background
Transformer는 시퀀스의 길이가 길어질수록 computation complexity가 0(n^2)로 증가하여 비효율적이다.
이를 해결하기 위해서 mamba라는 아키텍처가 고안되었다.
mamba를 이해하기 위해서는 그 이전에 고안된 SSM 관련 논문들을 알아야 한다.
Hippo
Hipp0는 간단히 말해서 input을 적절한 polynomial space로 근사하는 아키텍처이다.
즉 시간에 따라 달라지는 input f(t)를 projection 시키고 coeffcientc(t)로 매핑한다. 이때 다항식 기저는 legendere 방정식과 lanuerre 방정식을 measure로서 선택할 수 있다.
- translated Legendre (LegT)
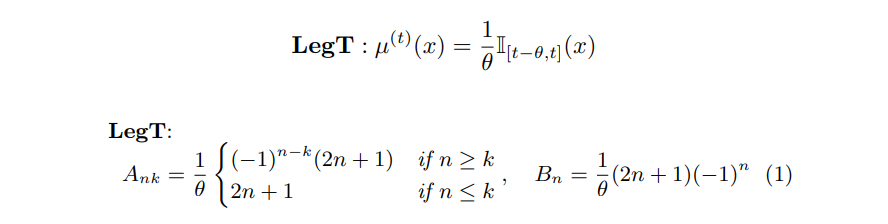
- translated Laguerre (LagT)
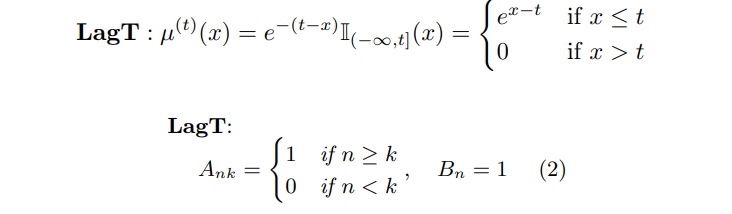
논문에서는 Legendre를 주요 measure로 선택, A, B를 다음과 같이 정의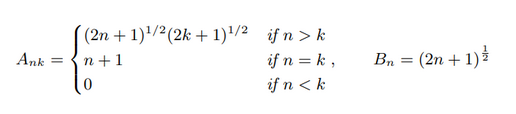
위에서 정의한 A, B를 통해 아래식을 푼다.
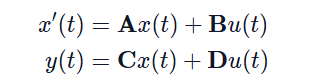
y(t)는 변환한 다항식 기저공간에서의 좌표(coeff)인 c(t)를 말한다.
lssl
hippo는 고정된 A, B, C, D를 사용하는데 이는 모델의 유연성을 떨어트림. 따라서 고정되지 않은 A, B, C, D를 학습 파라터로 설정하고 훈련시킨다. 즉 A, B, C, D를 각각 linear layer로 두고 state space model을 디자인하였다. 이를 통해 A가 모델 성능에 중요한 역할을 한다는 것을 알아내었다.
lssl은 A, B, C, D를 일종의 커널형태로 정의하는데 이때 시간의 길이에 따라서 커널의 크기가 커지고 space complexity도 커지기 때문에 현실적으로 불가능하다는 문제가 있었다.
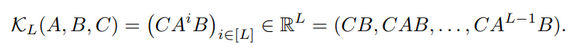
s4
lssl의 문제점을 해결하기 위해 ssm관점에서 효율적으로 연산하는 방법을 고안하였다.
ssm에서 연산 복잡도가 커지는 주 요인은 A행렬이 반복되는 곱셈 연산인데 이를 해결하기 위해
A, B, C를 계산할 때 대각화를 통해 연산량을 줄이는 형태로 변환하는 방법을 제안하였다.

그러나 위 방법은 numerical issue가 발생하므로 이를 해결하기 위해 NPLR구조를 제안한다.
NPLR는 저랭크 행렬 P, Q를 통해서 모델의 유연성과 표현력을 추가하여 수치적 불안전성을 해결한다.
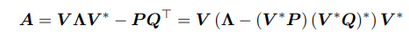
deeps4layer은 이러한 NPLR을 Hippo 행렬에 적용하여 P, Q, B, C, diagonal_matrix 총 5개의 파라미터를 학습한다.
Mamba
inspiration
기존의 SSM은 시간에 따라 변하는 규칙 자체는 고정되어 있으므로 입력값에 따라 연산이 유동적이지 못함.
-> selective copying, induction heads 2개의 task를 특히 수행 못함.
즉, S4는 고정된 파라미터와 이산화 방식을 사용하여 모든 시퀀스에 동일한 연산을 적용하고, 그 결과로 일정한 recurrence 또는 convolution을 수행한다는 것이다.
mamba에서는 이러한 문제들을 해결하기 위해 s4 + selection인 s6구조를 제안함.
s6에서는 s_B(x), s_C(x), sΔ(x)같은 함수를 정의하여 x에 따라 B, C, Δ가 동적으로 변화하게 하였다.
sB(x): 입력 x에 따라 (B, L, N) 차원으로 변환한다. S4에서 모든 시퀀스가 동일한 B 매트릭스를 사용했던 것과 달리, 이제는 각 시퀀스마다 다른 B가 적용
sC(x): 역시 입력에 따라 (B, L, N) 차원으로 변환
sΔ(x): 입력에 따라 시간 간격을 나타내는 Δ 역시 (B, L, D)로 변환
이산화 연산 또한, 변환된 Δ를 사용하므로 더 복잡한 연산을 가지게 된다.
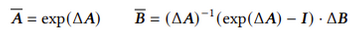
이산화 과정은 위와 같고 여기서 ΔA,ΔB는 다음과 같이 계산 가능하다.
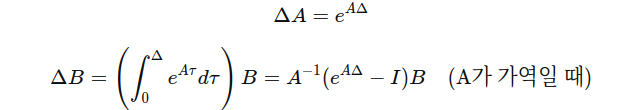
또한 A를 효율적으로 처리하기 위해서 NPLR을 사용하여 다음과 같이 나타낼 수 있다.
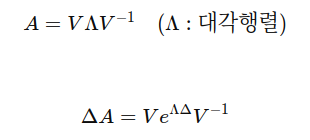
Selective State Space Model을 효율적으로 구현하기 위하여 GPU 등을 활용하여 메모리 사용과 계산을 최적화하는 방법에 대해 제안한다.
selective scan과 hardware-aware-state expansion에 대해서 제안하는데 Selective Scan은 시퀀스 내에서 중요한 정보를 선택적으로 처리하고, 불필요한 정보는 무시하는 과정이고 하드웨어-인식 상태 확장 (Hardware-Aware State Expansion)은 하드웨어 효율성을 고려하여 최적화하는 방법이다.
현대 GPU는 고속 메모리(SRAM)와 대용량 메모리(HBM)를 가지고 있는데 선택적 SSM에서는 이러한 메모리 계층을 적절히 활용하여, 자주 사용되는 중요한 데이터는 고속 메모리에 저장하고, 덜 중요한 데이터는 대용량 메모리에 저장함으로써 계산 속도와 메모리 사용을 최적화한다.
GPU의 주요 병목 현상은 SRAM과 DRAM 사이의 Copy and PASTE에서 발생하는 것을 확인하였고, 저자는 이러한 memory IO 로 발생하는 병목현상을 줄이기 위하여 kernel fusion을 사용하였다.
또한 Selective Scan 계산을 병렬로 처리할 수 있도록 설계하여, 시퀀스의 여러 시점을 동시에 처리하는 방식인 Scan Operation 제안한다.
병렬 스캔 알고리즘은 입력 시퀀스를 동시에 처리하면서 선택적으로 필요한 정보만 처리하고 나머지는 건너뛰는 방식으로 다음과 같이 먼저 계산할 수 있는 것은 미리 계산해둬서 계산 속도를 향상시키는 방법이다.

위와 같은 새로운 sssm을 이용해서 mamba아키텍처를 구현한다.
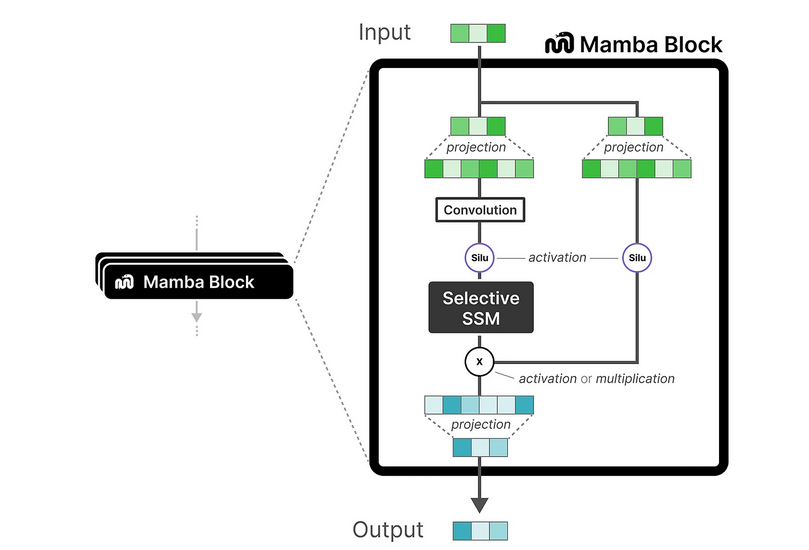
출처) https://maartengrootendorst.substack.com/p/a-visual-guide-to-mamba-and-state#footnote-anchor-3-141228095
