Neural Networks
뉴럴 네트워크는 수학적이고 비선형 연산이 반복적으로 일어나는 어떤 함수를 근사하는 것이다.
Linear Neural Networks
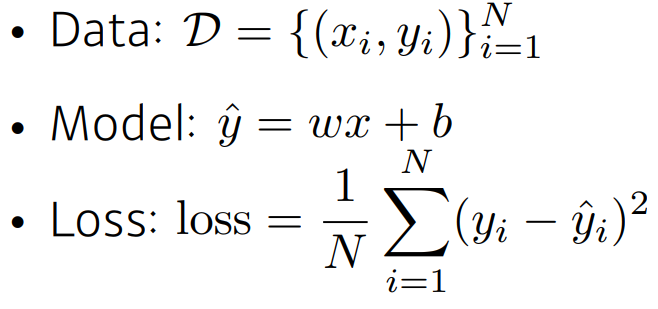
최적화 변수에 대해서 미분값을 구한다.
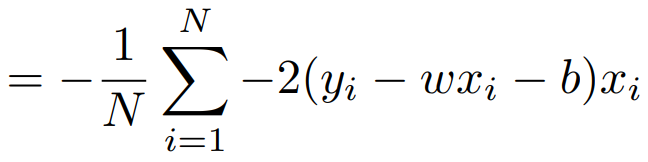
그리고 최적화 변수를 반복적으로 갱신한다.
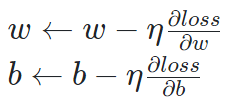
Beyond Linear Neural Networks
위의 선형모델에서 층을 하나 더 쌓으면 다음과 같은 구조가 된다.
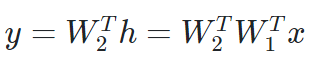
만약 여기서 비선형방식으로 추가를 하면 다음과 같은 식이 된다.
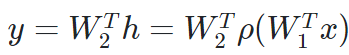
여기서 ρ는 Nonlinear transform이다. 사용되는 활성화 함수로는 ReLU, Sigmoid, tanh 가 있다.
Multi-Layer Perceptron
출력을 다시 입력으로 넣어 layer를 쌓은 모델을 말한다.
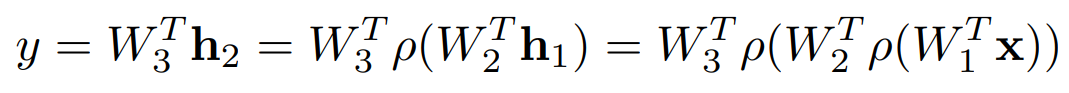
이에 대한 손실 함수는 다음과 같이 3가지 경우로 정의해볼 수 있다.
Regression Task : MSE
Classification Task : CE
Probabilistic Task : MLE
이것을 코드로 구현하면 다음과같이 구현할 수 있다.
class MultiLayerPerceptronClass(nn.Module):
"""
Multilayer Perceptron (MLP) Class
"""
def __init__(self,name='mlp',xdim=784,hdim=256,ydim=10):
super(MultiLayerPerceptronClass,self).__init__()
self.name = name
self.xdim = xdim # 입력
self.hdim = hdim # 은닉
self.ydim = ydim # 출력
self.lin_1 = nn.Linear(
self.xdim, self.hdim # 입력 -> 은닉 층으로
)
self.lin_2 = nn.Linear(
self.hdim,self.ydim # 은닉 -> 출력 층으로
)
self.init_param() # initialize parameters
def init_param(self):
nn.init.kaiming_normal_(self.lin_1.weight)
nn.init.zeros_(self.lin_1.bias)
nn.init.kaiming_normal_(self.lin_2.weight)
nn.init.zeros_(self.lin_2.bias)
def forward(self,x):
net = x # input을 네트워크에 넣는다.
net = self.lin_1(net) # 첫 번째 linear 통과
net = F.relu(net) # ReLU 활성화 함수 통과
net = self.lin_2(net) # 두 번째 linear 통과
return net # 출력
M = MultiLayerPerceptronClass(name='mlp',xdim=784,hdim=256,ydim=10).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(M.parameters(),lr=1e-3) # M에 있는 parameters를 optimize 한다.
print ("Done.")