NLP 논문 리뷰
1.NLP 논문 리뷰 및 구현

앞으로 유명한 NLP논문들을 읽고 리뷰한 후 구현해볼 생각이다.
2023년 12월 28일
2.Efficient Estimation of Word Representations in Vector Space 논문 리뷰
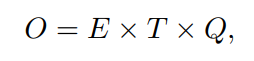
이 논문은 단어들의 벡터 표현을 계산하는 두 개의 기발한 모델 구조를 제안한다. 이 벡터표현들의 성능은 단어 유사도 task를 잘 수행하느냐로 측정되며 결과는 이전의 가장 좋은 성능을 보였던 다른 신경망을 사용한 기술들과 비교한다. 적은 연산 비용으로 정확도에서 큰 발
2024년 3월 12일
3.Mamba: Linear-Time Sequence Modeling with Selective State Spaces
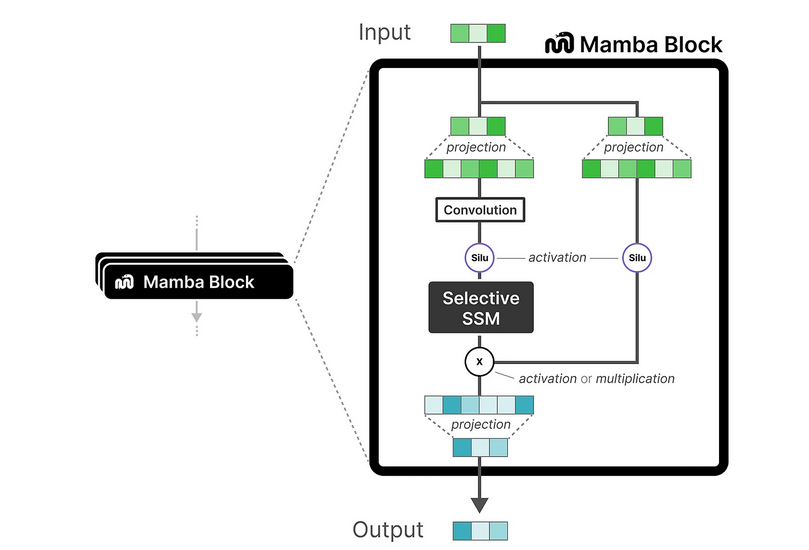
background Transformer는 시퀀스의 길이가 길어질수록 computation complexity가 0(n^2)로 증가하여 비효율적이다. 이를 해결하기 위해서 mamba라는 아키텍처가 고안되었다. mamba를 이해하기 위해서는 그 이전에 고안된 SSM 관
2025년 2월 24일