Object Detection
-
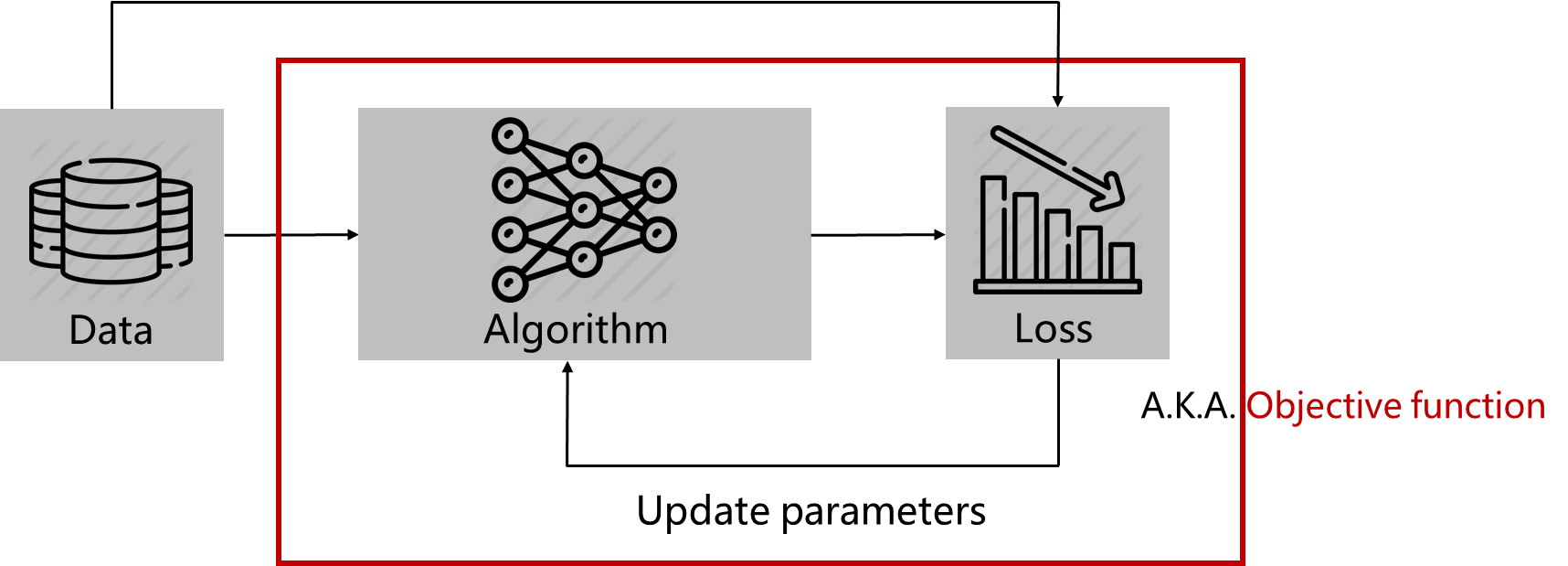
Remind : ML Framework
-
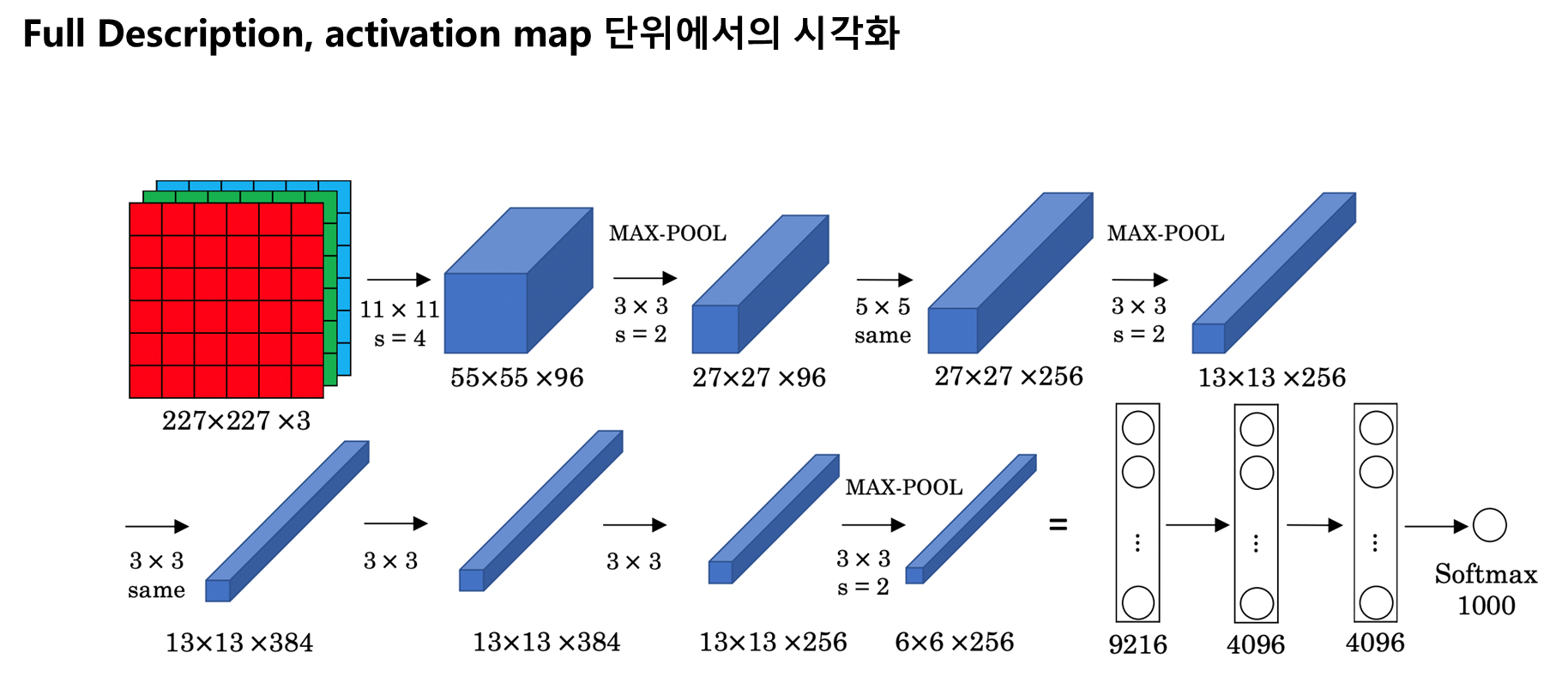
Remind : AlexNet
-
Remind : 1x1 Convolution

-
Remind :Depthwise Seperable Convolution

Object Detection
- 사진 속의 모든 객체(object)를 인지하는 문제(task)

Object Detection의 파이프라인
- 물체의 클래스 인지(classification) + 물체의 위치 인지(localization)

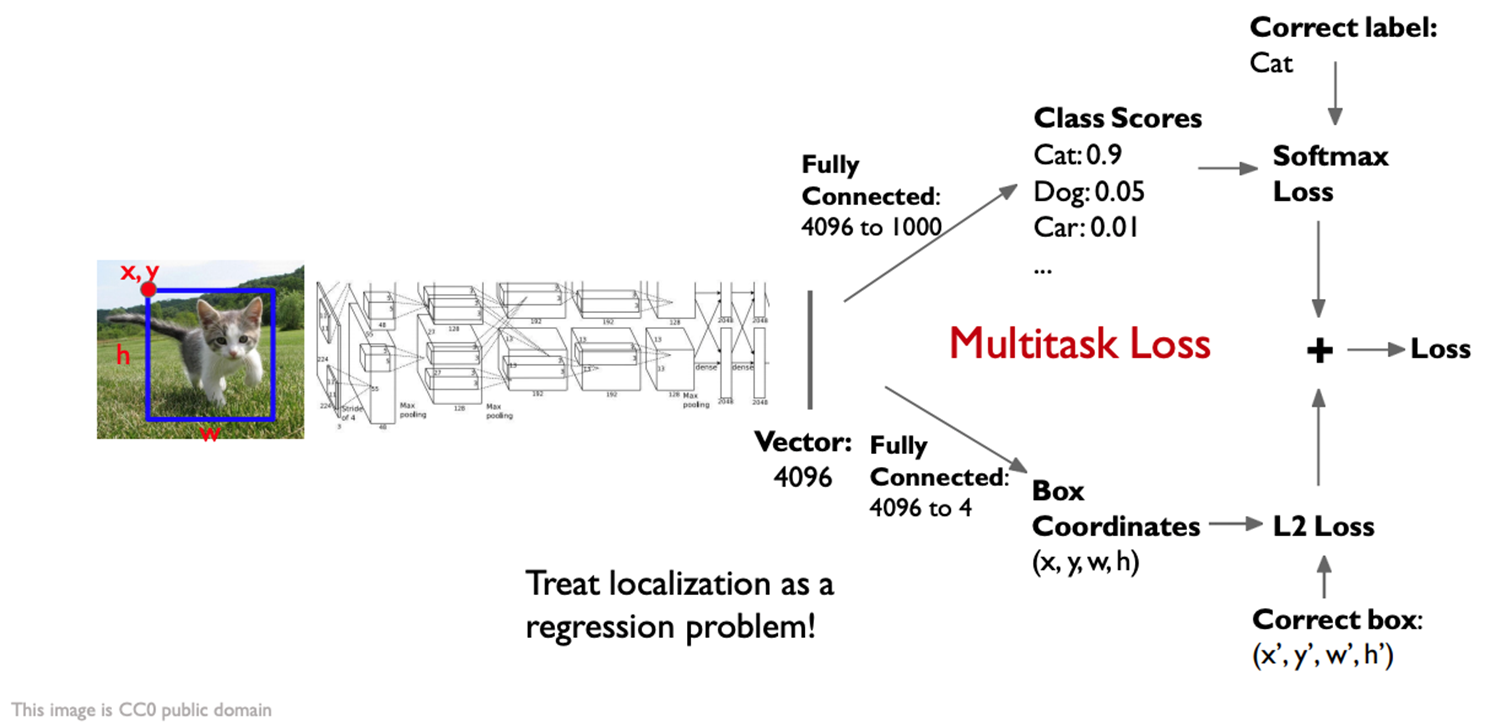
Object Detection의 방식 - Single Object
- 이미지 분류가 특징 벡터를 통해 분류만 했다면, 앞으로는 분류(classification) 뿐만 아니라 Position 정보를 뽑는 작업(localization)도 동시에 함. 이러한 방식을 mullti-task loss로 해결함.
- 이미지를 Alexnet과 같은 모델을 통과 시켜 vector를 얻은 뒤 병렬적으로 classification과 localization을 실행
Object Detection의 방식 - multiple Object
Sliding window
- 일부 window를 뽑으면서, 객체 인지 문제를 품

Sliding window의 문제점
- 너무나 많은 sliding window가 필요 너무나 많은 계산 필요 실시간 불가능

Region proposal / Selective search
- 물체가 가장 높은 확률로 있을 곳에 box를 만들어서 classification

RCNN (Regions with CNN Features)
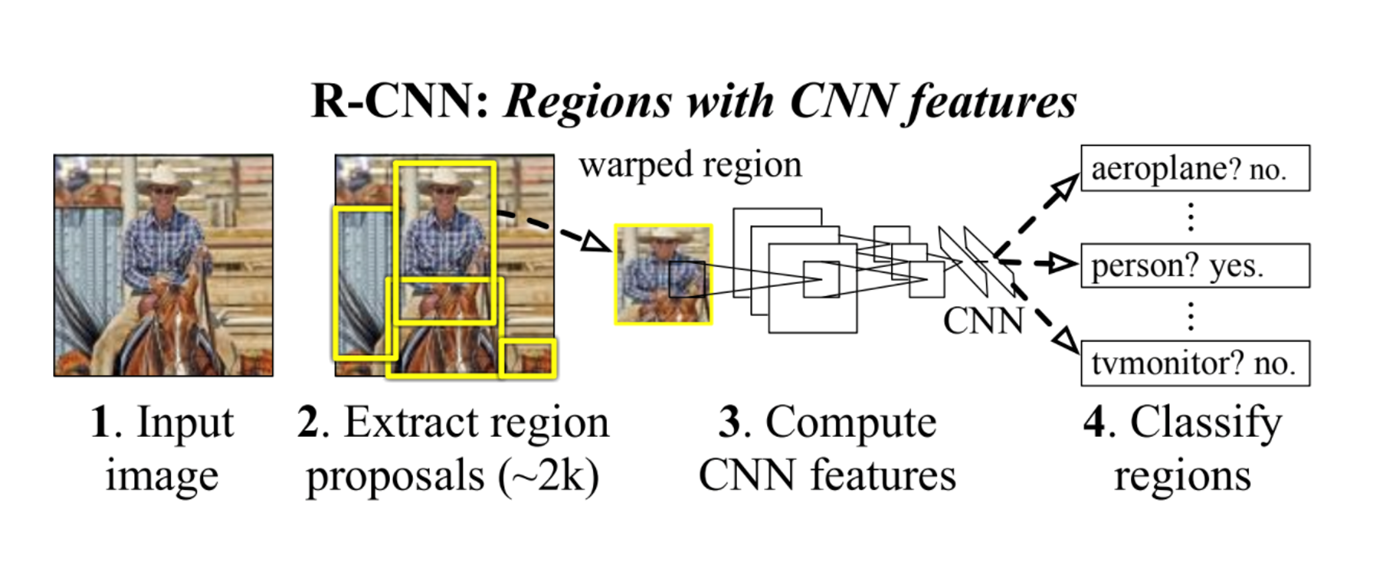
- 이미지를 Input으로 넣어줌
- Region proposals 추출 (2000개 정도)
- CNN Feature 계산
- Classification
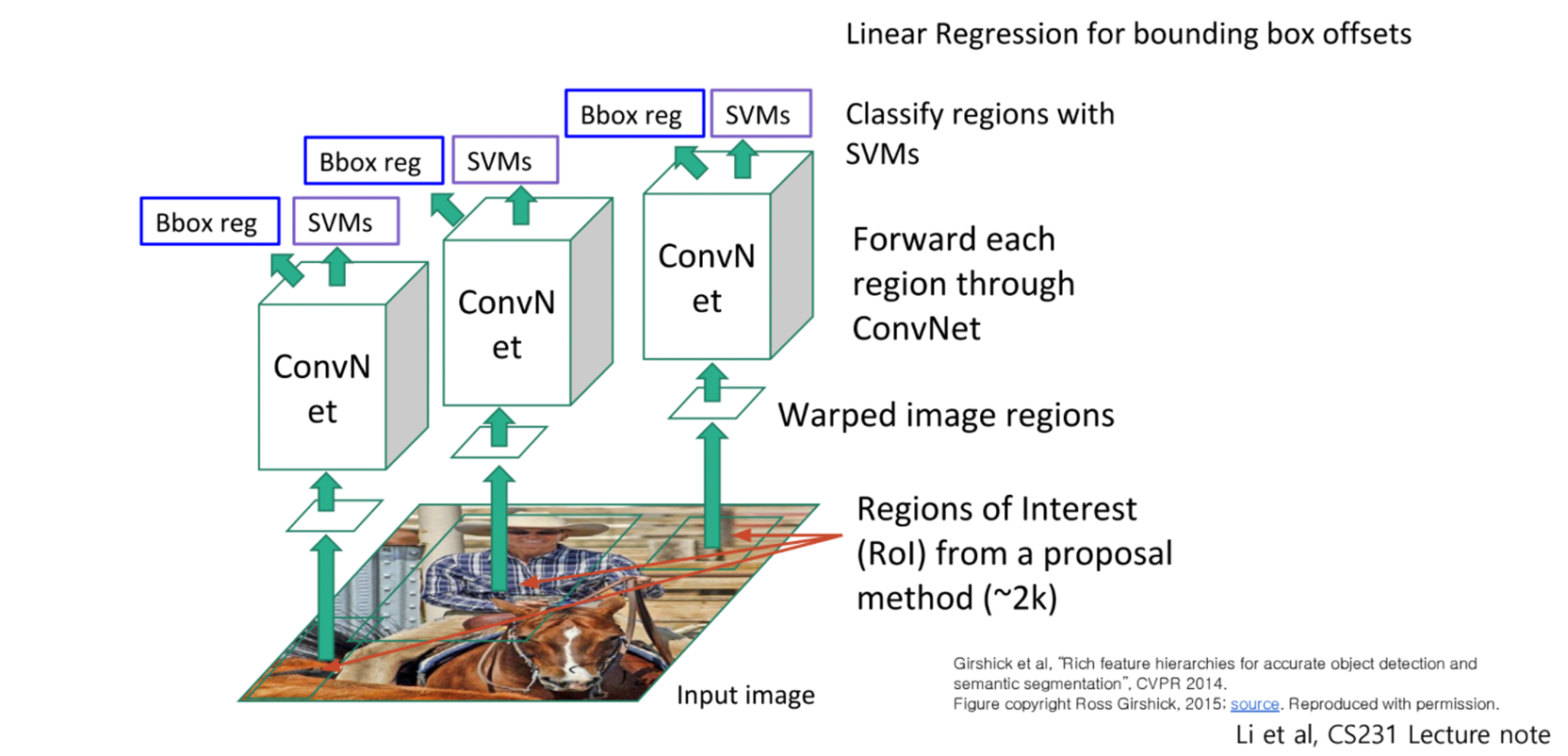
- 추출한 영역을 같은 크기로 warp시키는 작업을 함 동일한 사이즈에 대해 image classificaion 하기 위해
- CNN을 통과시킬 때, 사용할 class의 개수는 N+1 개.
- +1개는 background를 분류하는 class를 위한 것.
- Bbox reg: x,y,h,w의 box position을 예측
- SVM : 클래스 분류 (fully connected layer + softmax도 충분히 가능)
- transfer learning on backbone
- 결국 1개 image의 inference 속도가 느림
- 약 2000개의 Region proposal에 대하여, 독립적으로 inference를 해야함
- 이 문제를 해결한 것이 Fast RCNN
Fast RCNN
- CNN으로 먼저 Feature를 뽑고, feature에 대해서 region proposal을 하자
- 기존 warp의 작업을 Maxpooling 등을 adaptive하게 활용해 규격화된 사이즈로 feature를 가공함.
ROI Pooling layer라고 부름.
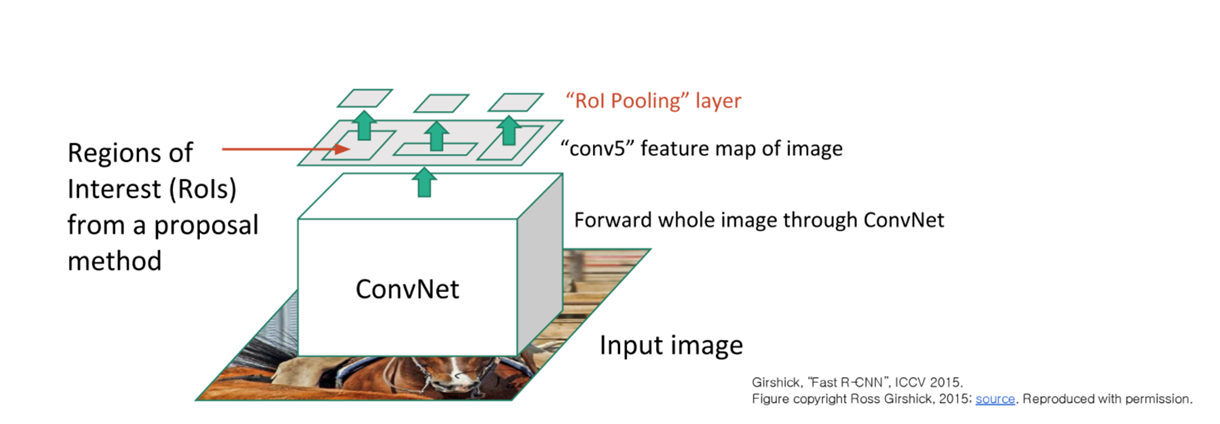
- 결국 구조는 ROI layer를 FC layer에 통과시키고 classification과 localization을 진행함
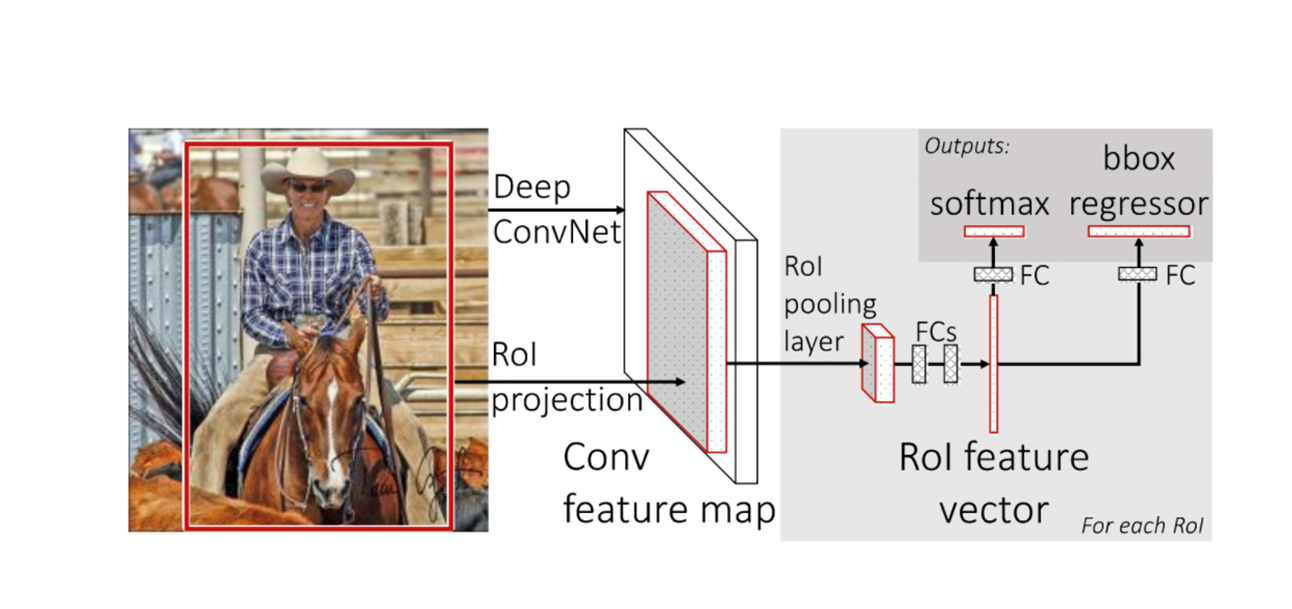
- RCNN과 Fast RCNN 모두 Region proposal + classification의 2-stage로 작동
- 정확도는 높지만 항상 candidate를 여럿 만들기 때문에 inference 시간이 오래걸림
YOLO (You Only Look Once)
- Region proposal은 그만. 여기서 속도가 오래 걸림
- 입력 이미지를 처음부터 grid로 나누고 각 grid별로 bounding box와 class를 예측
- 이 때 각 box 별 confidence도 함께 예측하게 함.
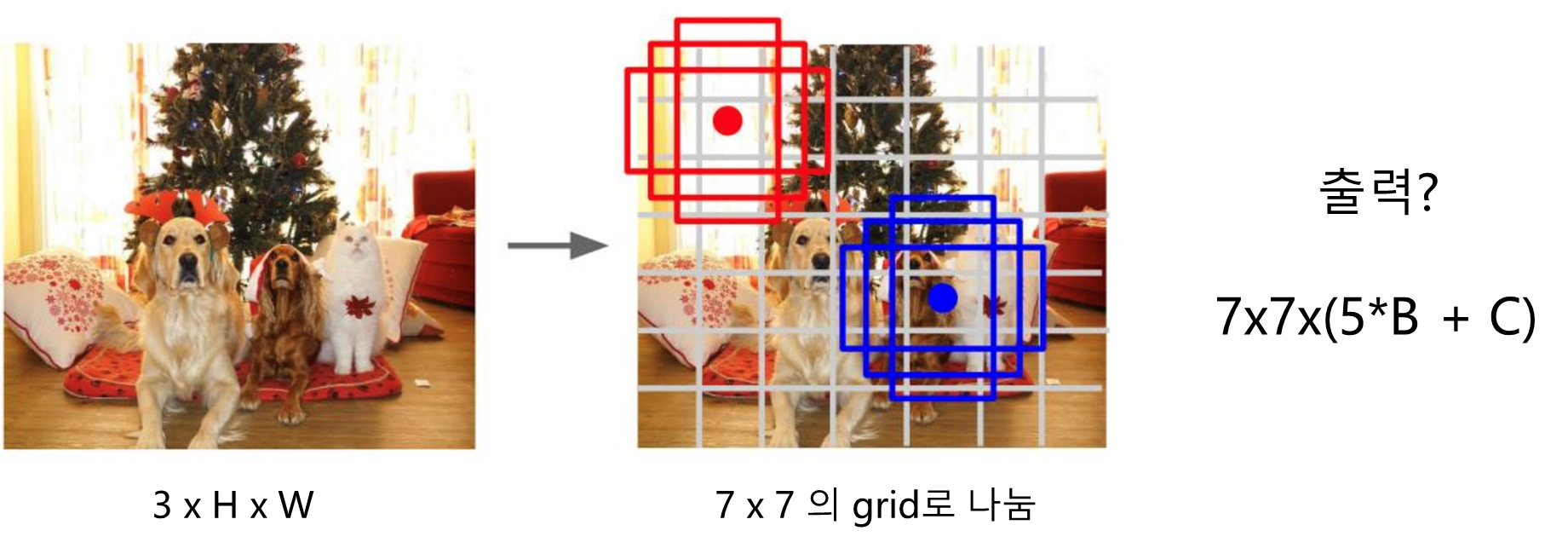
- 7x7 : grid 개수
- 5 : (x,y,w,h,confidence)
- B : object 개수
- C : class 개수
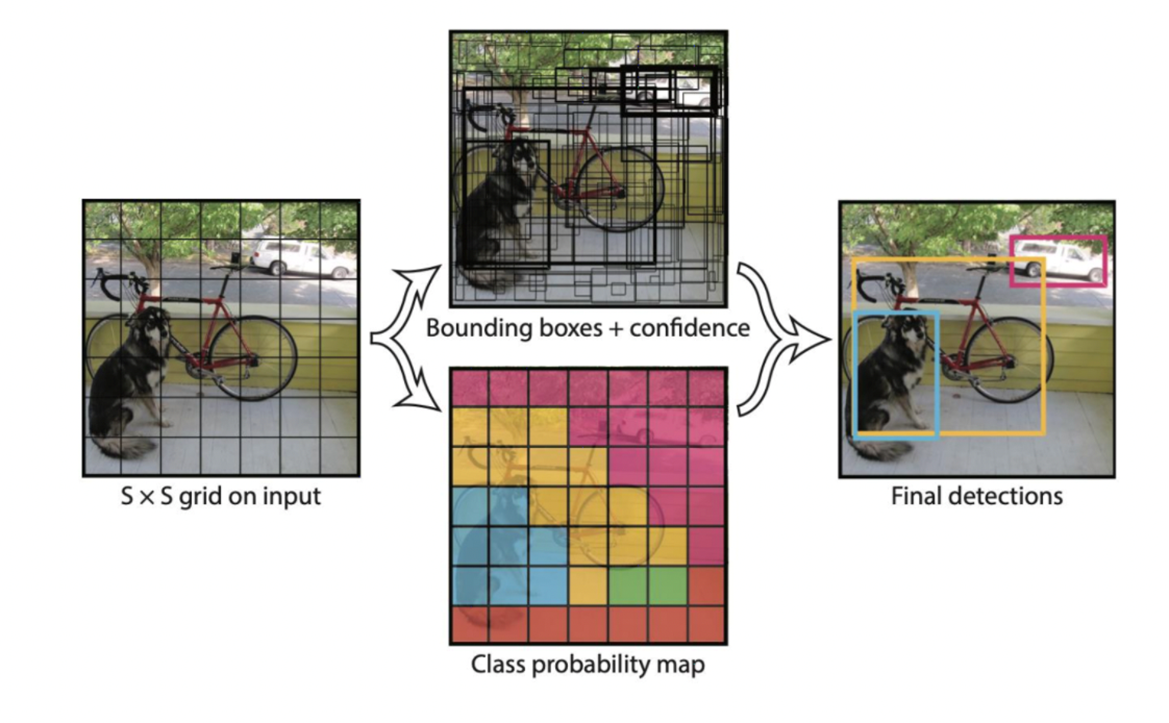
- grid 마다 grid를 중심점으로 둔 Bounding Boxes를 굉장히 많이 만듦
- grid 마다 class를 예측
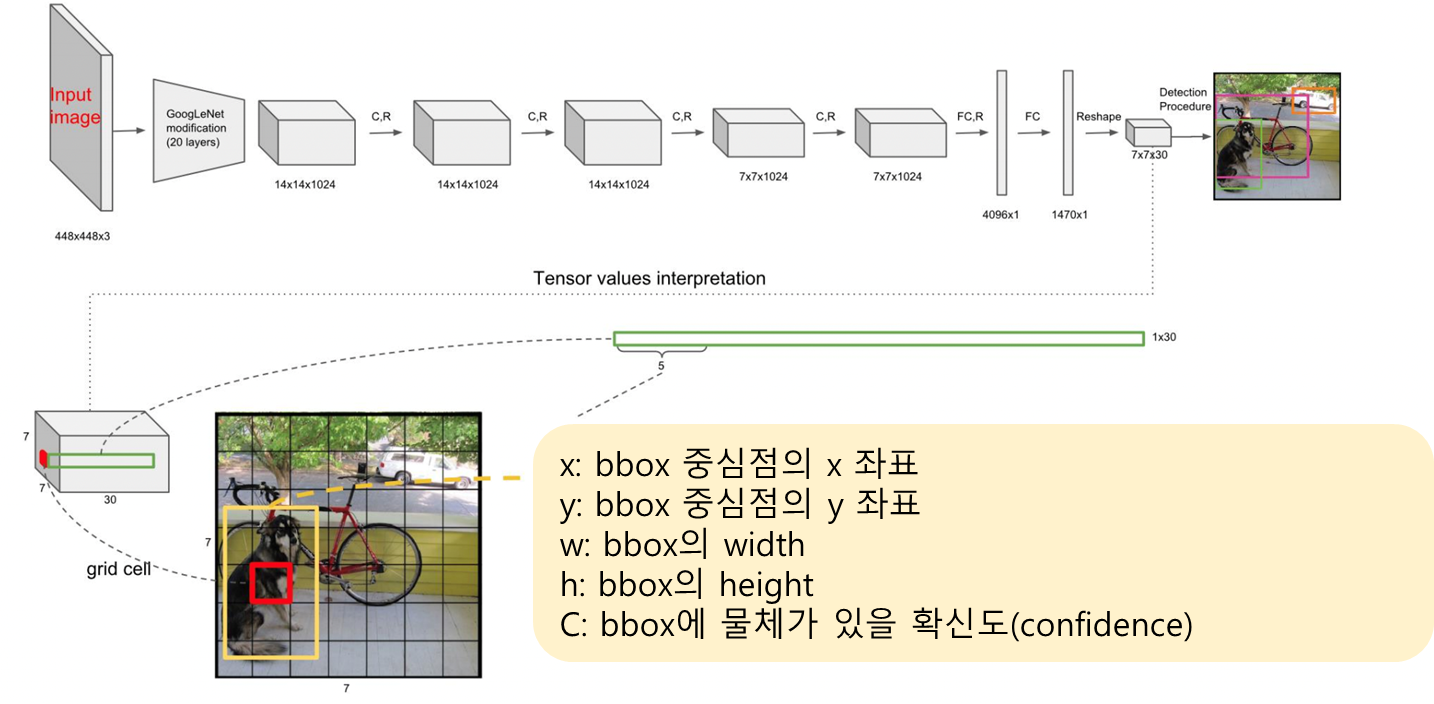
- Reshape 전까지는 기존과 동일
- Reshape에서 7x7은 grid와 동일
- Reshape에서 30은 5*B + C와 같은데 위의 그림에서 B = 2, C=20이라고 가정
- 2개의 object를 예측, 20개의 클래스가 있다고 가정
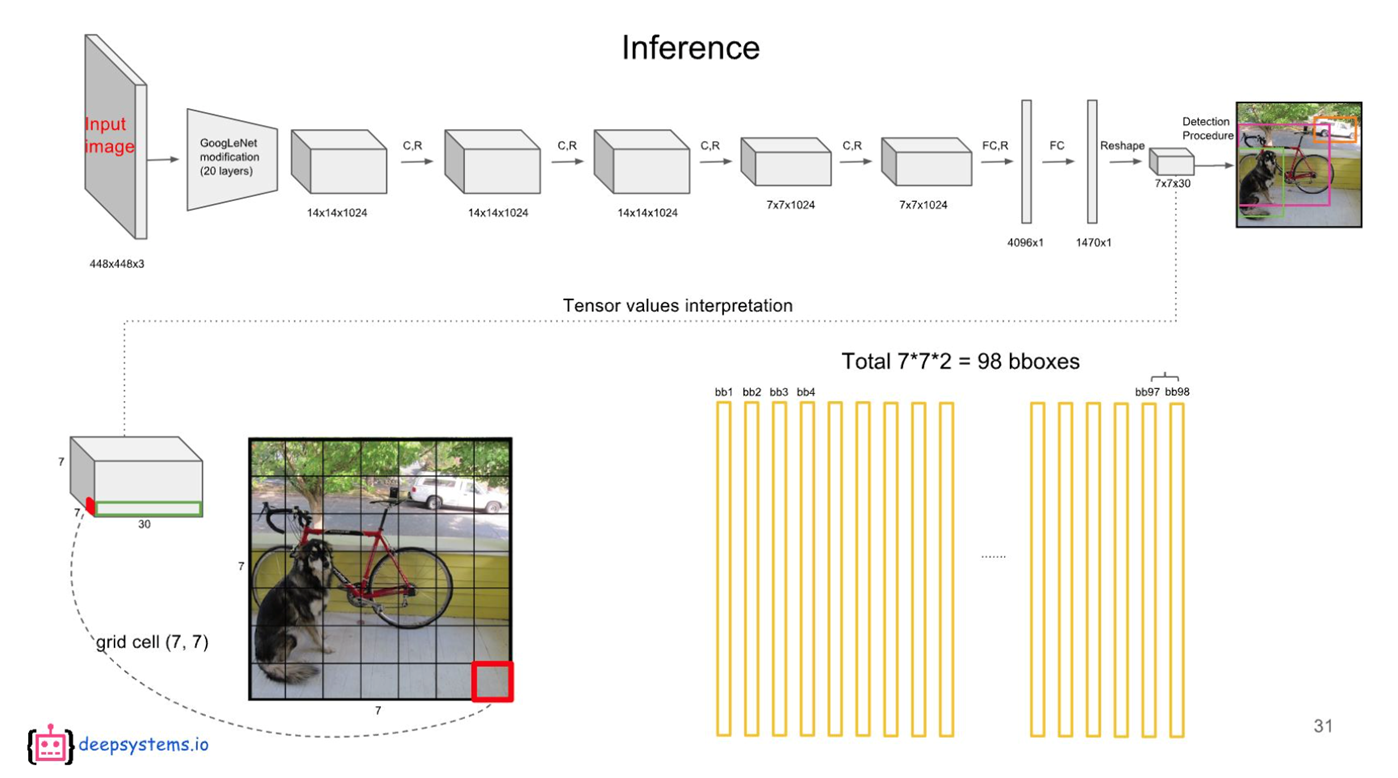
- 각 cell 마다 2개의 bbox를 예측해, 98개의 class score vector를 얻음.
- 98개가 중복된 것들이 여러개 있을 수 있음.
- NMS(Non maximum suppression)으로 다시 정제
- 동일한 객체에 대해 겹치는 정도(IOU; Intersection of Union)가 놓은 순서대로 정렬
- Score가 가장 높은 경계 상자를 기준으로 Threshold를 설정해 후보군을 줄임

- Score가 가장 높은 경계 상자를 기준으로 Threshold를 설정해 후보군을 줄임

SSD (Single Shot multibox detector)
-
RCNN과 같이 region proposal 과정을 거치지 않고 1-stage로 모델 진행
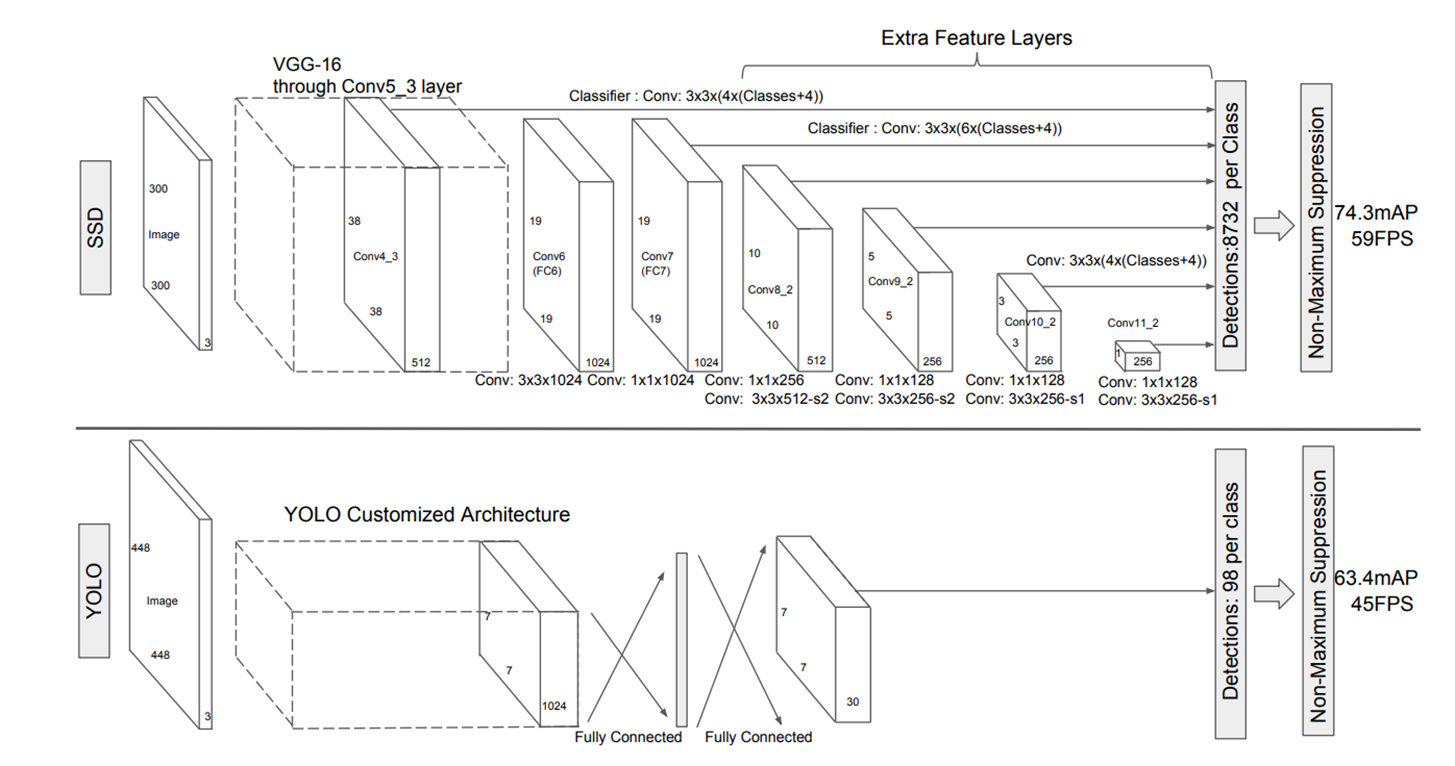
-
저해상도에서 잘 되어서, 낮은 resolution의 input을 받음

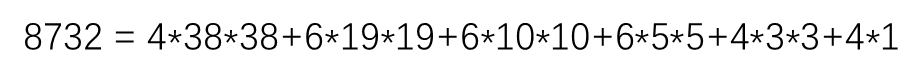
-
+4 : x, y, w, h
-
Layerwise하게 나오는 response (feature map)을 모두 feature extraction으로 활용
-
Multi-scale feature maps for detection
-
OverView

-
Detail
-
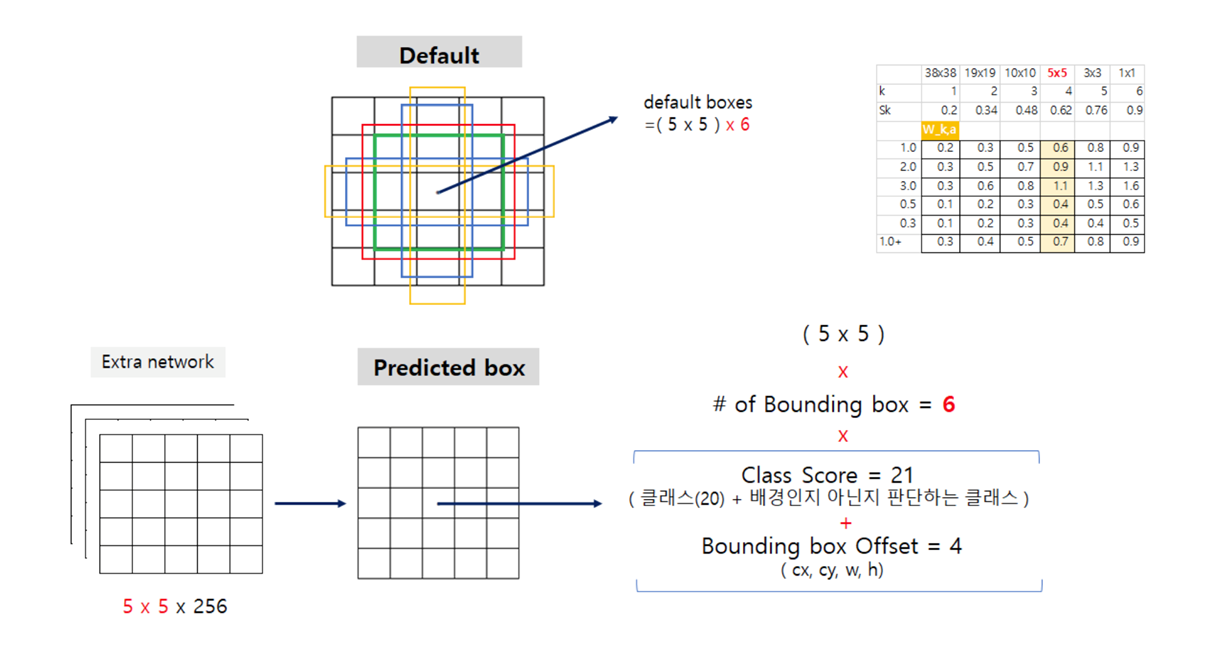
5x5x256의 object detection 과정을 보면
-
먼저, 5x5x6개의 default box를 generate
-
Default box는 비율과 크기가 각기 다른 기본 박스를 먼저 설정해 놓아서 Bounding Box를 추론하는데 도움을 주는 장치
-
SSD는 각각의 피쳐맵을 가져와서 비율과 크기가 각기 다른 Default Box를 투영
-
Default box와 ground truth 간의 겹치는 정도(IoU가 높은 것을 뽑음)
-
이후 걸러진 default box에 대하여 predicted bounding box와 매칭을 하고 loss를 계산
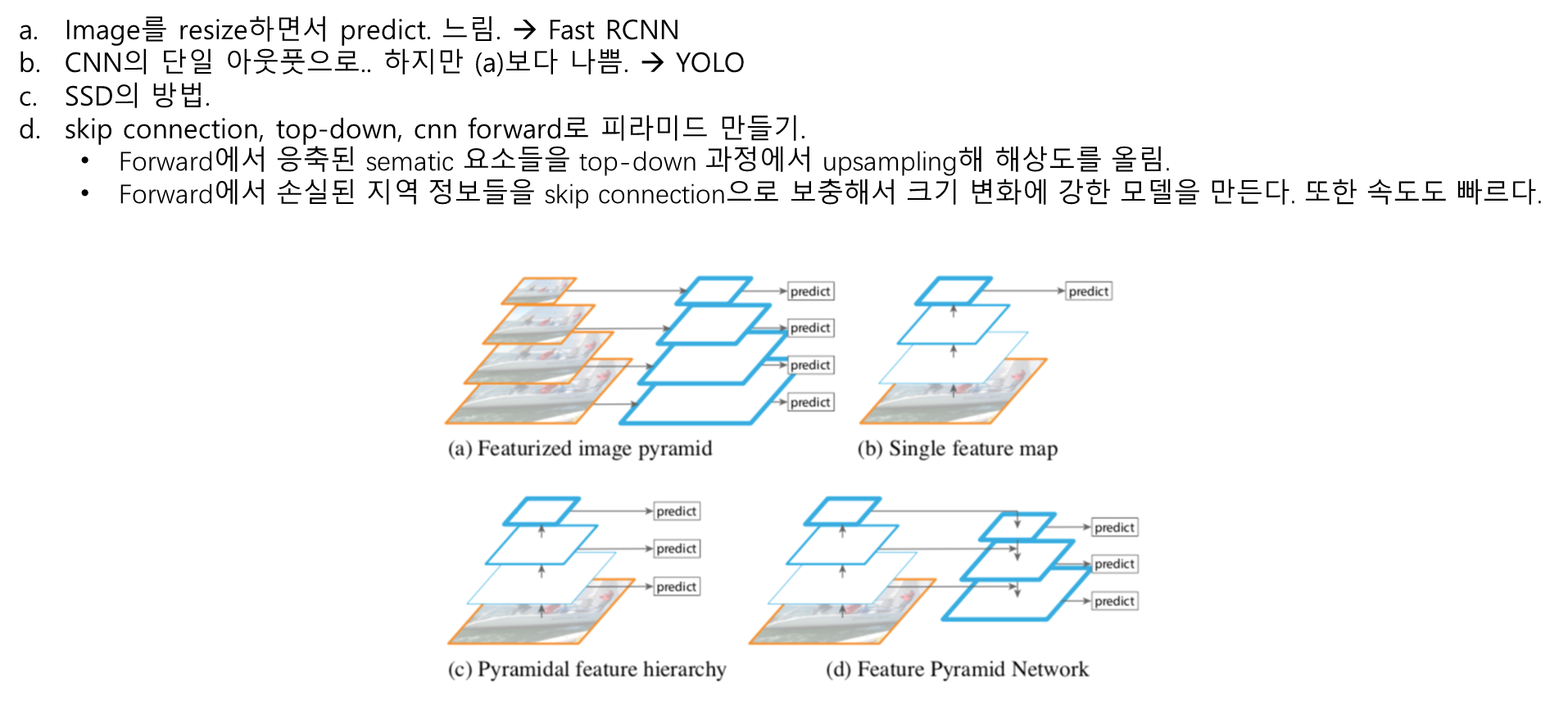
FPN (Feature Pyramids Network)


Sometimes You gotta run before you can walk.