Attention
Machine Translation:Inside
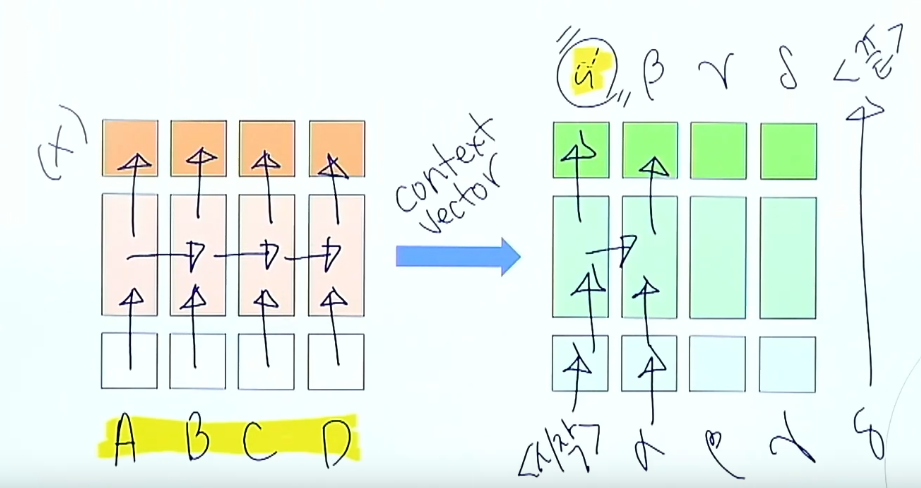
- 와 ABCD의 유사도를 비교
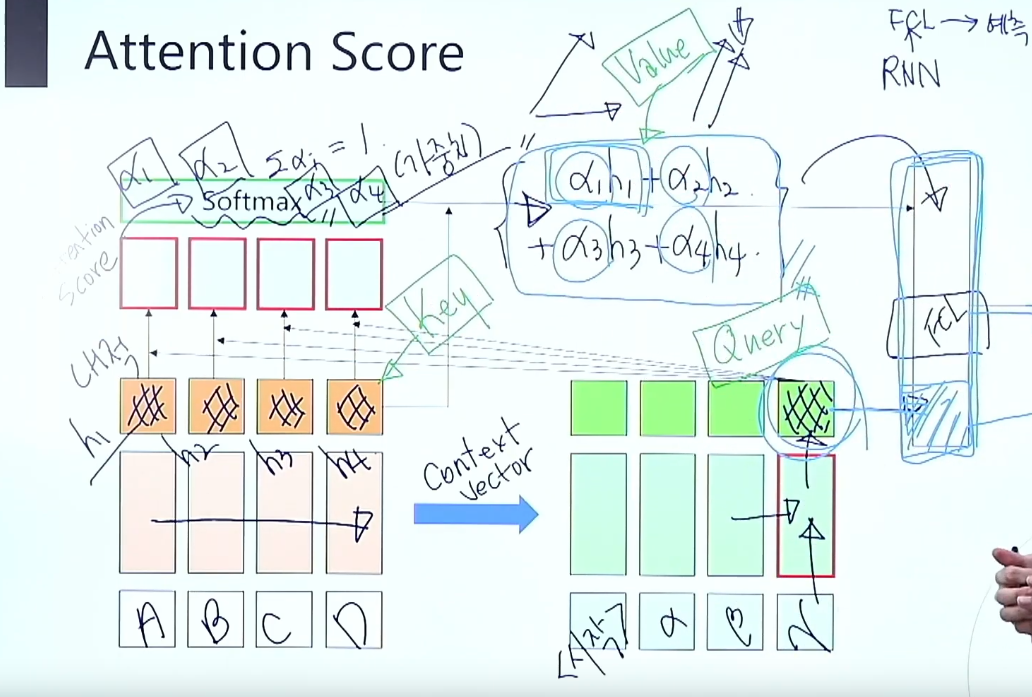
- Encoder의 hidden state h1, h2, h3, h4 ( Key )
- Decoder의 마지막 hidden state ( Query )
- Decoder의 hidden state(Query)와 encoder의 hidden state(Key)를 내적하여 Attention Score 구함
- Atention Score에 Softmax를 취하여 정규화
- Encoder의 hidden state와 Attention Score를 Weighted sum하여
- (Value) 구함
Attention in Seq2Seq
-
Attention Score를 구하는 유사도 h(enc) s(dec)
(1) Dot product
(2) Scaled Dot product
(3) Weighted Dot product -
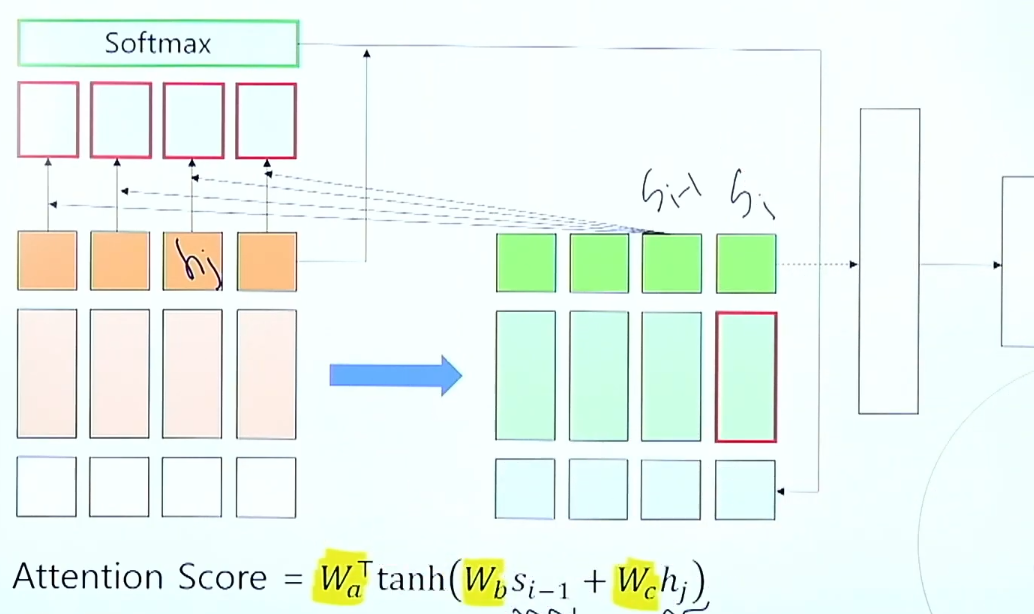
Bahdanau Attention
Transformer
- 문제 : 하나의 문맥 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
- 해결 : 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까?
Seq2Seq with Attention
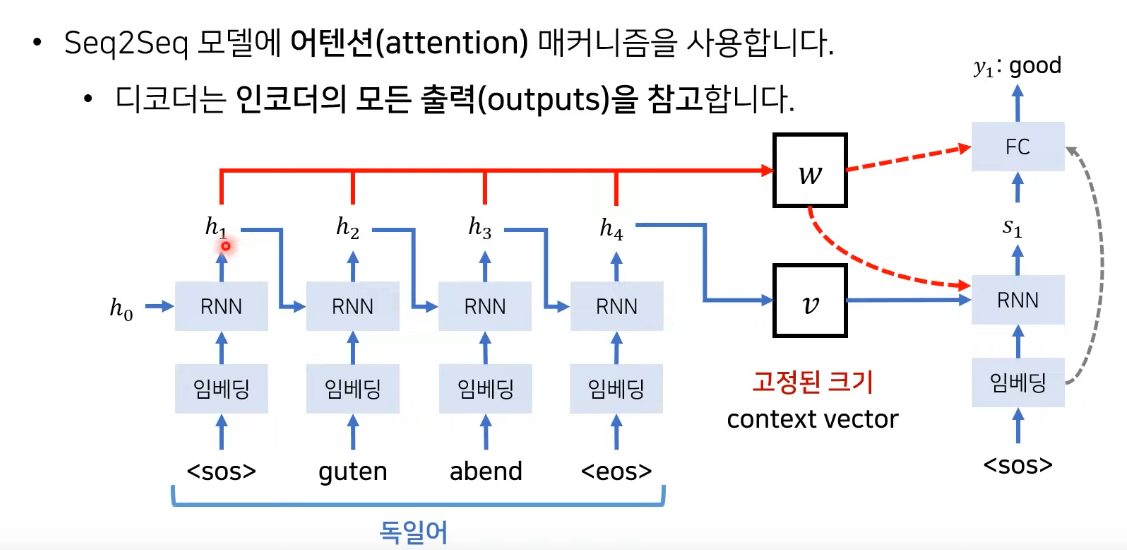
- encoder의 hidden state 값들을 매번 가지고 있음 --> w에 저장
- decoder는 매번 encoder의 모든 출력 중에서 어떤 정보가 중요한지를 계산
- i = 현재의 디코더가 처리 중인 인덱스
- j = 각각의 인코더 출력 인덱스
- 에너지(Energy)
--> decoder의 이전 출력 정보와 encoder의 모든 출력 정보(를 비교해 각각의 에너지 구함 - 가중치(Weight) --> softmax를 취한 %값
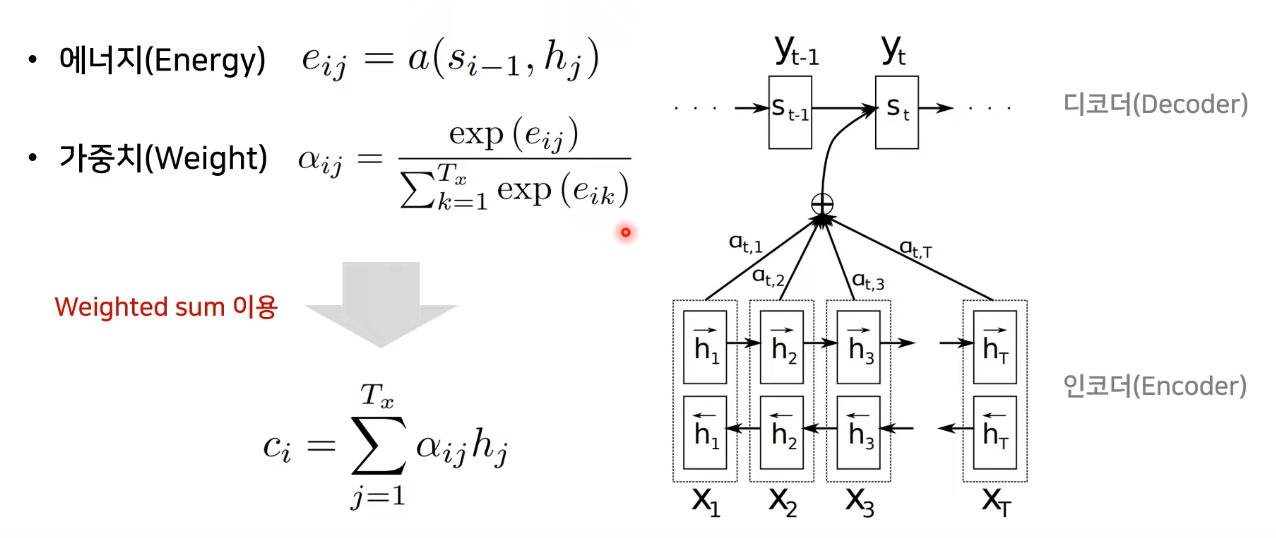
- 현재 state()를 구하기 위해서 이전 state(와 encoder의 hidden state들을 이용해 에너지 구함
- 에너지 값이 softmax를 취하여 비율값()을 구함
- 가중치()값과 encoder의 hidden state(h)의 weighted sum을 통해 만든 를 decoder에 입력으로 같이 넣어줌
Transformer
-
RNN이나 CNN을 전혀 필요 X
-
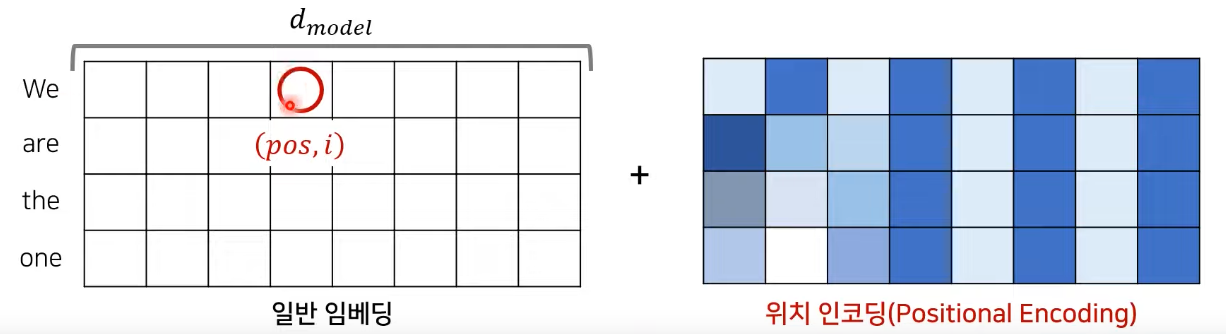
대신 Positional Encoding을 사용해 순서에 대한 정보 이용
-
Encoder와 Decoder로 구성됨
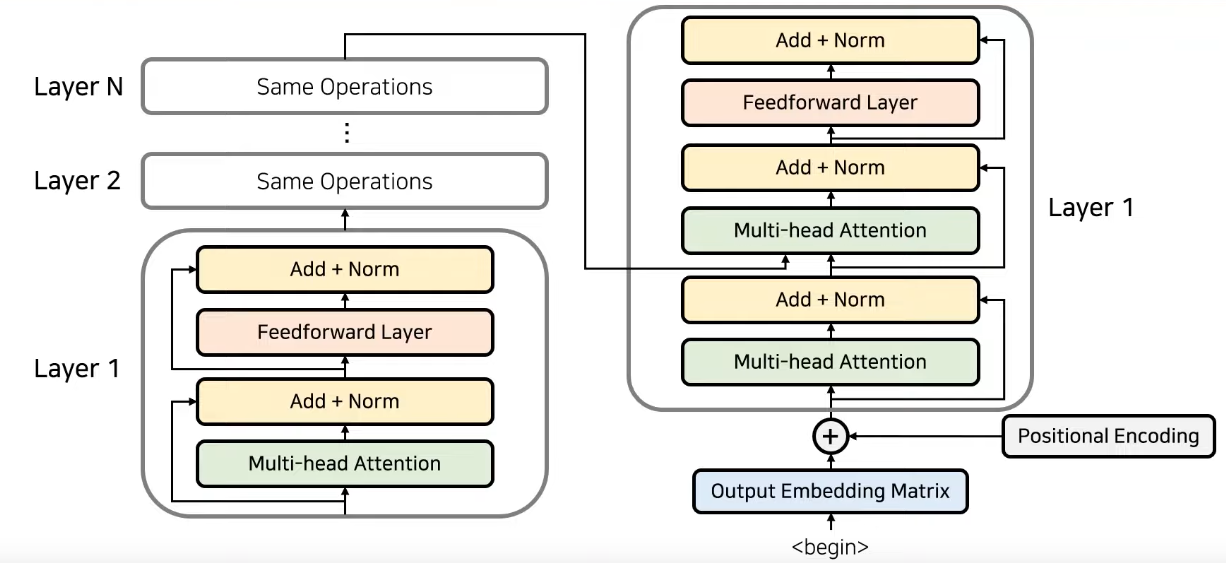
- Attention 과정을 여러 레이어에서 반복
- Attention 과정을 여러 레이어에서 반복
-
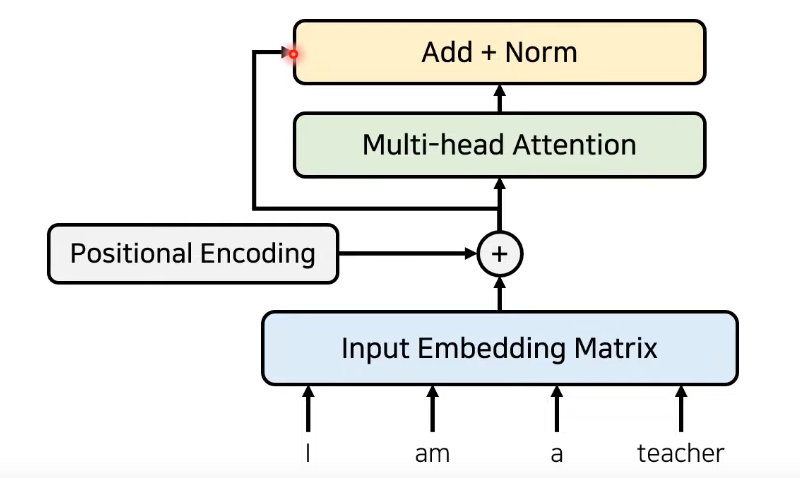
Input 문장을 Embedding Matrix 형태로 바꾸고 Positional Encoding 정보와 함께 Attention layer에 넣어줌
-
각각의 단어가 서로에게 얼마나 연관성이 있는지를 알기 위해 사용
-
입력 문장에 대해서 문맥의 정보를 학습하도록 만듦
-
추가적으로 잔여학습(Residual Learning)을 사용
- 기존 정보를 입력받으면서 추가적으로 잔여된 부분만 학습
- 초기 모델 수렴 속도
- global optima를 찾을 확률
-
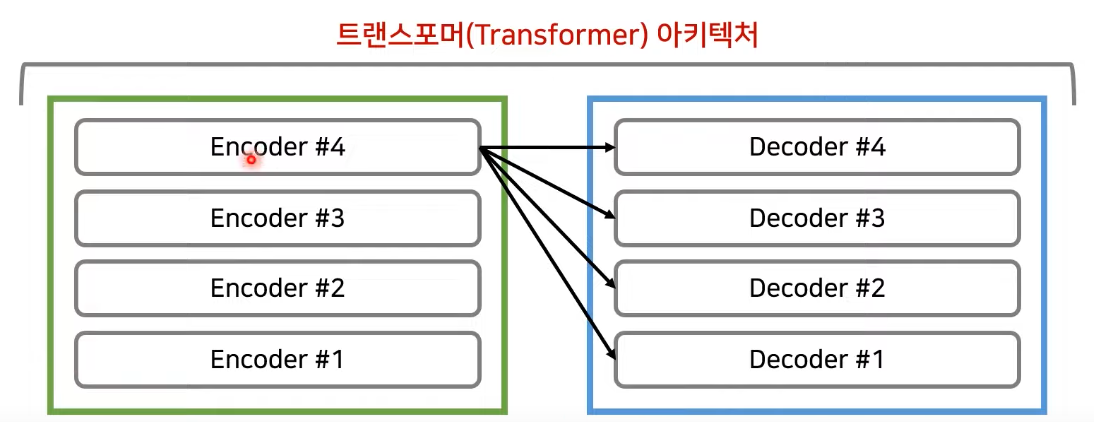
encoder의 마지막 레이어에서 나온 출력값을 매번 decoder layer에 입력으로
-
decoder의 layer 하나에는 2개의 Attention layer 사용
-
첫번째 Attention은 encoder와 마찬가지로 각각의 단어들이 서로가 서로에게 어떤 가중치를 가지는지 구해 출력 문장 표현 학습
-
두번째 Attention은 encoder의 정보를 Attention 할 수 있도록 즉, 각각의 출력 단어가 encoder의 출력 정보를 사용
--> 각각의 출력 단어가 saurce문장에서 어떤 단어와 연관 있는지 학습
-
encoder의 출력은 모든 decoder layer에 입력으로 들어감.
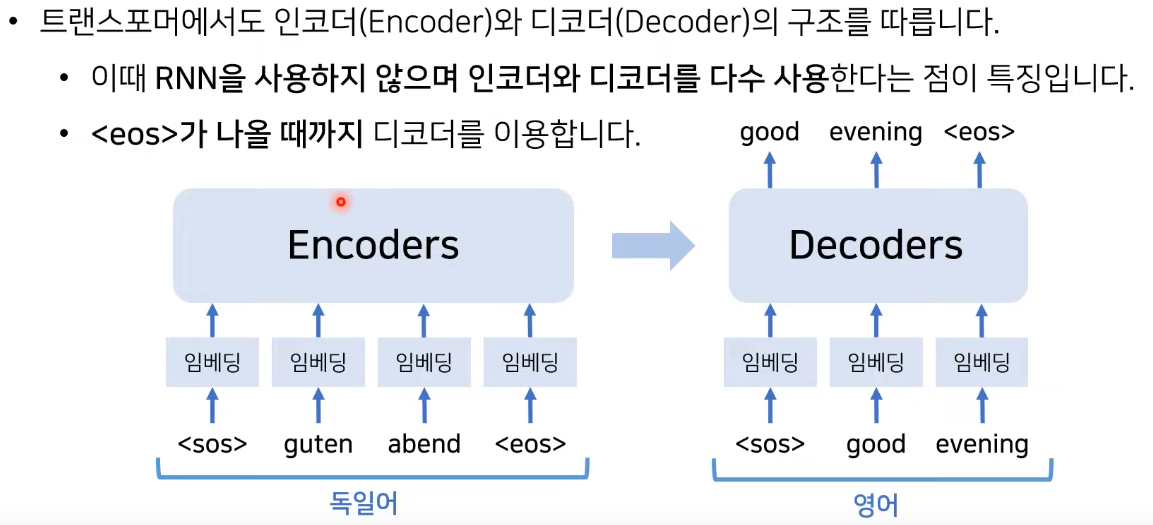
-
기존 RNN에 비하여 < eos >가 나올때까지 반복하지 않고, 문장을 한꺼번에 임베딩하고 Positional Encoding을 사용하므로 계산 복잡도가 낮음
-
decoder의 경우 < eos >가 나올때까지 반복함.
-
context vector를 사용하지 않기에 네트워크에서 RNN 구조 사용할 필요 X
ex) I am a teacher에서 I, am, a, teacher 단어가 각각 얼마나 연관성을 가지는지 파악하기 위해 self Attention을 사용 -
쿼리 : 물어보는 주체 ex) I
-
키 : 물어보는 대상 ex) am, a, teacher
-
값
-
쿼리와 키를 사용해 attention score를 구함
-
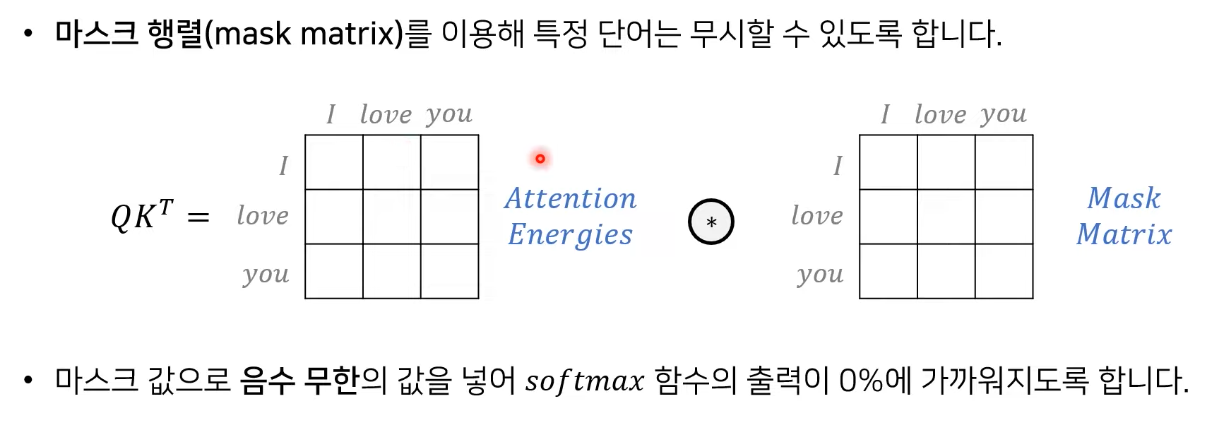
필요에 따라서 scale을 조정하고, Mask를 씌우고 Softmax를 취해 연관성을 확인
-
값을 곱해 최종 attention value를 구함
-
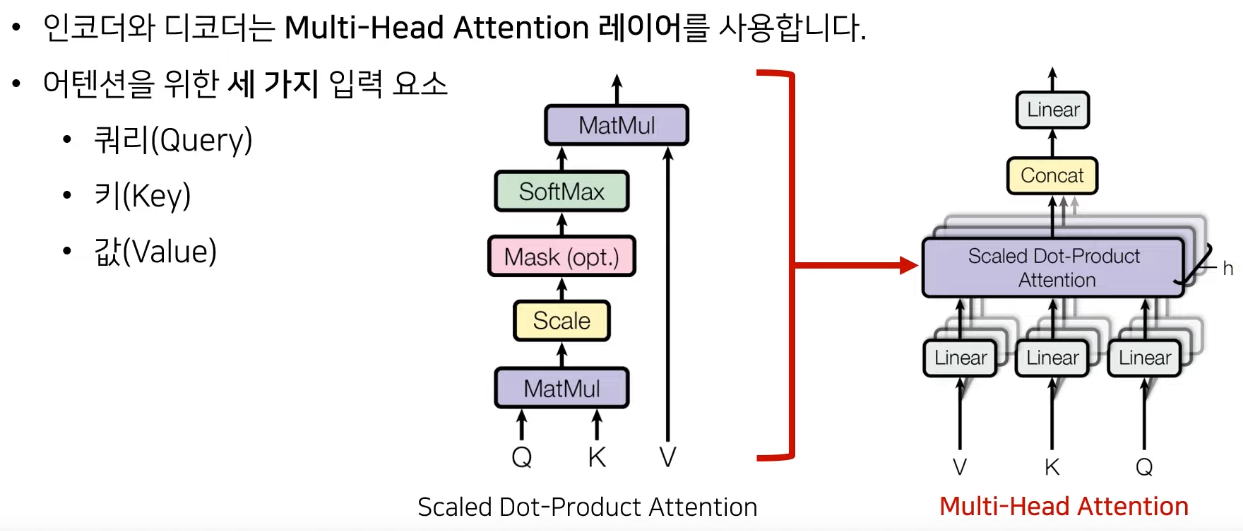
V,K,Q는 h개의 linear layer를 통과해 서로다른 V,K,Q를 이용해 Attention 컨셉을 학습해 다양한 특징 학습
-
모든 Attention의 동작 방식은 비슷하며
-
encoder, decoder의 Attention에서는 decoder의 출력 단어가 쿼리가 되고, 키와 값은 encoder에서 가져옴

-
Quary와 Key의 곱을 통해서 score를 구하고 scale factor인 d로 나누어주어(gradient vanishing 문제를 피하기 위해) softmax를 취하고 Value를 곱해주어 Attention Score를 구함
-
서로다른 linear레이어를 만들기 위해서 각각 다른 w를 곱해주어 head를 만듦
-
위 과정을 각각 진행하고 하나로 concatenate하여 다양한 feature 학습
트랜스포머의 동작 원리
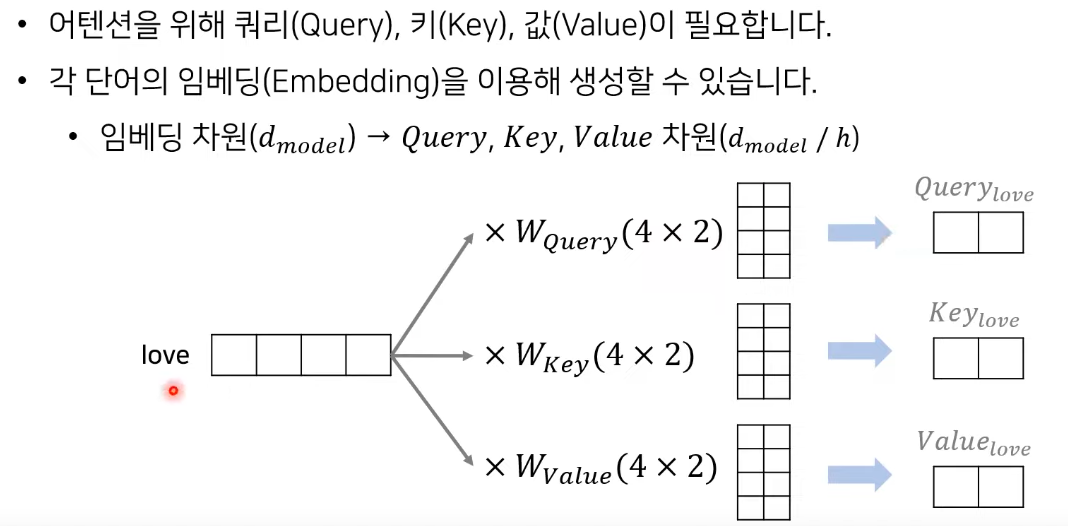
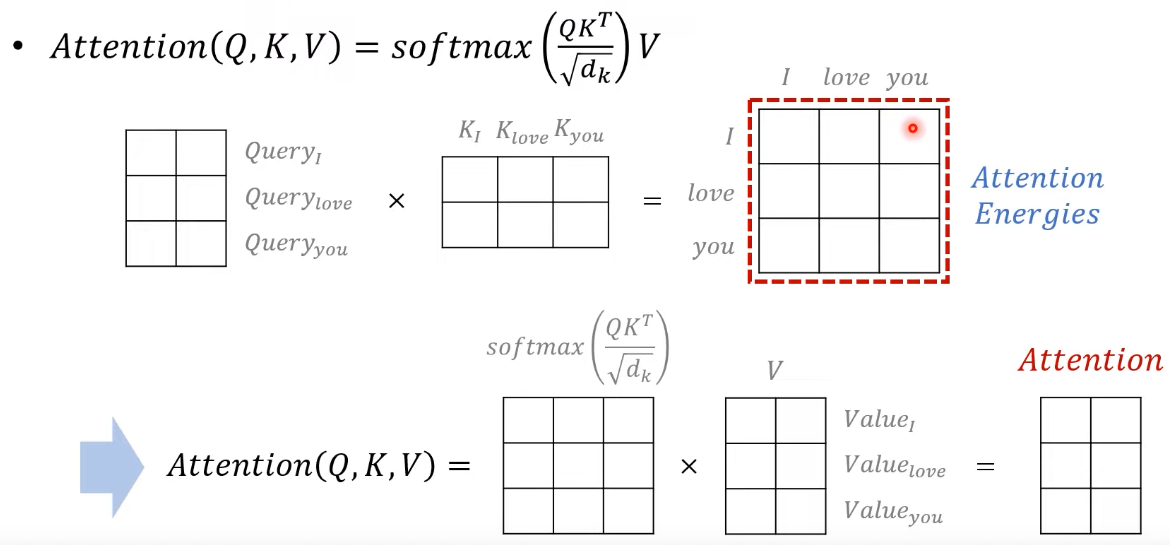
- love라는 단어가 4차원으로 임베딩 되어있다고 할때 linear layer를 통과하여 query, key, value 생성
- 이때 h: head 수

- query, key, value를 구하면 query와 각각의 다른 단어들 key와 행렬곱으로 attention energy 구함
- i라는 query와 i,love,you라는 key와 행렬곱 후 scale factor로 나누어주고 softmax를 취해주어 가중치 구함
- 이에 value값을 곱해주어 최종 attention value를 구함
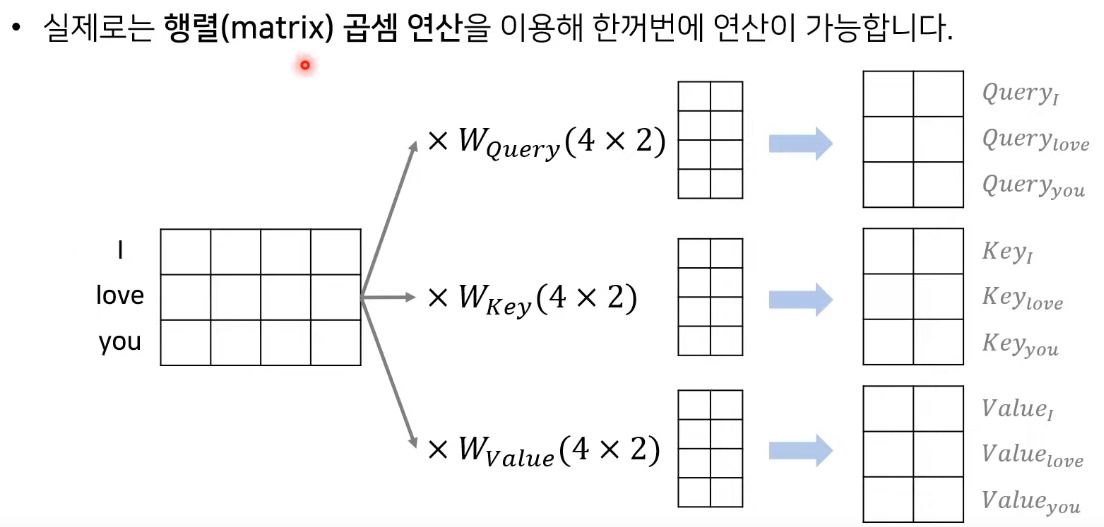
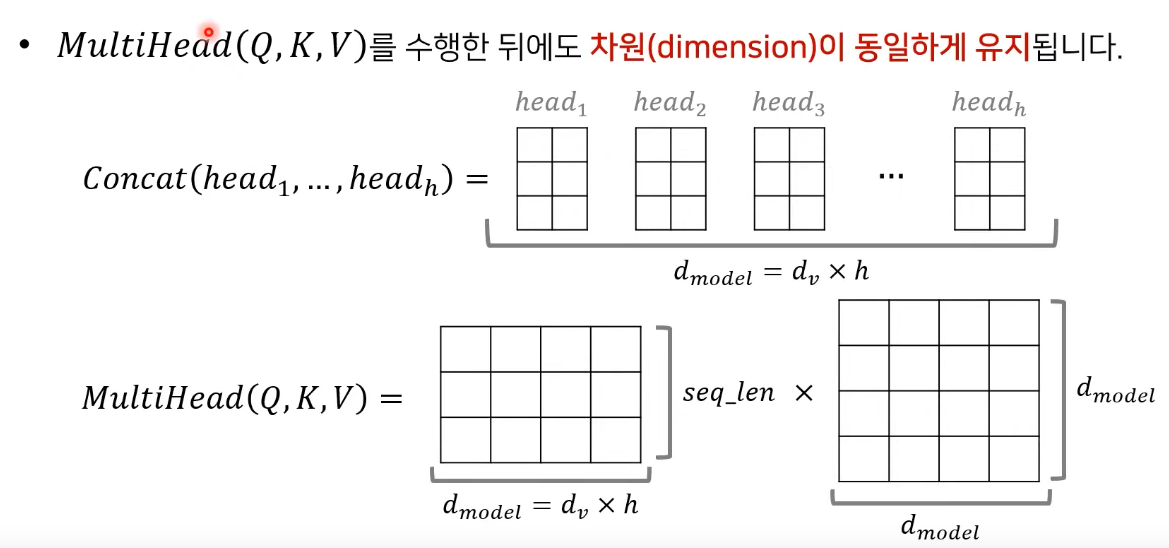
- 위에서 dimension을 h로 나누어 주었던 것을 다시 concatenate하므로 차원이 동일하게 유지됨
- transformer에 사용되는 attention은 항상 multi-head attention
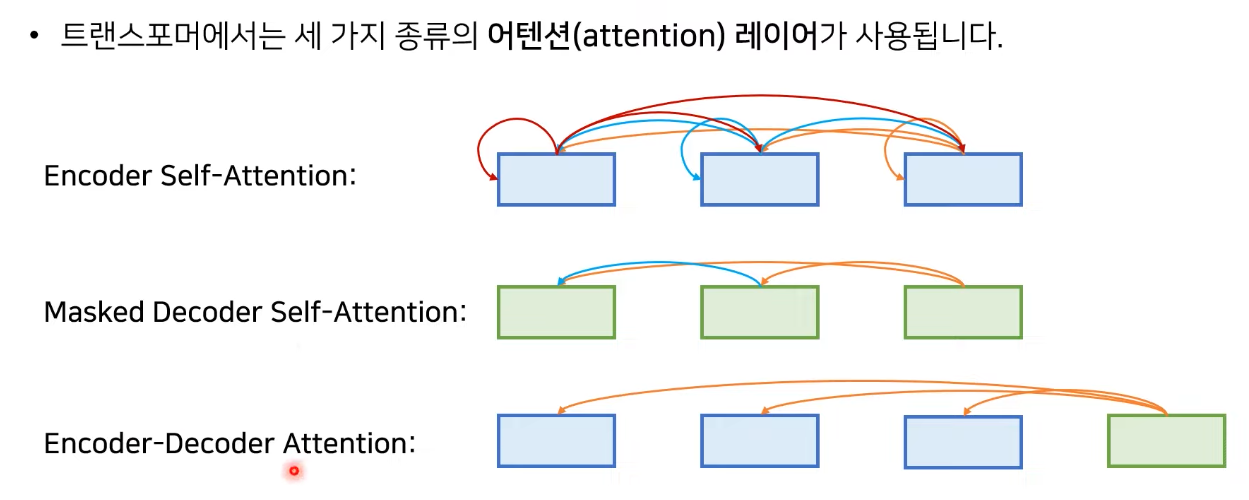
- 위치에 따라서 세가지로 분류
- Encoder Self-Attention은 각각의 단어가 서로에게 얼마나 영향을 미치는지, 전체 문장의 representation을 학습
- Masked Decoder Self-Attention은 Decoder 부분에서 뒷단어를 cheating하지 않게 앞쪽 단어만 참고
- Encoder-Decoder Attention은 쿼리는 Decoder에 key와 value가 Encoder에 존재

- 다른 모든 단어에 대해서 Attention score를 구할 수 있음.
Positional Encoding
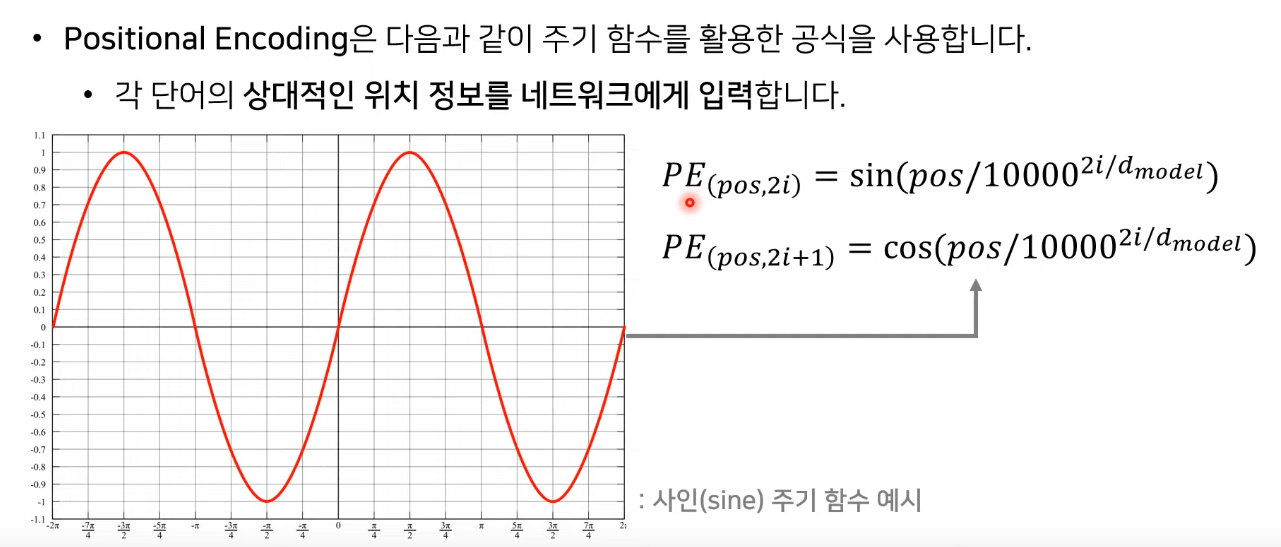
- PE : Positional Encoding의 약자
- pos : 각각의 단어 번호
- i : 각각의 단어에 대한 임베딩 값의 위치
BERT
GPT
