Python으로 작성된 백엔드 서버를 Flask 프레임워크 사용해서 구현하기!
뉴스 사이트에서 가져온 데이터를 한 곳에 모아 사용자가 편리하게 검색하고 볼 수 있는 웹 페이지를 만들어보았다. 백엔드 서버는 처음 구현해보았는데 Python으로 작성했다. 많이 들어본 언어이기도 하고 찾아보니 문법도 복잡하지 않고 가독성이 좋아서 코드 작성하고 이해하는데 쉽다고 해서 Python으로 작성하게 되었다.
Flask 프레임워크를 선택한 이유는?
Python 웹 프레임워크 Django랑 Flask 중에 고민하다가 Flask를 선택한 이유는 찾아보다보니 Django보다 가볍고 유연해서 소규모 프로젝트나 간단한 어플리케이션 개발에 많이 사용된다는 것을 알게 되었기 때문이다. 특히나 Python 사용이 처음인 나한테는 Flask로 시작해서 기본적인 개념이나 사용 방법을 익히고, 나중에 좀 더 복잡하거나 대규모 프로젝트를 할 때 Django를 시도해보는 것이 좋겠다고 생각했다. 실제로 Flask를 사용해보니 개발 과정이 예상보다 복잡하지 않았고, 간단한 기능을 구현하는 것도 어렵지 않았다.
Python 설치하고 간단한 백엔드 서버 구현해보기
-
파이썬 다운
https://www.python.org/downloads/ 에서 python 다운로드 하기 -
Python 패키지 관리자인 pip도 함께 설치
python -m pip install --upgrade pip // pip 설치
pip --version // pip 제대로 설치되었는지 확인- Flask 설치하고 사용해보기
💡 Flask 공식 홈페이지
https://flask.palletsprojects.com/en/3.0.x/quickstart/#a-minimal-application
가상환경 생성 : 가상 환경을 생성하면 각각의 프로젝트마다 독립적인 Python 환경을 구축할 수 있다. 따라서 각 프로젝트가 필요로 하는 패키지 버전을 분리하여 관리할 수 있게 해준다.
python -m venv myenv- 가상환경 활성화 : 명령어를 입력하면 (myenv) 가상환경 이름이 앞에 붙는다.
(myenv) C:\Users\user\Desktop\projects\newsnest> 처럼!
앞에 myenv가 붙으면 가상환경이 활성화된 것을 의미하고, 이 상태에서 Python 명령어를 실행하거나 패키지를 설치하면 해당 가상환경에만 영향을 준다.
myenv\Scripts\activate- Flask 설치
pip install flask- src에 app.py파일 만들고 코드 작성하기
예시)
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run(debug=True)
- app.py 파일 열고 브라우저에서 확인
src 경로로 들어가서 app.py 파일 열기
cd src
python app.pyFlask 서버가 실행되면 터미널에 아래와 같은 메시지가 표시되는데 브라우저 열어보면 'Hello, World!'를 확인할 수 있다.
*Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
- 비활성화
만약 가상환경을 비활성화 하고 싶다면 비활성화 명령어를 입력해주면 된다
deactivate뉴스 데이터 가져오기
뉴스 소스들에서 최신 뉴스 피드 가져오기!
어떤 함수인지, 어떤 것을 반환하는지 등 동작 내용은 긴단하게 주석을 달아보았다.
from flask import Flask, jsonify
from flask_cors import CORS
import feedparser
app = Flask(__name__)
CORS(app)
# 뉴스 소스들의 RSS 피드 URL 리스트
NEWS_SOURCES = [
'http://rss.cnn.com/rss/cnn_topstories.rss',
'http://feeds.foxnews.com/foxnews/latest',
'http://feeds.bbci.co.uk/news/rss.xml',
]
# 각 뉴스 소스에서 최신 뉴스를 가져오는 함수
def fetch_news():
all_news = [] # 모든 뉴스 항목을 담을 배열
for source in NEWS_SOURCES: # URL 리스트를 돌면서
feed = feedparser.parse(source) # 각 뉴스 소스의 RSS 피드를 파싱
for entry in feed.entries:
# 필요한 뉴스 아이템들을 생성하기
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'published': entry.get('published'),
'summary': entry.get('summary')
}
all_news.append(news_item) # 생성된 뉴스 아이템 배열에 추가
return all_news # 모든 뉴스 아이템이 담긴 배열을 반환
# Flask 앱의 '/news' 엔드포인트에 대한 핸들러 함수
@app.route('/news')
def get_news():
news = fetch_news() # fetch_news 함수를 실행하여 모든 뉴스를 가져옴
return jsonify(news) # JSON 형식으로 뉴스 데이터를 반환
# 메인 실행 부분
if __name__ == '__main__':
app.run(debug=True) # 디버그 모드로 Flask 앱 실행
좀 더 상세하게 코드의 내용을 살펴보자면!
웹 사이트에서 제공하는 뉴스 데이터를 읽어오기 위해 feedparser를 사용했다. feedparser는 웹사이트에서 제공하는 최신 뉴스나 블로그 글 같은 피드를 읽어와서 파이썬 객체로 변환하는 Python 패키지이다. RSS와 Atom 형식의 웹 피드를 파싱하는 데 사용된다. feedparser는 설치해야 사용할 수 있고 pip install feedparser 명령어를 사용해서 설치할 수 있다.
위 코드에서 뉴스 소스를 보면
NEWS_SOURCES = [
'http://rss.cnn.com/rss/cnn_topstories.rss',
'http://feeds.foxnews.com/foxnews/latest',
'http://feeds.bbci.co.uk/news/rss.xml',
]세 가지 다른 뉴스 소스의 RSS 피드 URL들을 이용해서 feed = feedparser.parse(source) 주어진 source URL을 사용해서 해당 RSS 피드를 파싱한다. 각 피드는 최신 뉴스 데이터들을 포함하고 있고 이 데이터들은 feed.entries 리스트에 저장된다. 그리고 feed.entries에 있는 각 항목들에는
- entry.title : 뉴스 기사 제목
- entry.link : 뉴스 기사 링크
- feed.feed.title : 뉴스 소스 제목(피드의 제공자 = bbc나 cnn 같은)
- entry.get('published') : 뉴스 기사 발행일
- entry.get('summary') : 뉴스 기사 내용 요약본
이때 발행일과 요약본은 get() 메서드를 사용해서 가져왔는데 처음에는 entry.published, entry.summary로 읽어왔다. 그랬더니 객체 속성 error가 났다.

찾아보니 객체의 속성에 접근하려고 했는데 해당 속성이 존재하지 않는 경우에 발생한다고 한다. published, summary가 존재하지 않는 뉴스 피드가 있어서 에러가 나는 것 같아서😥 get() 메서드를 사용해보았다.
잠깐! feedparser의 get() 메서드?
feedparser를 사용할 때 각 항목의 필드 값을 가져오기 위해 get() 메서드를 사용하는 것이 일반적이다. feedparser로 파싱된 피드의 각 항목(entry)은 사전과 구조가 비슷해서 항목의 필드들은 사전의 키로 접근 할 수 있지만, 만약 키가 존재하지 않는 경우 에러를 방지하기 위해 get() 메서드를 사용할 수 있다. 그래서 published, summary도 get() 메서드로 가져왔다. entry.get('published')를 보면 entry에서 published라는 키에 해당하는 값을 가져오는데 이때 만약 해당 published라는 키가 없다면 'None'을 반환하도록 한다. get 메서드를 사용하면 코드 실행 중에 예상치 못한 오류를 방지하고 안정성을 높이는데 도움을 준다.
get() 메서드를 사용하니 published와 summary도 무사히 받아올 수 있었다. 그리고 화면에 뉴스의 썸네일도 함께 보여주면 사용자가 봤을 때 UI가 훨씬 편할 것 같아서 thumbnail도 가져오려고 시도해보았다.
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'thumbnail':entry.get('thumbnail'),
'published': entry.get('published'),
'summary': entry.get('summary')
}데이터를 가져올 뉴스 사이트에 확인해보니 다들 썸네일 이미지가 있는데 /news 브라우저를 열어서 확인해보니 모든 피드가 thumbnail이 null로 들어와있었다.

그래서 어떻게 하면 썸네일을 가져올 수 있을까 찾다보니까 뉴스 링크에서 HTML을 가져온 다음 beautifulsoup이라는 것을 사용하면 가능하다고 해서 해보았다!
beautifulsoup은 Python의 HTML이나 XML 문서를 파싱하고 데이터를 추출하기 위한 파서 라이브러리인데 주로 웹 스크래핑과 데이터 추출 작업에서 사용된다고 한다. HTML 문서의 구조를 탐색하고 원하는 데이터를 쉽게 추출할 수 있도록 간단하고 직관적인 API를 제공한다.
우선 beautifulSoup 라이브러리를 사용해서 주어진 링크에서 HTML을 가져와 이미지 메타 태그를 찾아서 그 내용을 반환하는 fetch_thumbnail라는 함수를 만들었다.
def fetch_thumbnail(link):
response = requests.get(link)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
og_image = soup.find('meta', property='og:image')
if og_image:
return og_image['content']
return Noneresponse = requests.get(link) : entry의 링크를 전달받으면 HTTP GET 요청을 보내고 웹 서버로부터 응답을 기다린다.
html = response.text : 응답받은 내용을 텍스트 형식으로 가져온다. 웹 페이지의 HTML 코드가 문자열 형태로 저장된다!
soup = BeautifulSoup(html, 'html.parser') : BeautifulSoup 라이브러리를 사용해서 HTML 코드를 파싱해서 soup에 저장한다.
og_image = soup.find('meta', property='og:image') : beautifulsoup에서 제공하는 HTML 요소 탐색 메서드 find를 이용해서 파싱된 soup의 meta 태그 중에서 property가 og:image인 요소를 찾아서 og_image에 저장한다. 이때 'og:image'는 Open Graph Protocol에서 이미지를 나타내는 메타 태그 속성이다.
만약 og_image가 있다면 즉, og_image가 None이 아니라면 저장된 og_image의 URL을 반환하고 og_image가 None이면 None을 반환한다.
이제 beautifulsoup으로 추출한 url을 thumbnail 속성으로 저장해보자!
def fetch_news():
all_news = []
for source in NEWS_SOURCES:
feed = feedparser.parse(source)
for entry in feed.entries:
thumbnail = fetch_thumbnail(entry.link)
if thumbnail is not None:
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'thumbnail': thumbnail,
'published': entry.get('published'),
'summary': entry.get('summary')
}
all_news.append(news_item)
return all_newsthumbnail = fetch_thumbnail(entry.link) : 각 뉴스 entry의 link를 image를 가져오는 fetch_thumbnail로 전달하고 반환받은 값을 thumbnail에 저장한다.
if thumbnail is not None: : 썸네일 이미지가 있는 것만 가져오고 싶어서 if 조건문을 추가했다. 그리고 새로운 뉴스 아이템을 생성하고 이렇게 생성한 뉴스 아이템을 all_news 빈 배열에 추가한다. 모든 뉴스 항목이 담긴 all_news 리스트를 반환하면 된다!

/news 브라우저 확인해보니 thumbnail에 이미지 URL이 무사히 들어왔고 null인 피드가 없는 것도 확인할 수 있었다😆
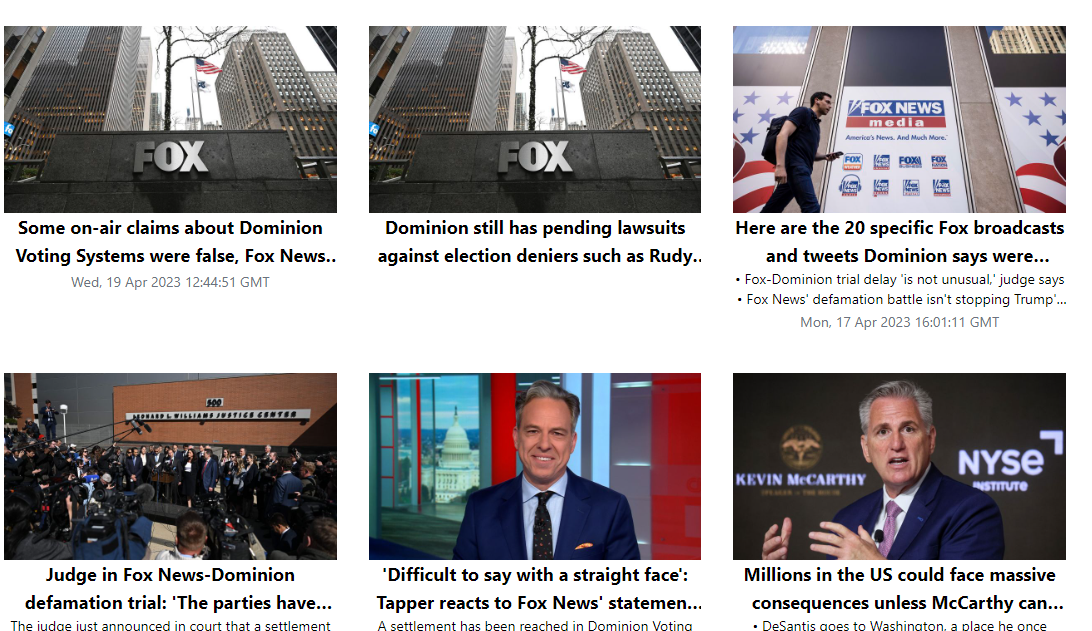
- 전체 코드
from flask import Flask, jsonify
from flask_cors import CORS
import feedparser
from bs4 import BeautifulSoup
import requests
app = Flask(__name__)
CORS(app)
NEWS_SOURCES = [
'http://rss.cnn.com/rss/cnn_topstories.rss',
'http://feeds.foxnews.com/foxnews/latest',
'http://feeds.bbci.co.uk/news/rss.xml',
]
def fetch_thumbnail(link):
response = requests.get(link)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
og_image = soup.find('meta', property='og:image')
if og_image:
return og_image['content']
return None
def fetch_news():
all_news = []
for source in NEWS_SOURCES:
feed = feedparser.parse(source)
for entry in feed.entries:
thumbnail = fetch_thumbnail(entry.link)
if thumbnail is not None:
news_item = {
'title': entry.title,
'link': entry.link,
'source': feed.feed.title,
'thumbnail': thumbnail,
'published': entry.get('published'),
'summary': entry.get('summary')
}
all_news.append(news_item)
return all_news
@app.route('/news')
def get_news():
news = fetch_news()
return jsonify(news)
if __name__ == '__main__':
app.run(debug=True)
느낀 점
비록 간단한 프로젝트이긴 하지만 python을 이용해서 백엔드를 구현해볼 수 있어서 너무 좋았다. 문법이 간단하고 읽기 쉬워서 코드를 작성하고 이해하는 과정이 크게 어렵지 않았고 오히려 재밌는 부분도 있었다. 이번 프로젝트에서는 단순히 데이터만 가져왔지만, 앞으로 더 복잡하고 해결하기 어려운 문제들을 만나게 되면 그때마다 필요에 따라 기술들을 습득하고 적용해 나가야할 것같다. 그때 이번 프로젝트가 반드시 도움이 될 것이라고 생각하고 다음엔 Django를 사용해 볼 수 있는 좀 더 크고 복잡한 프로젝트도 한번 해봐야겠다고 생각했다.
