Forward Propagation
For this Multi layer perceptron(MLP) of a binary classification.
The enumerated forward propagation is like this.
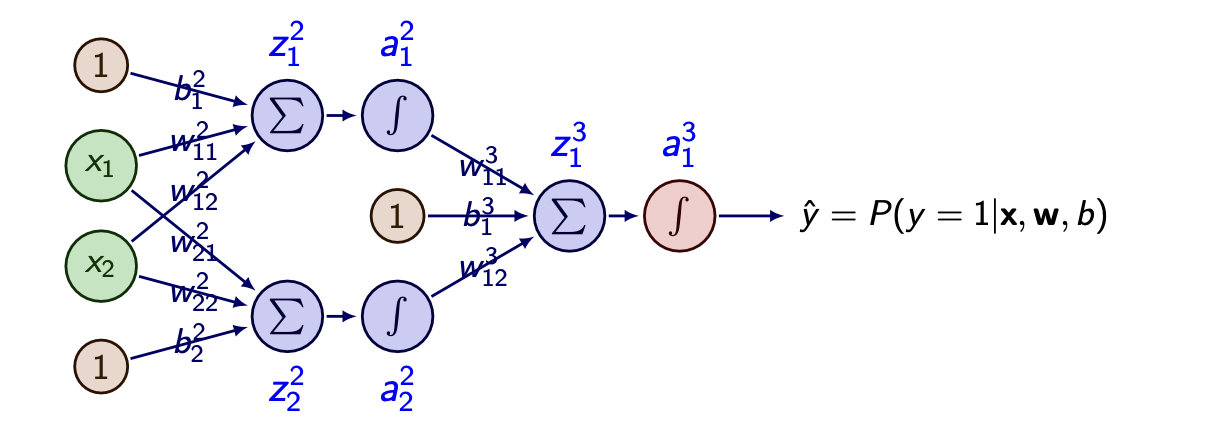
- input x // size (2,1)
- linear combination in hidden layer z[2] // size (2,1)
z[2]=W[2]x,(W=2×2matrix)
-
non-linearity function a[2] // size (2,1)
a[2]=tanh(z[2])
-
linear combination in output layer z[3] // size (1, 1)
z[3]=W[3]x,(W=2×1matrix)
-
sigmoid function for binary classification a[3] // size (1,1)
y^=a[3]=σ(z[3])
-
cross entrpy function l
l(xi,yi;W[2],b[2],W[3],b[3])=−(yilogyi^+(1−yi)log(1−yi^))
Backward propagation rule
single node
- node : linear combination or non-linearity happen
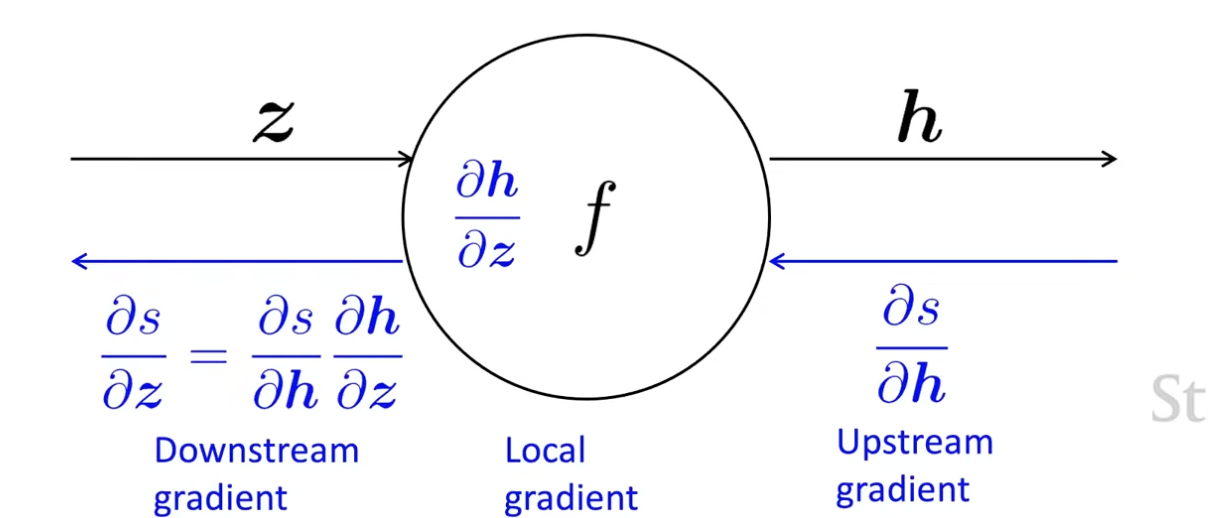
Donwstream gradient = Local gradient * Upstream gradient
Multiple node
- multiple inputs invoke multiple local gradients
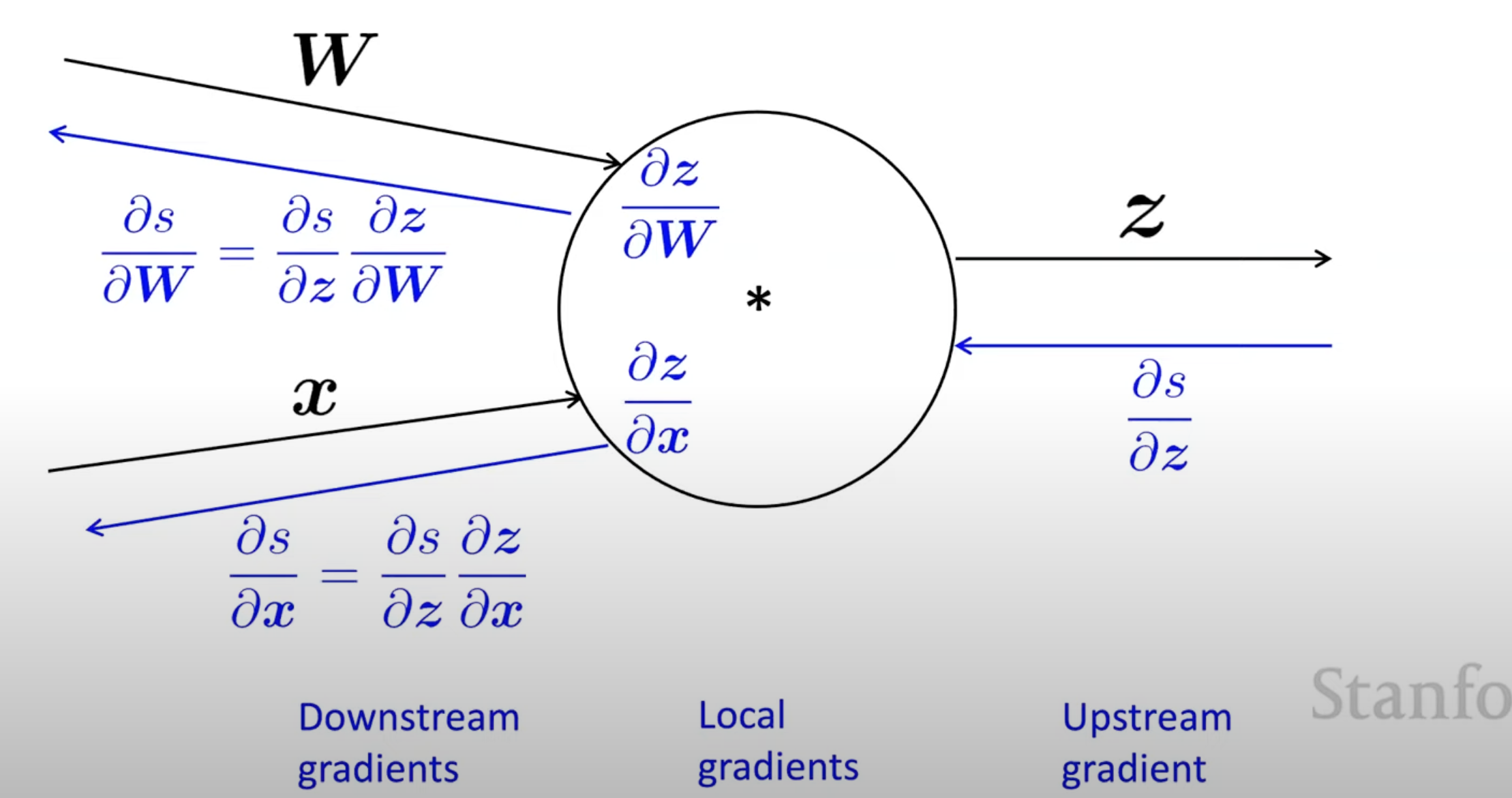
computing - output layer
- In output layer we want to get the dervatives below
∂a[3]∂l
∂z[3]∂l=∂a[3]∂l∂z[3]∂a[3]
- If there are nL (output) units in Layer L, then ∂aL∂l and ∂zL∂l are vectors with nL elements, ∂zL∂aL is nL * nL Jacobian matrix:
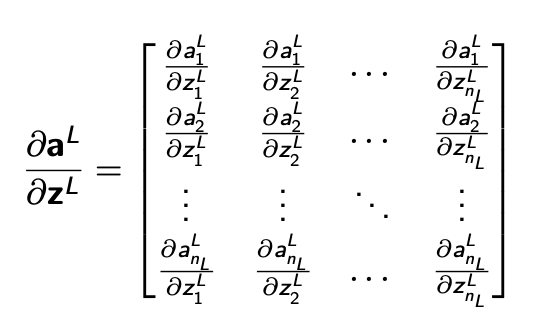
If , fL(non-linearity function) is applied element-wise(e.g., sigmoid) then this matrix is diagonal.
- because each non-relevant derivatives are zero except mathcing diagonal elements (e.g., a1=σ(z1), a2=σ(z2),..., an=σ(zn))
computing - hidden layer
- the inputs into layer I+1
zI+1=WI+1aI+bI+1
- for this linear combination,
- upstream derivatives: ∂zI+1∂l
- local derivatives: ∂zI∂zI+1
- downstream derivatives: ∂zI∂l
∂zI∂l=∂zI+1∂l∂zI∂zI+1
=∂zI+1∂l∂aI∂zI+1∂zI∂aI
=∂zI+1∂l⋅WI+1∂zI∂aI
computing - each parameter
-
WI
-
upstream derivatives: ∂zl∂l
-
local derivatives: ∂wl∂zI
-
downstream derivatives:
∂wl∂l=∂zl∂l∂wl∂zI
∂wl∂l=al−1⋅∂zl∂l
-
bI
-
upstream derivatives: ∂zl∂l
-
local derivatives: ∂bl∂zI=I
-
downstream derivatives:
∂bl∂l=∂zl∂l
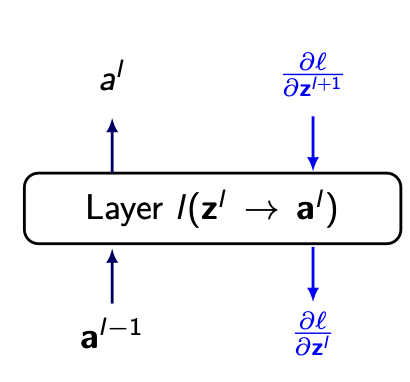
Backpropagation Fast calculation Tip
-
Assume fc network looks like this
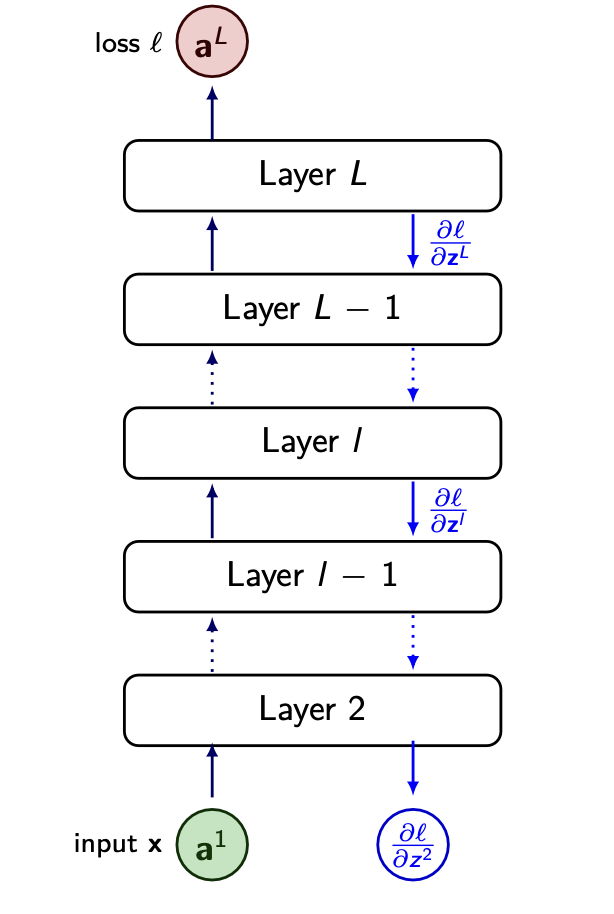
-
Layer part including z and a, as activation function
al=f(zl)
-
And between Layer l-1 and Layer l, there are weight Wl and bias bl. Then from the output of Layer l-1, the equaiton as follows.
zl=Wlal−1+bl
-
We assumed that all the gradient of l with respect z is already calculated. Such as..
∂z2∂l,∂z3∂l,…,∂zl∂l,…,∂zL∂l
-
In this situataion, if we want to get the gradient of weight in specific layer(l).
Just multiply inputted al−1 and the gradient from outputted zl
∂wl∂l=(al−1⋅∂zl∂l)T
- Bias is much more simple, it is just the gradient with respect to zl.
∂bl∂l=∂zl∂l