할지도
