NVIDIA 04: Data Augmentaion
-
NVIDIA의 Fundatmentals of Deep Learning:04 Data Augmentation 리뷰를 위한 글이다.
-
이전 session에서 CNN의 validation accuracy가 일정하지 않음을 확인하였다.
-
이를 해결하기 위해 data augmentation이라는 기법을 살펴보자.
-
data augmentation은 dataset의 size와 variance를 증가시키는 것을 말한다.
-
size를 증가시키면, training과정에서 더 많은 이미지를 제공하게 되고
-
variance의 증가는 학습과정에서 중요하지 않은 feature를 무시하도록 해준다.
Objectives
- ASL dataset을 augment해보자
- Augment dataset을 이용하여 training
- well-trained될 model 저장하기
Data 준비
- 이전 session들에서 설명한 그대로를 가져옴
import tensorflow.keras as kears
import pandas as pd
#csv파일에서 데이터 로드
train_df = pd.read_csv("data/asl_data/sign_mnist_train.csv")
valid_df = pd.read_csv("data/asl_data/sign_mnist_valid.csv")
#y값과 x값 분리
y_train = train_df['label']
y_valid = valid_df['label']
del train_df['label']
del valid_df['label']
x_train = train_df.values
x_valid = valid_df.values
#y값을 one-hot encoding
num_classes = 24
y_train = keras.utils.to_categorical(y_train, num_classes)
y_valid = kears.utils.to_categorical(y_valid, num_classes)
#x값 normalize
x_train = x_train/255
x_valid = x_valid/255
# CNN을 사용할 것 이므로 1D flattening이 아니라 2D reshaping해야함
#-1은 number of data를 그대로 받아들임.
x_train = x_train.reshape(-1, 28, 28, 1)
x_valid = x_valid.reshape(-1, 28, 28, 1)CNN 모델
- 이전 03에서 사용했던 CNN 모델 사용
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import ( Dense, Conv2D, MaxPool2D, Flatten, Dropout, BatchNormalization,)
model = Sequential()
# First Convolutional layer
model.add(Conv2D(75, (3,3), strides=1, padding="same", activation="relu", input_shape=(28,28,1)))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
# Second Convolutional layer
model.add(Conv2D(50, (3,3), strides=1, padding="same", activation="relu"))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
# Third Convolutional layer
model.add(Conv2D(25, (3,3), strides=1, padding="same", activation="relu"))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2), strides=2, padding="same"))
# Fully connected layer for Classification
model.add(Flatten())
model.add(Dense(units=512, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(units=num_classes, activation="softmax"))Data Augmentation
keras에 ImageDataGenerator라는 image augmentation class가 있다.
data를 augmenting하기 위한 다양한 옵션들을 선택할수 있다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# class의 instance생성하기
datagen = ImageDataGenerator(
rotation_rage=10, #이미지를 0~180사이로 random하게 rotate.여기서는 0~10도
zoom_range=0.1, # random하게 zoom
width_shift_range=0.1, # 수평방향으로 랜덤하게 shift
height_shift_range=0.1, # 수직방향으로
horizontal_flip=True, # 수평방향으로 random하게 이미지 flip
vertical_flip=False,
)Batch
- ImageDataGenerator는 data batch를 할 수 있다는 장점이 있다
- batch는 training과정에서 잘 섞인 random한 sample이 선택되게 해준다
- imge_iter = datagen.flow(x_train, y_train, batch_size=32)
- flow() method가 data와 label을 가지고 augmented data의 batch를 만든다.
import matplotlib.pyplot as plt
import numpy as np
batch_size=32
img_iter = datagen.flow(x_train, y_train, batch_size=batch_size)
x, y = img_iter.next()
fig, ax = plt.subplots(nrows=4, ncols=8)
for i in range(batch_size):
image = x[i] #이때 image는 (28, 28, 1)
#원래 ax는 4*8이지만 flatten을 하면 1*32짜리 1D array가 됨
# image가 28*28*1이므로 squeeze를 쓰면 1짜리 Dim.이 사라짐
# imshow내부에 28*28짜리 이미지가 넘겨짐.
ax.flatten()[i].imshow(np.squeeze(image))
plt.show()Fitting the generator
- data generator를 sample data에 fit하게 한다.
- data-dependent transformation
datagen.fit(x_train)Compiling the model
- 이전 장에서 했던 방식과 같음.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'])Training with Augmented data
- Keras로 image data generator를 사용했다면 x_train과 y_train을 넘겨주는 대신 generator의 flow() method를 넘긴다.
- generator의 flow method는 augmentation을 live로 진행시켜주기 때문이다.
- epoch하나에서 몇개의 sample batch를 쓸 건인지를 steps_per_epoch에 넘겨줘야한다.
- 왜냐하면, generator가 제공하는 data가 indefinite하기 때문에 training data의 size가 fix되어 있지 않기 때문이다
- training data의 size가 fix되어 있다면 steps_per_epoch는 필요없다
우리는 한 epoch당 generator가 없었을때와 같은 수 만큼 training을 진행하고 싶다
- steps * batch_size = epoch한개에서의 전체 training image
- len(x_train)/batch_size = epoch한개에서의 batch step
model.fit(img_iter, epochs=10, steps_per_epoch=len(x_train)/batch_size, validation_data=(x_valid, y_valid))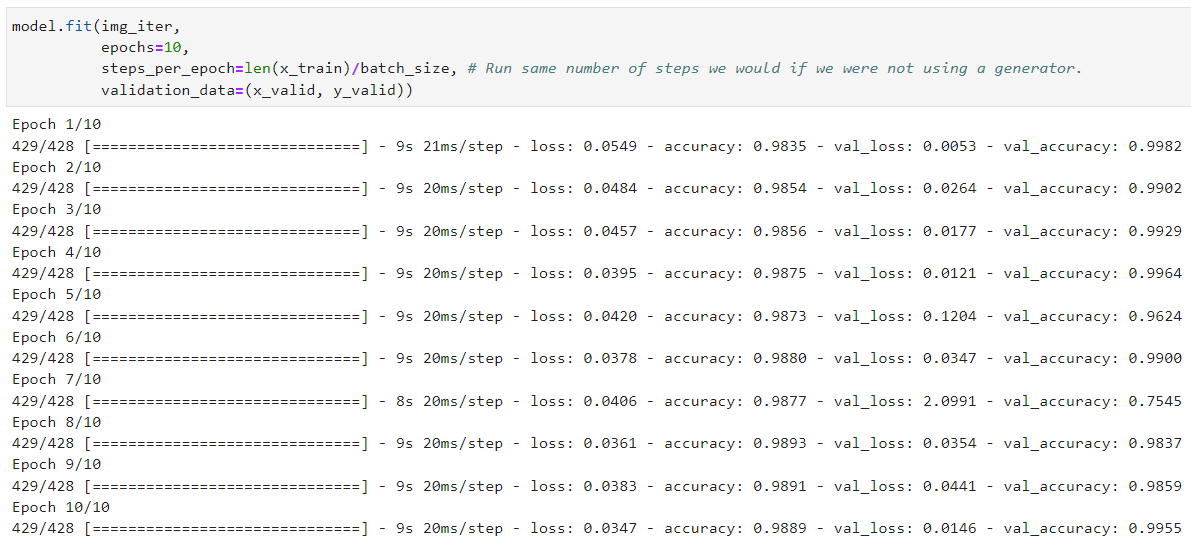
Results
- Data augmentation을 하기 전인 03 CNN의 결과와 비교했을 때
- validation accuracy가 더 높고, 일관됨(왔다갔다 하지 않음)을 알 수 있다.
- 이 결과는 새로 학습된 모델이 overfitting문제없이 더 잘 generalize됐다고 볼 수 있다.
Model Saving
model.save('asl_model')- 학습이 잘 된 우리의 모델을 저장한다
- 'asl_model'이라는 폴더를 만들어서 save한다.
- 다음 세션에서 저장된 이 모델을 다시 불러와서 새로운 이미지에 대해 prediction을 해볼 것이다.
GPU Memory clear
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)Next
- 이번 세션에서 generalization이 잘 된 모델을 만들고 저장하였음
- 이 모델을 다시 불러와서 unseen data에 대해 prediction을 해보자
