Flask 어플리케이션 성능 향상 - Flask-Caching으로 데이터 응답 시간 줄이기
데이터 가져올 때 생긴 문제❔
원하는 데이터를 원하는 형태로 가져오는 것까지는 정상적으로 동작하는데 문제는 데이터를 가져올 때 시간이 너무 오래 걸렸다. 응답 받는데까지 얼마나 걸리는지 알고싶어서 네트워크 탭을 확인해보니
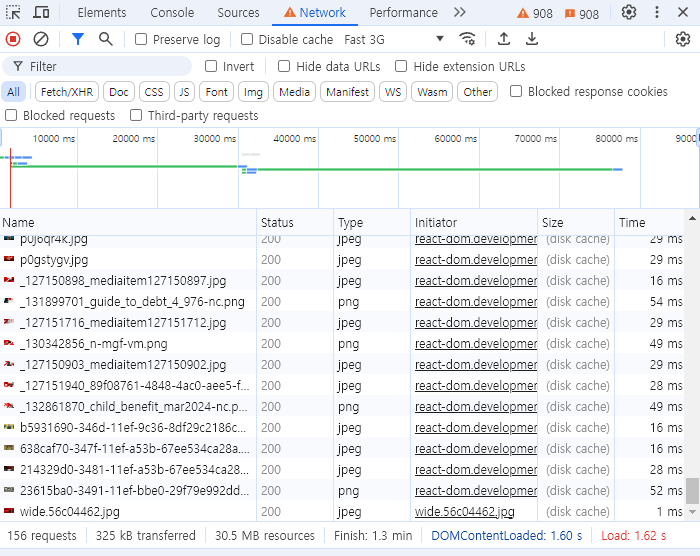
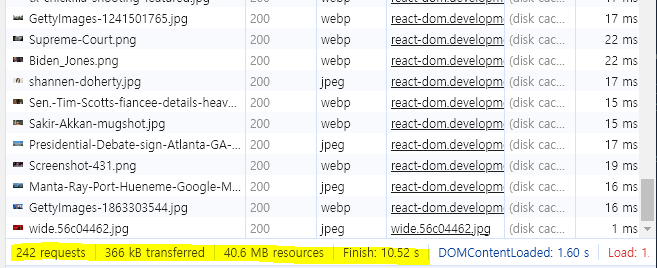
웹 페이지에 접속하면, 총 156개의 요청이 발생하며 이 과정에서 325KB의 데이터가 전송되었고 웹 페이지를 렌더링하는 데 필요한 총 리소스 양은 30.5MB 였다. 그래서 Finish, 페이지 로드가 완료되는 시간이 1.3분으로 오래 걸렸다. 사용자가 정보를 얻으려고 웹 페이지에 방문했는데 정보를 확인하기까지 상당한 시간이 소요된다면 이는 사용자 경험에 정말 좋지 않을 것이다.
데이터 응답 시간 줄이기❕
그래서 이 문제를 해결해보려고 웹 페이지의 성능을 개선하는 여러가지 방법에 대해 고민을 해보았다. HTTP 요청 자체를 최소화하거나 리소스 최적화, 캐싱 활용하기 등의 방법을 통해 페이지 로딩 시간을 단축시키는 것이다.
HTTP 요청 최소화
일반적으로 단순한 웹 페이지같은 경우에는 수 십개, 복잡한 웹 어플리케이션은 수백 개 이상의 요청이 발생할 수 있다고 한다. 내가 만든 프로젝트는 아주 간단한 프로젝트인데 요청의 수가 많은 이유가 가져오는 뉴스 데이터의 양이 많기 때문인 것 같다. 각 뉴스 소스에서 최대 10개씩 가져와서 홈 화면에서는 30개, 각 카테고리별 화면에는 10개의 뉴스 데이터를 보여주니 요청이 줄어들고 응답 시간도 당연히 짧아졌다.
from flask import Flask, jsonify
from flask_cors import CORS
import feedparser
from bs4 import BeautifulSoup
import requests
app = Flask(__name__)
CORS(app)
NEWS_SOURCES = [
'http://rss.cnn.com/rss/cnn_topstories.rss',
'http://feeds.foxnews.com/foxnews/latest',
'http://feeds.bbci.co.uk/news/rss.xml',
]
def fetch_thumbnail(link):
response = requests.get(link)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
og_image = soup.find('meta', property='og:image')
if og_image:
return og_image['content']
return None
def fetch_news(limit_per_source=10):
all_news = []
for source in NEWS_SOURCES:
feed = feedparser.parse(source)
count = 0
for entry in feed.entries:
if count >= limit_per_source:
break
thumbnail = fetch_thumbnail(entry.link)
if thumbnail is not None:
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'thumbnail': thumbnail,
'published': entry.get('published'),
'summary': entry.get('summary')
}
all_news.append(news_item)
count += 1
return all_news
@app.route('/news')
def get_news():
news = fetch_news(limit_per_source=10) # 각 소스에서 최대 10개의 뉴스 아이템을 가져옴
return jsonify(news)
if __name__ == '__main__':
app.run(debug=True)
수정된 코드를 살펴보면 fetch_news 함수에 limit_per_source라는 매개변수를 추가해서 각 소스에서 가져올 최대 뉴스 데이터 수를 지정할 수 있도록 설정했다. 그리고 fetch_news 함수 내에서 뉴스 데이터를 가져오는 for 반복문에 count 변수를 0으로 설정하고 데이터를 하나씩 추가할 때마다 1씩 증가하도록 해서 뉴스 데이터를 셀 수 있도록 했다. 그리고 만약 limit_per_source(10개)에 도달하면 해당 반복문의 반복을 중단하도록 했다.
응답 시간도 줄어들고 데이터도 정상적으로 받아왔지만 뭔가 근본적인 문제를 해결한 게 아니라는 생각이 들었다. 데이터를 다 받아오면서도 응답 시간을 줄일 수 있는 방법이 분명히 있을 것 같았다. 그래서 여러 방법을 다 해보고 최후의 수단으로 남겨두었다.
Flask-Caching
다른 방법을 생각해보다가 전에 쇼핑몰 프로젝트를 하면서 캐싱을 사용했던 게 생각이 났다. 처음에 페이지에 데이터를 불러올 때 데이터를 임시로 저장해두고 이후에 같은 요청이 발생하면 새로 데이터를 불러오는 게 아니라 임시로 저장해둔 결과를 다시 사용하는 것이다. 이렇게 하면 매번 데이터를 요청하는 작업을 줄일 수 있다! python에서도 캐싱 사용하는 방법을 찾아보니 Flask에서 지원하는 Flask-Caching이라는 라이브러리가 있어서 이것을 사용해보았다.
💡 참고한 Flask-Caching 공식 사이트
https://flask-caching.readthedocs.io/en/latest/
사용법은 생각보다 훨씬 더 간단했다. 우선은 Flask-Caching을 설치해보자!
pip install Flask-Caching
🥲 캐싱 설정
공식 홈페이지 setup을 보면 Flask-Caching 캐싱 설정하는 방법이 설명되어 있다.

나는 다른 백엔드를 사용하고 있기 때문에 위 두 방법으로 섞어서 캐싱을 시도해보았다. 방법 A는 클래스 인스턴스화를 할 경우 캐시 설정을 제공하는 방법이고, 방법 B는 init_app 메서드를 사용하여 나중에 설정을 제공하는 방법이다.
cache = Cache(app, config={'CACHE_TYPE': 'SimpleCache'})Cache(app, config={'CACHE_TYPE': 'SimpleCache'}) : Cache 클래스의 생성자를 호출해서 새로운 캐시를 만들고, 이렇게 만든 캐시에 대한 설정을 직접 할 수 있다. 'CACHE_TYPE': 'SimpleCache'는 간단한 메모리 캐시를 사용하겠다는 것을 의미한다. 이때 init_app 메서드를 사용하지 않은 이유는 'Cache' 객체를 생성할 때 이미 Flask 어플리케이션 객체(Flask(name)으로 생성한 app 객체)을 전달해서 초기화했기 때문이다.
🥲 캐싱 유효시간 지정하기
이렇게 캐시 설정을 마치고나면 시간을 지정해서 그 시간 동안 재사용할 수 있도록 해주면 된다.

잘 모르겠지만 함수를 캐싱하기 위해 cached() 데코레이터를 사용하면 되는 것 같다. 그래서 캐싱할 함수 위에 일단 1시간정도 유지하고 싶기 때문에 timeout을 3600초(1시간)로 지정했다.
@cache.cached(timeout=3600) 캐시 설정하고 유효 시간만 설정해주고 나서 잘 작동하는지 확인해보니까
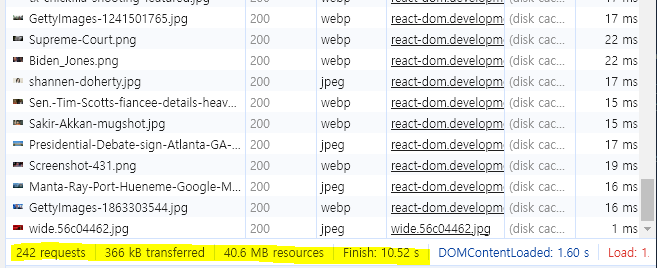
캐싱을 적용하면서 요청 수는 증가했지만, 전송된 데이터와 사용된 리소스의 양이 증가하면서도 페이지 로드 완료 시간(Finish)이 1분에서 10초로 크게 줄었다🤗 함수의 결과가 캐시에 저장되고 유효 시간 1시간 동안은 동일한 결과를 반환하기 때문이다. 캐싱을 해둔 덕분에 이전에 비해 더 많은 리소스를 클라이언트에게 더 빨리 전달할 수 있게 되었다!
최종으로 수정된 코드!!
from flask import Flask, jsonify
from flask_cors import CORS
import feedparser
from bs4 import BeautifulSoup
import requests
from flask_caching import Cache
app = Flask(__name__)
CORS(app)
cache = Cache(app, config={'CACHE_TYPE': 'SimpleCache'})
NEWS_SOURCES = [
'http://rss.cnn.com/rss/cnn_topstories.rss',
'http://feeds.foxnews.com/foxnews/latest',
'http://feeds.bbci.co.uk/news/rss.xml',
]
def fetch_thumbnail(link):
response = requests.get(link)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
og_image = soup.find('meta', property='og:image')
if og_image:
return og_image['content']
return None
@cache.cached(timeout=3600)
def fetch_news():
all_news = []
for source in NEWS_SOURCES:
feed = feedparser.parse(source)
for entry in feed.entries:
thumbnail = fetch_thumbnail(entry.link)
if thumbnail is not None:
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'thumbnail': thumbnail,
'published': entry.get('published'),
'summary': entry.get('summary')
}
all_news.append(news_item)
return all_news
@app.route('/news')
def get_news():
news = fetch_news()
return jsonify(news)
if __name__ == '__main__':
app.run(debug=True)
느낀 점
웹 페이지 초기 상태에서는 페이지 로드 시간이 상당히 길었고, 사용자가 필요한 리소스를 가져오는 데 꽤 많은 시간이 소요되는 문제가 있었다. 그래서 웹 페이지의 성능 개선을 위해 Flask-Caching 라이브러리로 캐싱을 해보니 불필요하게 동일한 리소스를 반복적으로 다운로드하는 것을 줄일 수 있었고 중요한 리소스는 브라우저에 저장해두었다.
캐싱을 적용한 결과 초기 페이지 로딩 시간이 많이 줄었고, 그로 인해 사용자들이 웹 페이지를 더 빠르게 로드하고 정보를 찾아볼 수 있게 되어서 사용자 경험이 크게 개선되었다. 이전 프로젝트를 진행하면서도 캐싱을 사용해 보았지만 정말 좋은 기능이라고 생각한다. 특히 Flask-Caching 라이브러리를 쓰니까 캐싱을 구현하는 것이 사용법이 복잡하지 않고 생각보다 쉽게 캐싱할 수 있어서 너무 좋았다.
솔직히 데이터 응답 시간이 오래 걸리는 문제를 해결하는 과정이 쉽지 않았다. 처음에는 비동기처리도 고민해봤는데 찾아보니 Flask에서 비동기처리로 응답 속도를 줄이는 방법은 최적이 아니라고 판단했다. 막막해져서 그냥 포기할까 싶었는데 데이터 받아오는데 시간이 오래 걸리면 이 프로젝트가 무슨 소용일까 싶어서 열심히 고민해서 원하는대로 동작할 수 있게 된 점이 뿌듯하다. 웹 개발 과정에서 캐싱을 통한 성능 최적화가 반드시 고려해야 할 중요한 전략 중 하나라는 것을 한번 더 실감하게 되는 좋은 경험이었다.
