Abstract
이 논문은 단어들의 벡터 표현을 계산하는 두 개의 기발한 모델 구조를 제안한다. 이 벡터표현들의 성능은 단어 유사도 task를 잘 수행하느냐로 측정되며 결과는 이전의 가장 좋은 성능을 보였던 다른 신경망을 사용한 기술들과 비교한다. 적은 연산 비용으로 정확도에서 큰 발전을 관찰했다고 한다. 16억개의 단어 데이터셋을 불과 하루도 안되서 단어벡터들을 학습해냈다. syntatic semantic 단어 유사도 테스트에서 최첨단의 성능을 보인다고 한다.
Introduction
많은 기존의 NLP 기술들은 단어를 원소적 요소로서 취급하여 단어 사이의 유사도를 측정할 수 없어 vocabulary의 인덱스 역할에 국한되어 있었다. 이러한 선택에는 여러 이유가 있었는데 단순성, 견고성, 많은 양의 데이터셋이 있는 단순한 모델이 적은 데이터를 가진 복잡한 모델보다 더 성능이 좋다는 관찰 때문이었다. 예시로 통계적 언어 모델링을 이용한 N-gram 모델이 사실상 가능한 모든 데이터를 학습하여 좋은 성능을 보였다. 그러나 간단한 기법들은 다양한 업무를 하는데에 한계가 있다. 예로 자동 음성 인식 분야나 기계번역에서 충분한 데이터가 존재하지 않아 뚜렷한 발전을 이루지 못하고 있다. 최근 머신러닝기술의 발전으로 인해 더 큰 데이터셋으로 더 복잡한 모델을 학습시키는게 가능해졌다. 아마 가장 이것의 가장 성공적인 예시가 단어의 분산표현을 사용하는 것일 것이다. 예를 들어 신경망 기반 언어 모델들은 N-gram 모델들의 성능을 뛰어넘는다.
Goals of the Paper
이 논문의 주요 목적은 수십억개의 단어들로 이루어진 대규모 데이터셋으로 부터 좋은 성능의 단어 벡터들을 학습시키는데 사용되는 기술을 소개하기 위함이다. 이전의 제안되었던 모델들은 수백만개의 50-100차원 언어벡터들을 성공적으로 훈련한 사례가 없었다. 비슷한 단어들끼리 가까울 뿐만 아니라 단어들이 유사도을 다양한 차원으로 측정할 수 있는 기술을 사용한다. 단어표현의 유사도는 단순한 구문론적 일관성으로 넘느낟. 단어 벡터들 사이의 연산을 수행하는 단어 오프셋 기술은 과 같은 형태로 수행된다. 이 논문에서는 단어들 사이의 선형적 일관성을 보존하는 새로운 모델구조를 개발하여 벡터 연산의 정확성을 최대화하고자 한다. 여기서 구문론적 의미론적 일관성을 측정하기 위한 테스트셋을 만들어 그러한 일관성이 높은 정확도로 학습됨을 보인다. 훈련시간과 정확도는 훈련데이터와 단어 벡터들의 차원에 따라 어떻게 달라지는지 논의한다.
Previous Work
연속적인 벡터로 단어를 표현하는 것은 오랜 역사를 지녔다. NNLM을 이용한 매우 유명한 모델구조는 선형 투사층과 비선형 은닉층이 있는 피드포워드 신경망은 단어 벡터 표현과 통계적 언어 모델을 결합하여 사용한다. NNLM의 다른 흥미로운 구조로는 하나의 은닉층을 가진 신경망을 통해 단어 벡터들이 처음 학습된다. 이 단어 벡터들은 NNLM을 학습하는데 사용된다. 즉 단어벡터들이 완전한 NNLM이 만들어지기 전에 학습된다. 단어벡터들이 NLP 활용분야를 발전시키고 단순화할 수 있다는 것은 나중에 알려졌다. 이 논문에서는 후자의 방식을 택해 워드 임베딩을 효율적으로 수행한다.
Model Architecture
LSA나 LDA과 같이 단어의 연속적 표현을 측정하는 다양한 모델들이 제안되어왔다. 이 논문에서는 LSA나 LDA보다 성능이 좋고 비용적으로 효율적인 신경망을 통해 학습된 단어의 분산표현에 집중한다. 다양한 모델구조들을 비교하기 위해 먼저 모델을 훈련하기 위해 필요한 파라미터의 수를 연산복잡도로 정의한다. 연산적 복잡도를 최소화하면서 정확도를 최대화하는 것이 목적이다. 연산복잡도는 다음과 같다.
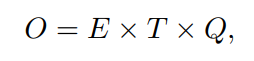
E는 훈련 epoch수, T는 훈련 데이터셋에서의 단어의 수, Q는 모델 구조에 따라 결정된다. 보통 E는 3 ~ 50, T는 10억까지이다. 모든 모델들은 통계적 경사하강법과 역전파를 사용하여 훈련된다.
Feedforward Neural Net Language Model(NNLM)
확률론적 피드포워드 선경망 언어 모델은 입력층, 투사층, 은닉층, 출력층으로 구성되어있다.
-
입력층에서 N개의 이전 단어들은 1 of V 원핫인코딩된다 (V는 총 단어집합의 크기).
-
투사층에서는 공유되는 투사 행렬을 사용하여 N X D의 차원성을 가지는 투사층 P로 투사된다. 투사층의 연산은 복잡도는 비교적 낮다.
-
NNLM에서는 투사층의 밀집될수록 투사층과 은닉층 사이의 연산이 복잡해진다. N이 10일 때, 보통 투사층의 크기 P는 500에서 2000이고 은닉층의 크기 H는 보통 500에서 1000사이이다. 출력층은 모든 단어에 대한 확률분포를 계산한다.
즉 훈련 한번의 연산 복잡도는 다음과 같다.
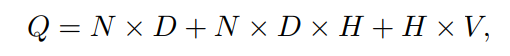
H X V가 연산에서 많은 부분을 차지하지만 이것을 줄이기 위해 계층적 소프트맥스를 이용하여 연산복잡도를 H x 로 낮추어 N X D X H가 연산의 대부분을 차지하게 된다. 이 모델에서는 Huffman binary Tree로 표현되는 단어집합에 계층적 소프트맥스를 사용한다. 허프만 트리는 자주 등장하는 단어에 짧은 binary code를 할당하여 츌력층에서 평가하는데 필요한 출력 유닛의 수를 까지 낮춘다.
Recurrent Neural Net Language Model(RNNLM)
RNN기반 언어모델은 문맥길이를 특정해야 하는 등의 NNLM의 한계를 극복하기 위해 제안되었다. RNN은 투사층 없이 입력층, 은닉층, 출력층만 존재한다. 재귀 행렬의 특별한 점은 time-delayed 연결을 통해 은닉층이 자기 자신을 연결한다는 점이다.
