
Abstract
- 이미지 처리 업무에서 이미지를 다른 스타일로 변환시키는 것은 어려운 일이다. 그동안의 접근은 이미지와 콘텐츠 분류를 가능하게 하는 representations가 부족했다. Object Detection을 위한 CNN 기반 이미지 representaitons를 사용해 높은 수준의 이미지 정보를 이용했다. 이를 통해 유명작가의 작품과 높은수준으로 결합되 이미지를 만들어내는 것이 가능하다.
1. Introduction
-
스타일 변환은 텍스쳐 변환 문제로 생각될 수 있다. 소스 이미지의 콘텐츠를 보존하면서 텍스쳐를 합성해 타겟 이미지를 만들어내는 것이 목적이다. 소스 텍스쳐의 픽셀을 resampling하여 원본 사진에 학습하는 non-parametric 알고리즘도 많이 있으며 콘텐츠 정보를 보존하는 여러 방식의 알고리즘이 있다.
-
이러한 알고리즘의 공통적인 한계가 하나 있는데 low-lever의 이미지 feature에서만 사용 가능하다는 것이다. 우리는 의미있는 콘텐츠 정보도 필요하다. 따라서 이미지 안에서 콘텐츠와 스타일의 독립적인 이미지 representations가 필요하다.
-
원래 이미지에서 스타일로부터 콘텐츠 분리는 매우 어려운 일이었다. 그러나 Deep Convolutional Neural Networks는 가능하다. 객체인식 같이 특정 task에 충분한 양으로 라벨된 데이터들로 학습된 CNN은 높은 수준의 이미지 콘텐츠를 추출해낸다.
-
Style Transfer는 최신 CNN에서 얻은 feature representations로 텍스쳐를 합성하도록 하는 알고리즘이다.텍스쳐 모델은 딥러닝 기반이라서 Neural Network에서 최적화 문제를 줄이는 식으로 학습된다.
2. Deep image representations
- 아래 나타난 결과는 Object Detection과 localisation을 위한 VGGNet을 기반으로 만들어졌다. VGG19의 16 layer와 5개의 pooling layer의 정규화된 feature space를 사용했다. 이미지와 위치에 대한 평균 activation이 1이 되도록 normalize했다. feature map을 풀링하거나 정규화하지 않고 linear activation fuction을 조절해 output은 바뀌지 않는다. FCN을 사용하지 않았고 Caffe framework으로 개발했으며 성능이 더 좋았던 average pooling을 사용했다.
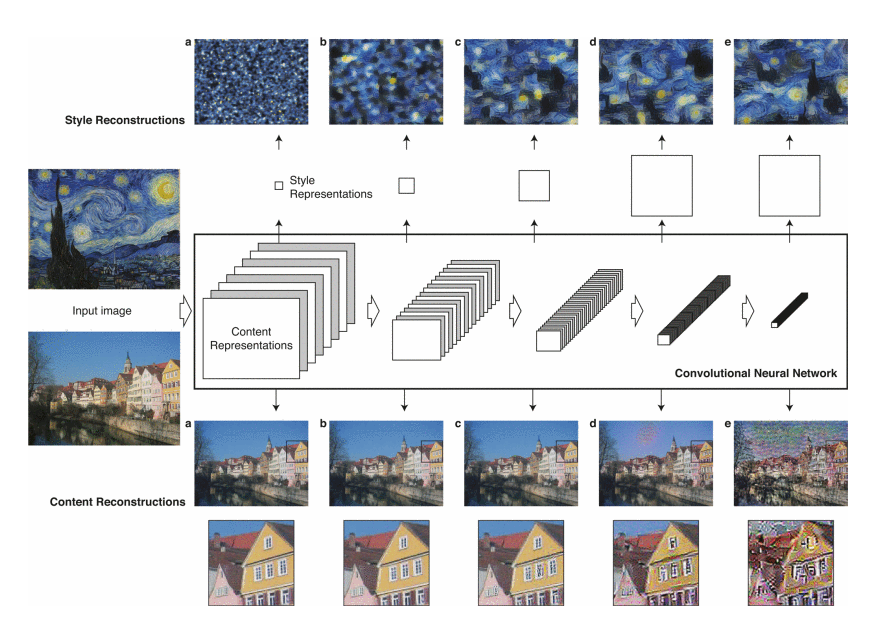
2.1 Content representation
-
일반적으로 non-leaner 필터를 쌓은 레이어들을 Neural Network에 배치해 복잡도를 높인다. 이렇게 인풋 이미지 는 CNN의 각 레이어에서 encoded된다. 개 레이어에서 X 의 사이즈를 갖는 feature map을 가짐.
-
층 구조에서 embedded 된 이미지 정보를 시각화하기 위해서 화으트노이즈 이미지가 원본 이미지와 대응 되도록 Gradient descent 실행. 는 원본 이미지이고, 는 생성된 이미지라고 할때, 과 을 각각 레이어에서 얻을 feature representations라고 한다. 이를 squared-error를 취하여
-
-
임의의 이미지 를 특정 레이어의 원본 와 대응하도록 학습한다. 객체 인식으로 학습된 모델은 층을 지날수록 객체 정보를 잘 표현하여 물체의 배치를 잘 잡지만 픽셀단위로 정확한 위치를 얻지는 않는다. lower layer일때는 원본 이미지와 비교해 픽셀단위로 정확하게 새로운 이미지를 생성하지만 콘텐츠 적 의미는 별로 같지 못한다.
-
--> layer가 깊어질수록 물체의 배치 , 정확한 외관
-
--> layer가 얕아질수록 물체의 배치 , 정확한 외관
2.2 Style representation
- 이미지에서 style representation을 얻기 위해서 텍스쳐 정보를 얻도록 feature space을 디자인했다. 이러한 feature space는 네트워크의 어느 레이어에도 필터를 통과한 이후에 적용할 수 있다. feature space는 서로 다른 필터 통과 결과의 상관관계에 의해 구성되는데, 피쳐맵의 공간적 범위에 의해 취해진다. 이러한 feature 상관관계는 Gram matrix에 의해 layer l 에 있는 vectorised feature maps i와 j의 내적으로 얻어진다.
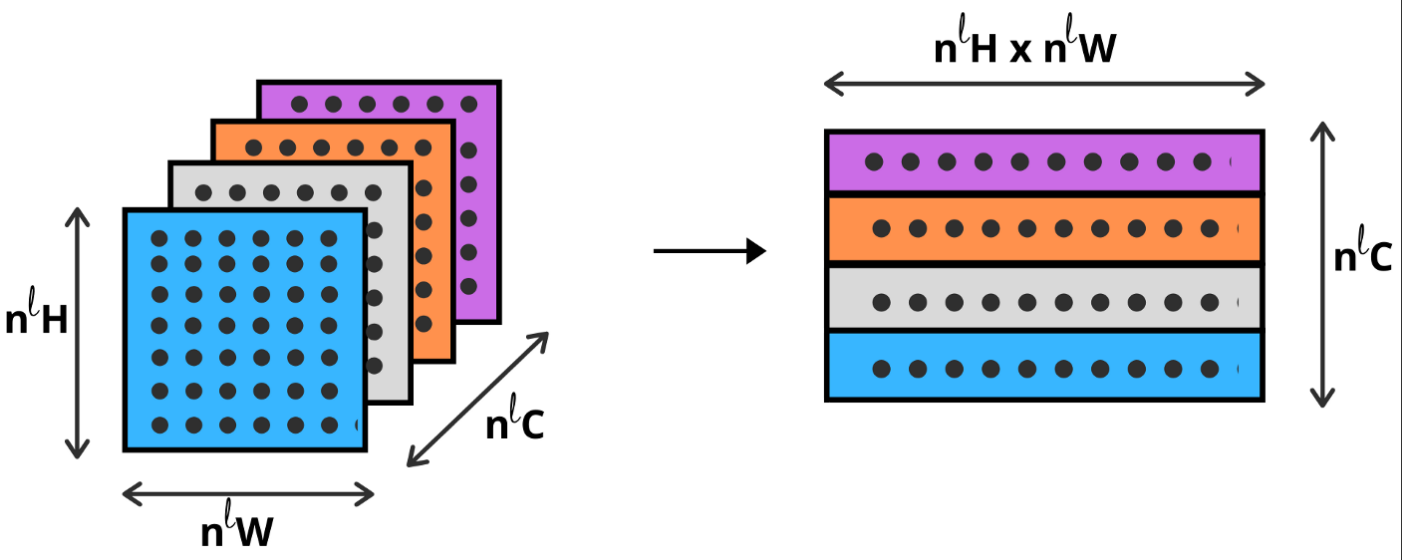
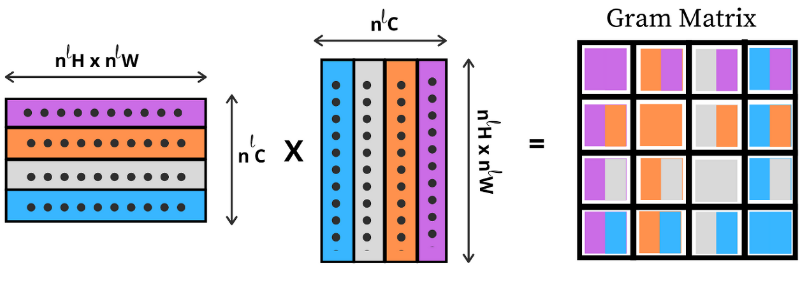
- 여러 레이어들의 feature 상관관계를 이용해 이미지의 multi-scale representation 정보를 얻는데 이는 전체적인 배치보다는 texture 정보이다. 다시 말해 input 이미지의 style representation과 대응하도록 이미지를 만드는 네트워크에서 다르게 구성된 레이어인 style feature spaces에서 얻은 정보를 시각화 할 수 있다. 이는 white noise 이미지를 gradient descent 할 때 생성된 이미지의 gram matrices와 원본 이미지의 gram matrices의 mean-squared가 최소화 되도록 한다.
2.3 Style transfer

- 의 그림으로 의 그림 스타일을 적용시키려면 의 콘텐츠 representations과 의 스타일 representations을 동시에 대응하는 새로운 이미지를 합성해야한다. 따라서 한 레이어에서 이미지의 콘텐츠 표현과 레이어들에서 스타일 표현으로부터 화이트 노이즈의 feature representations의 거리를 줄인다.
- 와 는 콘텐츠와 스타일의 상대적 가중치 요소이다. compute 하기 전에 resize를 통해 늘 같은 사이즈 이미지의 정보를 추출했다. 네트워크의 구조나 최적화 알고리즘의 차이로 이미지 합성을 할때 추가적으로 차이가 날 수 있다.
3. Results
- 본 논문에서 중요한 점은 CNN에서 콘텐츠와 스타일의 representations가 잘 분리 된다는 것이다. 즉, 두가지 representations를 독립적으로 이용해 새롭고 그럴듯한 의미있는 이미지를 만들어낼 수 있다. 이를 증명하기 위해 두개의 소스 이미지들의 콘텐츠 representations와 스타일 representations를 섞어서 이미지를 만들어내는 것을 보였다. 게다가 독일의 Tubingen에 있는 Neckar 강가의 강변지대를 묘사한 그림의 콘텐츠 representations와 잘알려진 유명한 예술작품의 stype representations를 대응했다. content representation은 conv4_2 layer에서 얻었고, style representation은 conv1_1,conv2_1,conv3_1,conv4_1,conv5_1에서 얻었다.

3.1 Trade-off between content and style matching
- 당연히 콘텐츠와 스타일은 완벽하게 섞일 수 없다. 그러나 스타일이나 콘텐츠 둘 중 하나의 loss fuction에 집중하여 상대적으로 강조할 수 있다. 콘텐츠에 집중하지 않으면 텍스쳐의 성능이 올라간다. 하지만 콘텐츠에 집중하게 되면 텍스쳐의 성능은 떨어진다. 따라서 둘은 trade off 관계이다.
3.2 Effect of different layers of the Convolutional Neural Network
- layer를 선택하는 것 역시도 중요하다. 스타일 표현은 Neural Network의 여러 layer에서 multi-scale로 표현된다. layer들의 숫자와 위치는 로컬 스케일을 결정하고 그에 따라서 다른 결과가 나타난다. 상층부까지 스타일 표현을 하면 더 큰 규모의 로컬이미지 구조를 보존할 수 있고, 더 자연스럽고 부드럽게 시각적을 보인다. 따라서 시각적으로 매력적이게 보이려고 conv1_1~conv5_1의 레이어들의 style features를 사용했다.
- layer 차이 분석을 위해서 동일 작품, 동일 파라미터로 style transfer를 수행했고, content의 conv4_2와 conv2_2차이를 두었다.
--> 하층 : 그림에 텍스쳐 섞은 느낌 --> 디테일 픽셀 정보 O
--> 상층 : 그림 + 텍스쳐가 합쳐짐 --> 디테일 픽셀 정보 X
좋은 구조는 그림의 콘텐츠는 나타나면서 작품의 스타일링을 얹어 선과 칼라맵등이 대체되어야 한다.

3.3 Initialisation of gradient descent
- 시작 이미지를 화이트 노이즈로 시작을 했지만, 콘텐츠나 스타일 이미지를 시작 이미지로 넣을 수도 있다. 결과 이미지는 처음 넣은 이미지의 공간에 치우쳐짐이 있긴 했지만 큰 차이는 없어보였다. white noise로 시작했을때 임의의 새 이미지를 생성 가능하며 정해진 이미지로 시작을 하면 같은 결과가 나왔다.(SGD 과정 때문에)

3.4 Photorealistic style transfer
- 지금까지는 예술 작품의 스타일 변경에 포커스를 두었지만, 임의의 두 그림에도 적용 가능하다. 뉴욕의 밤과 런언의 아침 사진에 적용을 시켜 보았다. 사진의 사진감이 다 보존된건 아니지만 스타일 이미지의 색, 빛을 어느정도 잘 합쳤다.

4. Discussion
- 본 논문은 임의의 사진들을 CNN으로 만든 Feature representation을 이용해 스타일 바꾸는 법을 모여주었다. 높은 수준의 결과물을 보여주기는 했지만 어느정도 기술적 한계가 존재했다.
- 먼저 합성 이미지 해상도 몬제가 대부분이었다. 최적화 문제의 차원성과 CNN의 유닛 수는 픽셀수가 증가함에 따라서 선형적으로 증가했다. 이미지 해상도에 따라 합성 속도가 결정되는데 본 논문에서는 512x512크기의 이미지를 생성하는데 Nvidia K40 GPU를 사용해 1시간 정도 걸렸다. 따라서 온라인 또는 즉각적 상호작용이 현재는 어렵지만 미래에는 성능이 향상 될 것으로 보인다.
- 또 다른 문제는 가끔 낮은 수준의 노이즈에 노출되는 건데 에술 작품에서는 별 문제가 없었지만, 사진의 경우에는 어느정도 영향이 있었다. 노이즈는 매우 특징적이고 네트워크의 유닛들의 필터를 모을때 나타나므로 최적화 후 영상 후처리하는 효율적 노이즈제거 기술을 구성해 해결 가능해 보인다.
- 작품 스타일링은 Non-Photorealistic-Rendering이라는 이름으로 컴퓨터 그래픽스에서 공부해왔다. 텍스쳐 변환을 제외하고는 컨셉이 매우 달랐다.
- 콘텐츠에서 스타일을 분리하는 것은 잘 정의된 문제는 아니다. 이미지의 스타일을 정의하는게 모호하기 때문이다. 붓질, 칼라맵,물체의 형태, 장면의 구성, 주제 선정 뿐 아니라 그 이상의 것들도 스타일이 될 수 있다. 따라서 콘텐츠 스타일 분리는 깔끔하게 되지 않는다. 따라서 만들어진 이미지에서 콘텐츠가 보이며 스타일처럼 보이게 하는 것이 중요하다. 사실 정확한 기준을 가지고 평가를 내리는 것은 본인들도 모른다.
- 그럼에도 우리가 생각하기에 이미지의 콘텐츠와 스타일을 분류하는 Neural system은 매우 매력적이다. Object Detection을 위해 학습된 모델로 이미지에서 contents 정보를 잘 찾아낸다. 이미지 내용의 변화와 그 모양의 변화를 쪼갠 representations는 이 작업에 매우 실용적이다. 인공 신경망과 생물학적 시각이 서로 비슷한 기능을 하기 때문에, 인간의 시각 체계도 이러한 기능을 가지고 있어서 예술을 즐길 수 있는 것이라고 생각된다.
