[paper review] 3D human pose estimation in video with temporal convolutions and semi-supervised training
Paper Review
Abstract
우리는 비디오에서 dilated temporal convolutions을 사용해 효과적으로 3d 포즈를 추정해냈다.
또한 라벨되지 않은 비디오를 semi-supervised 학습 시킬 수 있는 back-projection을 소개한다.
unlabeld video에서 2d pose를 얻고 3d pose를 추정해 다시 2d로 back-project한다.
1. Introduction
Rnn은 여러프레임을 동시에 처리하는 것이 안되지만 Convolution에서는 가능하므로 우리는 temporal convolution을 수행하는 fully convolutional architecture를 제안한다.
모든 2d keypoint detector와 호환가능하며 dilated convolution을 통해 큰 context도 효과적으로 다룰 수 있다.
unlabeled video와 카메라 내부변수를 활용해 준지도학습 방법을 소개한다.
2. Related work
2.1 Two-step pose estimation
먼저 2d keypoint를 추정하고 이를 3d keypoint로 올린다.
두 단계로 학습이 되어서 중간 감독 역할을 end-to-end의 성능을 능가한다.(2d_gt 사용할 경우)
knn, depth만 추정 등 다양한 기법이 사용 되기도 했다.
2.2 Video pose estimation
기존엔 프레임 하나를 이요했지만 최근 더 정교한 3d 추정을 위해서 temporal 정보를 사용한다.
그동안 LSTM의 seq2seq를 통해 많은 연구가 진행 되었지만 문제가 있었다.
제일 좋은 방식은 2d keypoint trajectories를 이용해 학습하는 것이다.
2.3 Semi-supervised training
GAN을 사용하면 2D annotation만 사용해서 실제 포즈를 구별해낼 수도 있다. 3D pose를 랜덤한 방향으로 2D projection하여 Weakly-supervised 접근을 하기도 하고 ordinal depth annotation을 통해 하기도 한다.
2.4 3D shape recovery
이미지로부터 3D pose를 정확하게 만드는 것과 동시에 사람 전체를 3D로 만드는 것 또한 연구되고 있다.
이는 파라미터화 한 3D 메쉬를 기반으로 하며, 동작의 정확도는 덜 중요하다.
2.5 Our work
heatmap을 사용하지 않고 이미 detected 된 keypoint를 시간 순서에 따라 1D convolution하여 사용한다.
이를 통해 해상도에서 계산 복잡도가 자유로워지고, 적은 파라미터를 이용해 더 빠르고 정확하게 학습과 추론이 가능하다.
3. Temporal dilated convolutional model
residual connections을 이용한 fully convolutional 구조로 이루어져 있고, temporal convolution을 이용해 input(일련의 2D pose)를 변형시킨다.
직렬로 처리해야하는 rnn과 다르게 병렬로 처리 가능하다.
sequence 길이에 상관 없이 input과 output의 사이의 미분경로는 고정된 길이를 가져 RNN에 영향을 줬던 vanishing과 exploding gradients 문제를 완화시켰다.
dilated convolution을 사용하여 long-term dependency와 효율을 유지했다.
dilated convolution 구조는 오디오 생성, semantic segmentation, 번역에서 좋은 성능을 보여줌.

즉, 17개 관절의 (x,y)좌표 243개를 input으로 넣고, skip-connection을 사용한 dilated convolution block들을 통과하여 채널34개의 243개 시퀀스(243,34) --> 채널 1024개의 시퀀스 1개(1,1024) output --> (1,51) 17개 관절(x,y,z)

위의 그림과 같은 Symmetric convolutiong하여 output을 얻는데 realtime으로 실행하기 위해서는 과거의 프레임들만 사용하는 causal convolution 사용.
4. Semi-supervised approach
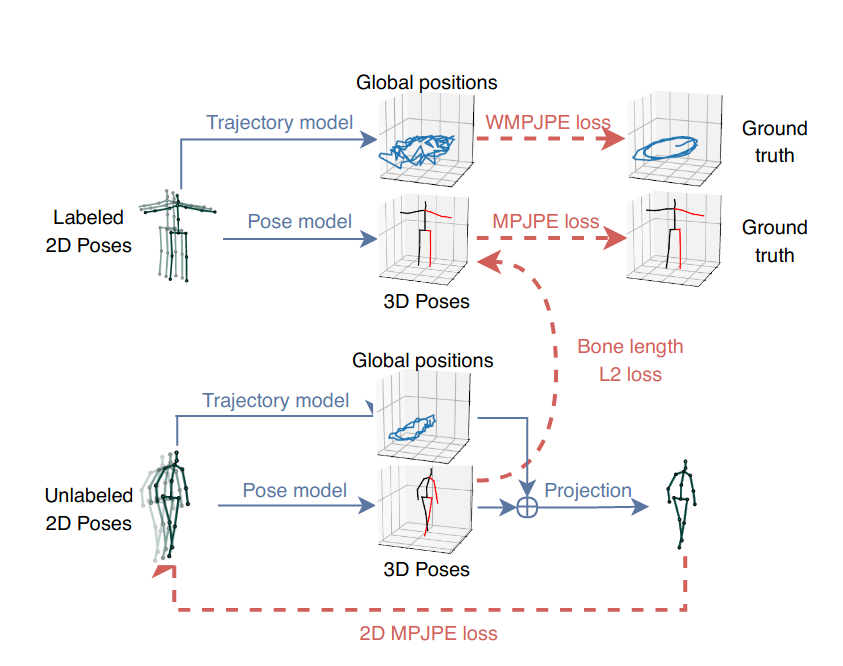
라벨이 붙은 3D ground truth 데이터가 한정적인 상황에서 정확도를 향상시키는 방법으로 semi-supervised 학습 기법을 소개
라벨이 붙지 않은 비디오와 기존 2D keypoint detector를 결합하여 back-projection의 손실값을 얻는 손실함수로 확장했다.
라벨이 붙지 않은 데이터의 오토인코딩 문제를 해결 : 인코더는 3D pose estimation을 하고, 디코더는 3D를 다시 2D로 projection
라벨이 붙은 데이터는 배치의 전반부에 라벨이 붙지 않은 데이터는 배치의 후반부에서 동시에 최적화된다.
라벨이 붙지 않은 데이터는 오토인코더(2D->3D->2D) loss로 사용됨
Trajectory model
투시 투영을 사용하기 위해서 스크린에서의 2D Pose는 trajectory(root joint의 global position)와 3D pose(전체 joint의 root joint 상대 position)에 의존한다.
global position이 없으면 subject는 항상 스크린의 중앙에 정해진 스케일로 투영되므로 3D trajectory도 regress함.
그리고 카메라 공간에서 글로벌 궤적을 회귀하는 두번째 네트워크를 최적화 하고 이는 2D로 투영되기 전에 pose와 합쳐진다.
두 네트워크는 구조적으로 같지만 다중작업 방식으로 학습시 서로 부정적인 영향을 미쳐 가중치를 공유하지 않는다.
피사체가 카메라에서 멀어지면 정확한 궤적을 회귀하기가 어려워지므로 궤적에 대해 WMPJPE(a weighted mean per-joint position error) 손실함수를 최적화 한다.
Bone length
입력을 복사하는 대신 그럴듯한 3차원 자세의 예측을 고려하기 위해 레이블이 없는 배치에 존재하는 subject의 평균 뼈 길이를 레이블이 붙어있는 배치에 존재하는 대상체에 대략적으로 일치시키는 소프트 제약 조건을 추가하는 것이 효과적임을 발견하였다.
