🤔 이번 시간에는 Inductive Learning과 Transductive Learning의 차이점에 대해 소개를 해보려고 한다.
Inductive Learning을 직역하면 귀납적 학습, Transductive Learning은 ... 직역조차 애매하다.
단어만 보고 그 개념을 유추하기 어려운 이 두 단어는 아마 영어 원서로 된 책이나 자료로 머신 러닝을 공부하다보면 자주 보았을 것이다. 하지만 논문에서 조차도 두 개념을 직관적으로 설명해주지 않는다.
그래서 이번 시간에는 머신러닝에서 두 학습 방식에 대한 개념과 그 차이에 대해 쉽게 소개해보려고 한다.
🚬 글 읽기 귀찮아도 아래 3번에는 그림 예시가 나오니... 화이팅... 😉
📝 단어 정의 (Referenced by Wikipedia)
📌 Transduction
In logic, statistical inference, and supervised learning, Transduction is reasoning from observed specific (training) cases to specific (test) cases.
📌 Induction
In contrast, induction is reasoning from observed training cases to general rules, which are then applied to the test cases.
Inductive Learning은 전통적인 지도 학습 (supervised learning)의 방식과 같다. 그 방식을 보자면, 우선 머신러닝 모델을 설계한 뒤 오직 training dataset만을 사용하여 분류 혹은 회귀를 위한 규칙(rule)을 스스로 추론한다. 즉, 관측된 (observed) 데이터는 training dataset 뿐이며 지도 학습을 통해 training dataset 분포에 최적화된 모델 파라미터를 계산한다. 이후 모델 학습이 끝난 뒤 unlabeled testing dataset의 label을 추론하는 이 지도 학습 방식이 바로 대표적인 Inductive Learning의 개념이다.
이에 반해 Transductive Learning은 학습 시 사전에 미리 training dataset 뿐만 아니라 testing dataset도 알고 있는 (관측한) 상태이며, testing dataset의 label을 알지 못하지만 학습이 진행되는 동안 labeled data (training dataset)의 특징 공유 혹은 전파, 데이터간의 연관성, 특징 패턴 등 추가적인 정보를 활용함으로써 testing dataset의 label을 추론한다.
대표적인 Transductive Learning 기법으로는 transductive SVM (TSVM), graph-based label propagation algorithm (LPA), 그리고 node-classification 기반 graph convolutional neural networks (GCN)의 feature propagation 기법 등이 있다. 참고로 준지도 학습 (Semi-supervised Learning)과 비슷한 점이 많다.
📝 차이점 정리
이제 어느정도 Transductive Learning과 Inductive Learning의 정의에 대해 이해가 되었다면 두 학습 기법의 차이점에 대해 자세히 알 필요가 있다.
다시 한번 강조하자면, 두 기법의 가장 큰 차이는 Transductive Learning에서 모델 학습 시 training set과 testing set 둘 다 사용하는 반면, Inductive Leaning에서는 모델 학습 시 training set만 사용하며, 이후에 우리가 관측한 적 없던 새로운 testing dataset에 학습된 모델을 적용한다.
Inductive Learning에서는 새로운 데이터의 label을 추론할 수 있는 모델 (predictive model)을 생성하며, 이 때 새로운 데이터를 관측했다고 해서 학습 자체를 꼭 다시 할 필요는 없다. 왜냐하면, 이미 학습된 모델을 새로운 데이터에 적용하여 그 데이터의 label을 추론하면 되기 때문이다.
💥 주의 사항
분류 문제를 예로 들자면, 학습 시 사용한 데이터가 개와 고양이 뿐이었고, 새로 관측된 데이터가 개 또는 고양이에 관련된 데이터일 때 학습을 다시 할 필요가 없다는 것이다. 만약 새로 관측한 데이터가 코끼리 관련 데이터이고 코끼리도 분류할 수 있으면 좋겠다라고 한다면 코끼리 관련 데이터와 함께 다시 모델을 학습해야 하는건 당연하다.
반면 Transductive Learning은 predictive model을 생성하지 않는다. 만약 새로운 데이터가 관측이 된다면 해당 데이터의 label을 예측하기 위해 labeled data와 같이 모델을 처음부터 다시 학습해야 한다.
따라서 Transductive Learning 같은 경우 새로운 unlabeled 데이터가 자주 관측되는 케이스에서 cost가 비쌀 수 있다. 반면, Inductive Learning 같은 경우 predictive model을 초기에 생성해두기 때문에 더 적은 cost로 빠른 시간안에 새로 관측된 데이터의 label을 예측할 수 있다. 참고로, 여기서 cost는 컴퓨팅 파워, 시간, 연산량 등을 의미함
TABLE 1. Inductive Learning vs Transductive Learning |
|---|
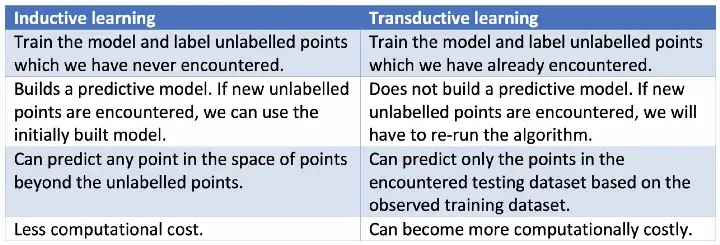 |
위 그림이 Inductive Learning과 Tranductive Learning의 차이를 잘 정리하여 보여주는 것 같아 참조하였다.
📝 동작 예시
잘 참았다.. 앞으로는 그림 예시를 보면서 조금이나마 릴렉스하시길 🤗
Figure 1 |
|---|
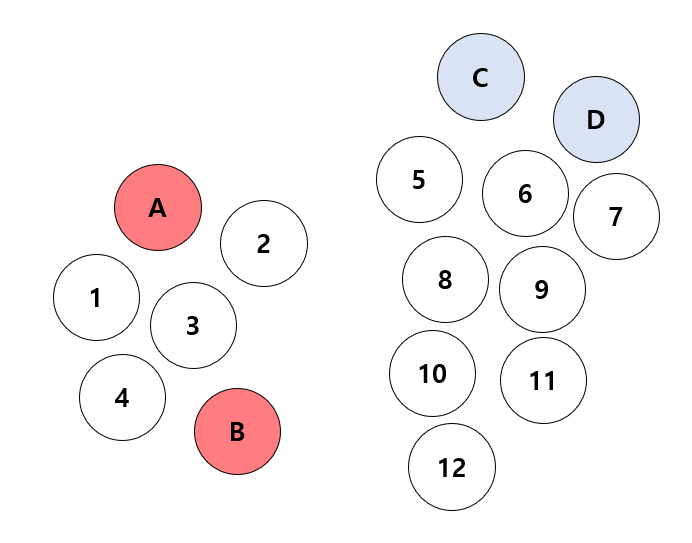 |
우선 위 그림 예시에서 labeled data (training data)는 A , B , C , D 이고 A 와 B 는 class red , C 와 D 는 class blue , 나머지 숫자들은 unlabeled data (testing data) 이다. 여기서 unlabeled data의 label을 추론해야 하는 상황일 때, Inductive Learning에서는 4개의 training data만을 사용하여 지도 학습 (supervised learning)을 수행한 후 학습된 예측 모델을 testing data에 적용하여 label을 추론하면 된다.
Figure 2 |
|---|
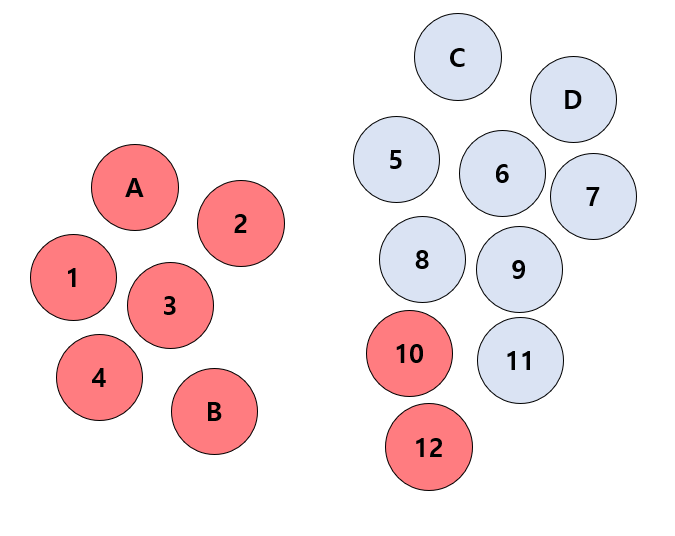 |
그러나 Inductive Learning 경우에서는 훈련 데이터가 턱 없이 부족하기 때문에 전반적으로 label을 예측하는 모델을 만들기 어려울 수 있다. 예를 들어, K neareast neighbor 방식을 적용한 경우, 숫자 10과 12는 C와 D보다 B와 더 가깝기 때문에 class red로 분류될 것이다.
여기서, 숫자 10과 12가 잘못 분류되었다고 말할 수는 없다. 하지만, 학습 데이터가 상당히 적기 때문에 10과 12가 class red로 분류된 것에 대해 우리는 당연하게도 신뢰할 수 없다.
Figure 3 |
|---|
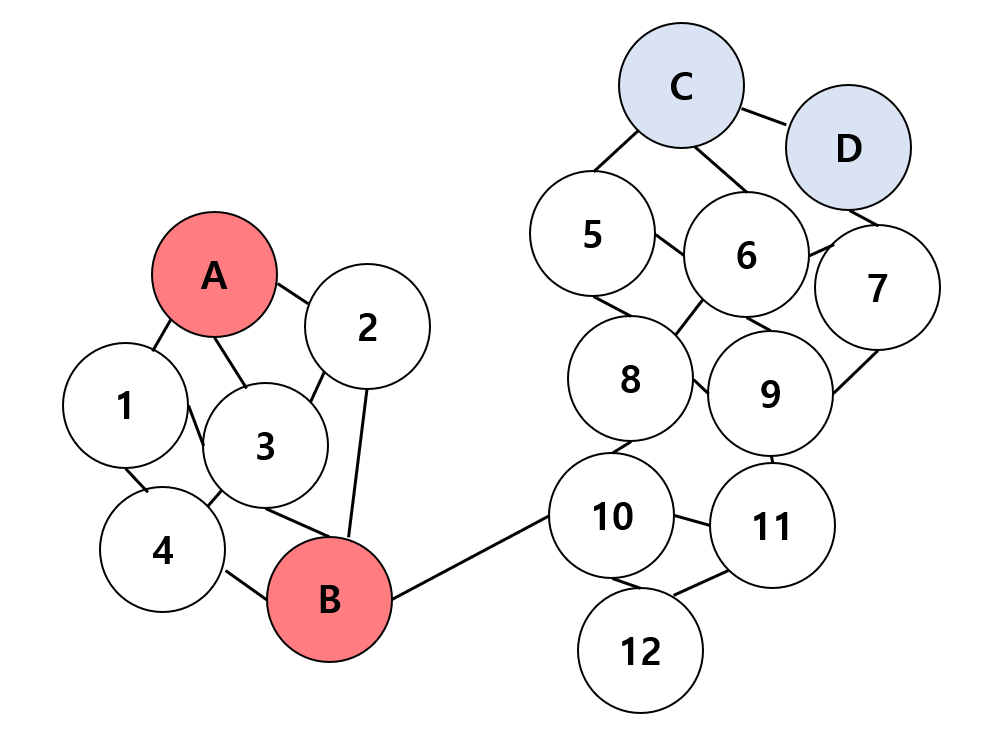 |
만약 위의 그림 3처럼 Non-Euclidean 공간상의 그래프 데이터에서 데이터 노드 간 엣지 정보가 추가되었다고 가정한다. 또한, 이 엣지는 가중치가 있으며 B와 10 간의 엣지 가중치는 매우 작고 나머지 엣지 가중치는 크다고 가정해본다. 이 때, 이 엣지와 엣지 가중치는 추가적인 연결성 정보를 제공해준다. 앞으로 이 추가 정보를 적극 활용해볼 것이다.
Figure 3 |
|---|
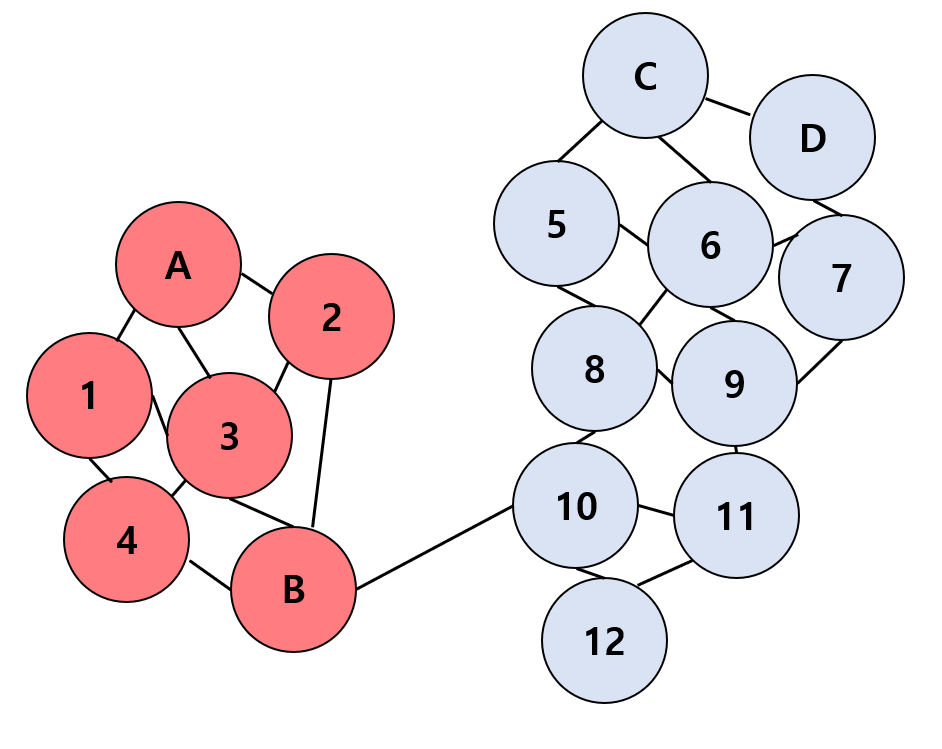 |
Inductive Learning에서는 이러한 엣지 추가 정보가 있다고 하더라도, 활용하기 어렵다. 왜냐하면 앞에서 언급했듯이, 우리는 학습 시 오직 Training dataset의 정보만 알 뿐, Testing dataset은 관측한 적 없기 때문이다. 반대로, Transductive Learning에서는 우리가 이미 Training dataset 뿐만 아니라 Testing dataset도 알고 있다. 다만, Testing dataset의 label만 모를 뿐, Testing dataset의 데이터 정보는 충분히 학습 때 활용할 수 있다. 여기서, 엣지 추가 정보까지 우리가 알고 있기 때문에 연결성에 기반하여 Training dataset의 label을 Testing dataset에 전파할 수 있다. (Graph-based label propagation algorithm, LPA) 이 예시에서의 접근법은 준지도학습 (Semi-supervised Learning) 방식이라고도 볼 수 있다. 그림 3과 다르게 이 때는 10과 12 노드는 class blue로 분류된다.
📌 핵심 포인트
Transductive Learning에서는 우리가 사전에 Testing dataset도 알고 있다는 점과, 엣지 정보와 같은 유용한 추가 정보를 활용할 수 있다는 점이 핵심이다. 만약, 사전에 알고있는 Testing dataset이 없다면 Inductive Learning 만 선택할 수 있다. (Inductive Learning에서는 predictive model을 생성하므로 새로운 데이터가 언제 관측되어도 상관없기 때문)
📔 마무리
간단한 예시들과 함께 Transductive Learning과 Inductive Learning의 차이와 각 방식의 개념에 대해 알아보았다. 현재 작성자 본인은 Graph Neural Network를 활용하여 Brain network에 관련된 연구를 수행하고 있기 때문에, 그래프 기반 예시를 들어 설명하였다.
예시와 별개로 두 방식의 개념은 변하지 않으니 이 글을 읽고 도움이 되었길 빕니다!
📜 References
[1] Transduction (machine learning) Wikipedia — https://en.wikipedia.org/wiki/Transduction_(machine_learning)
[2] Inductive vs. Transductive Learning — https://towardsdatascience.com/inductive-vs-transductive-learning-e608e786f7d
[3] V. Vapnik, "Transductive Inference and Semi-Supervised Learning" — https://pdfs.semanticscholar.org/5a8c/38e6aadc29fb995d5b9562df0c4365156256.pdf
