NVIDIA: 03 CNN
- NVIDIA의 Fundamentals of Deep Learning강좌의 03 CNN for ASL을 리뷰하기 위한 글이다.
Topic
- 02장에서 사용했던 모델은 overfitting문제가 있었다
- training dataset에 대해서는 high accuracy를 가지지만, validation dataset에 대해서는 상대적으로 좋지않은 accuracy를 보여주었다
- 이번장에서는 image reading과 classification에 잘 작용하는 CNN(convolutional neural network)를 만들어보자
Objectives
- CNN을 위한 data preprocessing
- CNN model creation
- Understanding the model layers
- Training the CNN & Observing its performance
Loading the data
import tensorflow.keras as keras
import pandas as pd
train_df = pd.read_csv("data/asl_data/sign_mnist_train.csv")
valid_df = pd.read_csv("data/asl_data/sign_mnist_valid.csv")
y_train = train_df['label']
y_valid = valid_df['label']
del train_df['label']
del valid_df['label']
x_train = train_df.values
x_valid = valid_df.values
# make categorical labels
num_classes = 24
y_train = keras.utils.to_categorical(y_train, num_classes)
y_valid = kears.utils.to_categorical(y_valid, num_classes)
# Normalizing
x_train = x_train/255
x_valid = x_valid/255 CNN을 위한 data reshaping
이전장에서는 이미지 하나에 해당하는 data row 가 784 pixel로 일렬 정렬되어 있었다.
- 기존 x_train.shape은 (27455, 784)
CNN은 pixel간의 정보를 필요로 하기 때문에
784 pixel를 다시 28*28로 reshape해줘야한다.
color channel의 개수 또한 kernel의 사이즈를 결정하므로 넣어야하는 정보이다.
이 문제에서 우리는 grayscale이미지를 사용하므로 1개의 channel밖에 없다.
따라서, 최종적인 shape은 (num_data, 28, 28, num_channels) 가 된다.
- 우리 문제에서는 (27455, 784)에서 (27455, 28, 28, 1)로 reshape
- coding convention: 그대로 유지하고 싶은 term에는 -1을 쓰면 됨
x_train = x_train.reshape(-1, 28, 28, 1)
x_valid = x_valid.reshape(-1, 28, 28, 1)CNN model 만들기
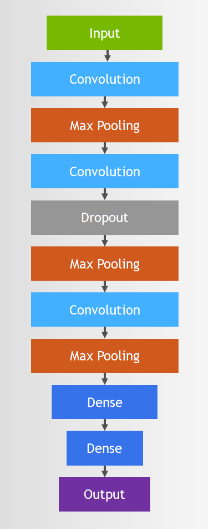
- 우리가 사용할 CNN구조는 다음과 같다.
- CNN은 이미 사람들이 만들어놓은 좋은 구조들이 많아서 이미 잘 동작하는 CNN model을 그대로 사용해볼 것이다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import ( Dense, Conv2D, MaxPool2D, Flatten, Dropout, BatchNormalization,)
model = Sequential()
#first Convolution
model.add(Conv2D(75, (3,3), strides=1, padding="same", activation="relu", input_shape=(28,28,1)))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
#Second Convolution
model.add(Conv2D(50, (3,3), strides=1, padding="same", activation="relu"))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
#Third Convolution
model.add(Conv2D(25, (3,3), strides=1, padding="same", activation="relu"))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
#Classification을 위한 fully-connected Neural Network만듦.
model.add(Flatten()) # CNN을 위해 2D로 만들었던 것을 1D로 다시 flatten
model.add(Dense(units=512, activation="relu"))
model.add(Dropout(0.3))
# 24개의 알파벳 중 하나로 classification함.
model.add(Dense(units=num_classes, activation="softmax"))
Conv2D
-
첫번째 Conv2D의 parameter를 살펴보면,
-
(75, (3,3), strides=1, padding="same")
-
75는 kernel의 개수를 의미한다.
-
(3,3)는 kernel의 size이다.
-
우리가 Conv2D를 통해서 얻고자 하는 것은 kernel element값이다.
-
따라서 3375개의 kernel value를 학습하고자 한다.
-
stride는 kernel이 image내에서 이동하는 stepSize를 말하고
-
padding="same"이면 input과 output의 size가 same이 된다. (ex. Zero-padding을 쓰면 그렇게 됨.)
BatchNormalization
- hidden layer에서의 value들을 normalize해줌.
MaxPool2D
- max-pooling은 overlap이 되지 않게 지정한 window내에서 max값만을 취한다
- 따라서 max-pooling의 output은 input에 비해 size가 줄어들게 된다.
- translation(변동, noise)에 동요하지 않게 하고
- size가 줄어들기 때문에 model이 빠르게 작동하게 도와준다
Dropout
- overfitting을 방지하는 테크닉이다.
- neuron을 random하게 선택하여 사용한다.
Flatten
- convolution layer를 통과해서 나온 값이 multidimension이기 때문에 이를 최종적인 classification layer를 위해 1D array로 flattening시켜준다.
- flatten한 vector는 feature vector라고 불리며 classification layer로 전달된다.
Dense
- Convolution을 수행하는 layer를 다 지나면 유용한 feature를 다 extraction했다고 볼 수 있다.
- 따라서 첫번째 Dense layer에서는 뽑힌 feature vector를 사용하여 특정classification에 어떤 벡터가 기여하는지를 학습한다.
- 두번째 Dense layer는 학습된 결과를 바탕으로 24개의 알파벳에 대한 classification결과를 내놓는다.(이때 activation func은 "softmax")
Model summarization
- 위에서 만든 모델을 살펴보면 우리가 앞전에 만든 Neural Network보다 더 적은 수의 parameter를 사용하는 것을 확인할 수 있다.
- 그 이유는 CNN이 fully-connected network가 아니기 때문이다.
model.summary()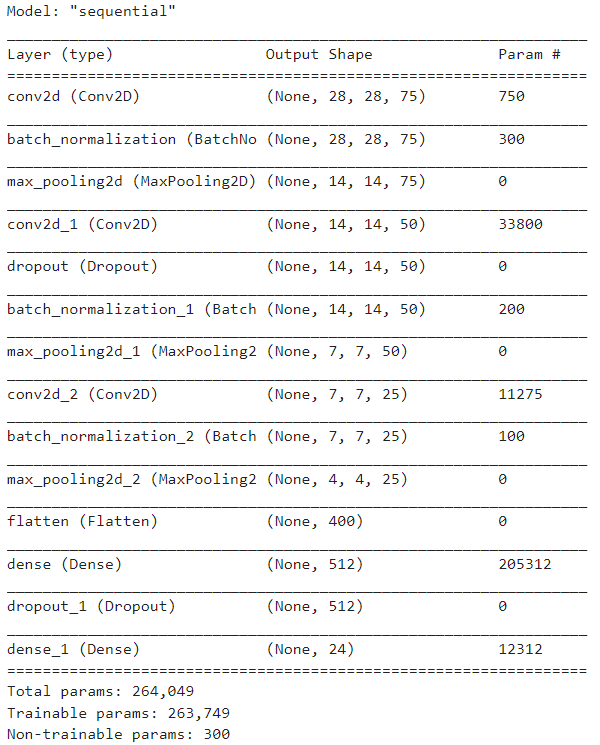
Compiling
model.compile(loss="categorical_crossentropy, metrics=["accuracy"])Training
model.fit(x_train, y_train, epochs=10, verbose=1, validation_data=(x_valid, y_valid))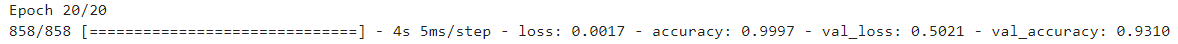
Results
- 이전 session의 ANN과 비교했을 때보다 훨씬 좋은 validation accuracy를 가지는 것을 확인할 수 있다.
- 다만, 그 accuracy 값이 왔다갔다 하는 것을 볼 수 있는데 아직 generalization이 완벽하게 되지 않았기 때문이다.
- 이를 해결하기 위한 방법은 다음 session에서 살펴보자.
GPU memory정리
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)Next
- data augmentation
