Data
Dataset
시각화를 진행하기 위해서는 Data가 필요하다. 시각화를 진행할 데이터는 데이터 셋의 관점으로 global 개별 데이터의 관점으로 local로 구분할 수 있다. 데이터의 종류는 크게 다음과 같이 나눌 수 있다.
1.수치형
연속형 : 길이, 무게, 온도
이산형 : 주사위 눈금, 사람 수
- 범주형
명목형 : 혈액형, 종교
순서형 : 학년, 벌점, 등급
정형 데이터
테이블 형태로 제공되며 일반적으로 csv,tsv 파일이다. 가로가 1개의 item을 세로가 feature를 나타낸다.
시계열 데이터
시간 흐름에 따른 데이터이다. 기온, 주가 등 정형데이터와 음성, 비디오 같은 비정형데이터가 존재한다.
시간의 흐름에 따른 추세, 계절성, 주기성 등을 살펴본다.
지리/지도 데이터
거리, 경로, 분포 등 다양하게 사용
관계 데이터
객체는 Node로, 관계는 Link로 나타내고 크기, 색, 수 등으로 객체과 관계의 가중치를 표현한다.
계층적 데이터
관계 중에서도 포함관계가 분명한 데이터를 의미하고 Tree, Treemap, Sunburst등이 있다.
Matplotlib
Python에서 사용할 수 있는 시각화 라이브러리로 다양한 라이브러리와 호환성이 좋고 다양한 시각화 방법론을 제공한다.
기본 Plot
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot()matplotlib에서 시각화는 Figure라는 큰 틀에 Ax라는 서브플롯을 추가하는 방식이다. figsize를 통해 크기 조절이 가능하다. 서브플롯을 늘리고 싶다면 다음과 같이 위치조정을 통해 가능하다.
fig = plt.figure()
ax = fig.add_subplot(131)
ax = fig.add_subplot(132)
ax = fig.add_subplot(1,3,3) # 같은 방식이지만 가독성을 위해 그래프를 표현하고 싶으면 다음과 같이 코드를 작성하면 된다.
fig = plt.figure()
x1 = [1,2,3]
plt.plot(x1, color = 'r',label='red') # 선 그래프로 그림, 색: 빨간색, 범례를 표시하기 위해 label을 red로 선언
plt.legend() # 범례표현
ax.set_title('test_graph') # 차트의 이름 정의
ax.annotate(text='red graph',xy=(1,2)) # 원하는 위치에 text 추가하는 기능
plt.show()위 코드를 실행시킨 화면은 다음과 같다.
Bar Plot
직사각형 막대를 사용하여 데이터 값을 표현하는 그래프
범주에 따른 수치 값을 비교하기에 적합한 방법이다.
방향에 따라 수직이면 .bar()로 x축에 범주 y축에 값을 표기한다. 데이터 비교를 위해서 bottom 파라미터를 사용한다.
수평이면 .barh()로 y축에 범주, x축에 값을 표기한다. 데이터 비교를 위해 left 파라미터를 사용한다.
반드시 x축의 시작은 0이어야 한다.
정확한 정보의 전달을 위해 값순으로 정렬하는 sort.values()와 알파벳 순으로 정렬하는 sort.index()를 사용한다.
fig = plt.figure()
x = list(['C','Java','Python','JavaScript'])
y = np.array([1,2,3,4])
plt.bar(x, y, # 세로 bar type
width=0.7, # 그래프 너비
edgecolor='black', # 테두리
linewidth=2, # 선 두께
color='red') # 그래프 색
# plt.barh(x,y) # 가로 bar type
plt.show()위 코드를 실행시켜 얻은 그래프 모양은 다음과 같다.
다양한 Bar Plot을 위한 실습
데이터셋 준비를 위해 StudentsPerformance.csv에서 데이터를 가져온다.
student = pd.read_csv('./StudentsPerformance.csv')
student.info() # data의 null 값 유무와 dtype을 확인할 수 있다.
# 수치와 범주를 data representation을 mapping하는 것이라 중요하다.그래프를 그리기 위해 그룹에 따른 정보를 시각화하는 작업이 필요하다.
group = student.groupby('gender')['math score'].value_counts()
# 성별에 따른 수학점수를 group화 이를 바탕으로 그래프로 나타내면 다음과 같다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
axes[0].bar(group['male'].index, group['male'], color='royalblue') # 남자의 수학점수는 파란색으로
axes[1].bar(group['female'].index, group['female'], color='tomato') # 여자의 수학점수는 빨간색으로이를 실행시킨 결과는 다음과 같다.
Stacked Bar Plot
bottom 파라미터를 사용하여 아래 공간을 비워두어 두 개의 그래프를 합친 형태로 만들 수 있다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
group_cnt = student['race/ethnicity'].value_counts().sort_index()
axes[1].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], bottom=group['male'], color='tomato')실행 결과는 다음과 같다.
Line Plot
Line Plot은 연속적으로 변화하는 값을 순서대로 점으로 나타내고, 이를 선으로 연결한다. 특히 시간/순서에 대한 변화에 적합하여 추세를 살피기 위해 사용하므로 시계열 분석에 특화되어 있다.
선으로 나타내기 때문에 각 선들을 구별해주는 요소를 알아둬야 한다.
1. 색상(Color)
2. 마커(marker, markersize)
3. 선의 종류(linestyle, linewidth)
기본적인 line plot을 그리는 코드는 다음과 같다.
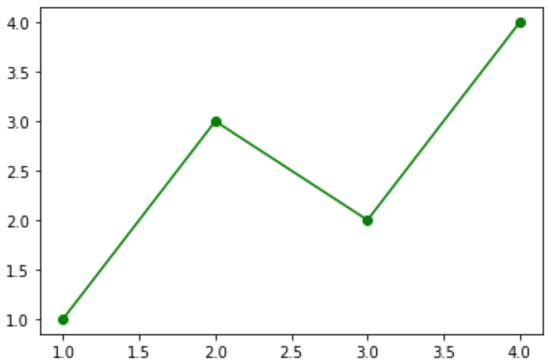
fig = plt.figure()
x = [1,2,3,4]
y = [1,3,2,4]
plt.plot(x,y,
color='green', # 색
marker='o', # 마커 형태
linestyle='solid') # 라인 형태
plt.show() 이 코드를 실행시켜 얻은 그래프의 형태는 다음과 같다.
보간
데이터에 error나 noise가 있는 경우에 데이터의 추세 파악에 약간의 어려움이 있기 때문에 이를 해결하고자 사용한다.
make_interp_spline(x, y) Scatter Plot
점을 사용하여 두 feature간의 관계를 알기 위해 사용한다. 색, 모양, 크기 등을 이용하여 다양하게 표현할 수 있다.
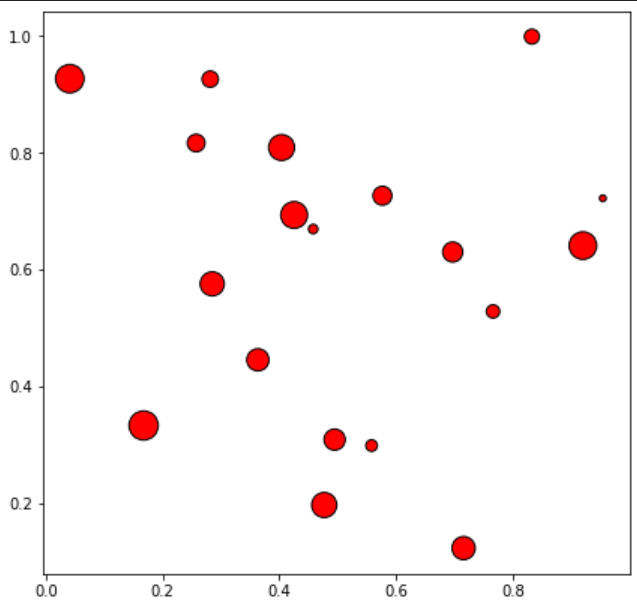
fig = plt.figure(figsize=(7, 7)) # 전체적인 틀
ax = fig.add_subplot(111, aspect=1) # aspect는 subplot의 가로축과 세로축의 scale을 맞춰준다.
np.random.seed(970725)
x = np.random.rand(20)
y = np.random.rand(20)
ax.scatter(x, y,
c='red', # 그래프 색상
marker='o', # 그래프 모양
linewidth=1, # 너비
edgecolor='black') # 테두리 색
ax.set_xlim(0, 1.05)
ax.set_ylim(0, 1.05)
plt.show()위 코드를 통해 얻은 scatter plot의 형태는 다음과 같다.
Text
시각화자료만으로는 충분한 설명이 어렵기 때문에 그것을 보완하는 용도로 사용한다. Text의 종류는 다음과 같다.
Title : 가장 큰 주제
Label : 축에 해당하는 데이터 정보
Tick Label : 축에 눈금을 사용
Legend : 범례
Annotation : 다양한 설명 정보(화살표)
Title
set_title은 그래프의 제목을 정할 수 있는 함수이다.
ax.set_title('Ax Title') # 그래프 제목 설정
ax.set_xlabel('X Label') # X축의 이름 설정
ax.set_ylabel('Y Label') # Y축의 이름 설정Legend
범례의 기본적인 사용방법은 다음과 같다.
ax.plot([1, 3, 2], label='legend') # plot의 label을 통해서 범례를 그려주는 것이 일반적
ax.legend(
title='Gender', # 범례의 제목
shadow=True, # 그림자
labelspacing=1.2, # 범례 label들간의 공간
loc='lower right' # 위치 지정
bbox_to_anchor=[1.2, 0.5] # 외부로 빼는 기능
)Text
그래프 안에 설명을 추가하기 위해 작성하는 Text이며 위치조정이 가능하고 폰트, 크기 등의 설정이 가능하다.
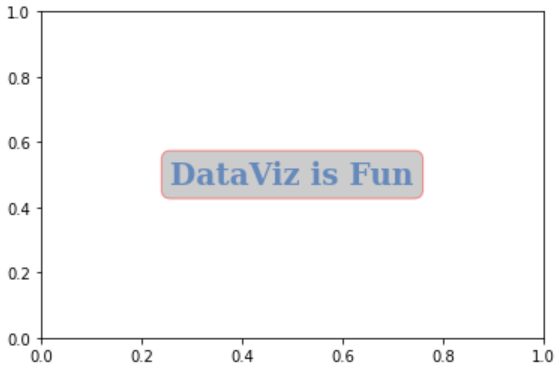
ax.text(x=0.5, y=0.5, s='DataViz is Fun', # x,y 위치
fontsize=20, # 폰트 크기
fontweight = 'bold', # 폰트 굵기
fontfamily = 'serif', # 글꼴
color = '#0047ab', # 글자 색
linespacing = 2, # 간격
backgroundcolor = 'lightgray', # text 배경 색
alpha = 0.5, # 투명도
va = 'center', # 수직정렬(top, bottom, center)
ha = 'center', # 수평정렬(top, bottom, center)
rotation = 'horizontal', # 회전
bbox = dict(boxstyle='round',ec = 'red', facecolor = 'gray', alpha = 0.4) # dict 형태로 전달되어야함.
)위 코드를 통해 얻은 text는 다음과 같다.
Ticks & Text
tick을 없애거나 조정하는 방법이다.
ax.set(frame_on=False) # frame을 안보이게 설정
ax.set_yticks([]) # y축의 정보를 삭제
ax.set_xtickslabels(math_grade.index) # bar 하나당 x축의 범위 설정Color
색은 가장 효과적인 채널을 구분하는 방법이다. 색을 구분짓는 요소는 3가지가 있다.
Hue(색조) : r,g,b에 해당
Saturate(채도) : 선명도
Lightness(광도) : 색상의 밝기
Facet
분할을 의미하며 같은 방법으로 동시에 여러 feature들을 보거나 큰 틀에서 볼 수 없는 부분 집합을 세세하게 보여준다.
Figure는 큰 틀, Ax는 각 plot이 들어가는 공간을 의미한다.
Figure는 큰 틀이기 때문에 언제나 한 개의 값을 갖고 plot은 여러 개일 수 있다.
가장 기본적인 분할 방법은 다음과 같다.
fig, (ax1, ax2) = plt.subplots(1, 2) # 세로로 1 가로로 2 만큼 쪼개는 뜻Squeeze & Flatten
squeeze를 사용하면 항상 2차원으로 배열을 받을 수 있고 가변 크기에 대해 반복문을 사용하기에 유용하다.
fig, axes = plt.subplots(n, m, squeeze=False, figsize=(m*2, n*2))
idx = 0
for i in range(n):
for j in range(m):
axes[i][j].set_title(idx, color = 'white')
axes[i][j].set_xticks([])
axes[i][j].set_yticks([])
idx+=1위의 방법을 사용하면 이중반복문을 통해 작업을 해줘야 하기 때문에 반복문을 하나만 사용하려면 flatten을 이용한다.
fig, axes = plt.subplots(n, m, figsize=(m*2, n*2))
for i, ax in enumerate(axes.flatten()):
ax.set_title(i, color = 'white')
ax.set_xticks([])
ax.set_yticks([])aspect
비율을 의미하며 사용법은 다음과 같다.
fig.add_subplot(122, aspect=0.5) # x축 한칸이 y축 0.5칸add_gridspec
N x M 그리드에서 슬라이싱으로 subplot을 배치할 수 있다. 사용법은 다음과 같다.
fig.add_gridspec(3, 3) # make 3 by 3 grid (row, col)make_axes_locatable
colorbar 구현에 많이 사용되는 방식
ax_divider = make_axes_locatable(ax)
ax = ax_divider.append_axes("right", size="7%", pad="2%") # 쪼개기 colorbar쓸때 유용실행결과는 다음과 같다.
Grid
그리드는 축과 평행선을 사용하여 보조적으로 정보를 제공해준다. 그리드의 형태에는 다음과 같은 형태들이 존재한다.
두 변수의 합 x+y = c
비율 y = cx
두 변수의 곱 xy = c
특정 데이터 중심 (x-x')^2 + (y-y')^2 = c
일반적으로 그리드는 다음과 같이 선언하여 나타낼 수 있다.
ax.grid()Line
직교좌표계에서 평행선을 그리는 것.
axvline()
axhline()
ax.axvline(0, color='red') # 세로축 빨간선
ax.axhline(0, color='green') # 가로축 초록선Span
특정 면적을 표시하는 방법이다.
axvspan()
axhspan()
ax.axvspan(0,0.5, color='red') # y축 0~0.5까지 빨간 면적 표시
ax.axhspan(0,0.5, color='green') # x축 0~0.5까지 초록 면적 표시Spines
대표적으로 다음과 같은 3가지 요소가 있다.
set_visible : 축을 표시하거나 감추거나
set_linewidth : 축의 두께조정
set_position : 축의 위치를 조정
Seaborn
seaborn은 Matplotlib 기반 통계 시각화 라이브러리이다. 쉬운 문법과 깔끔한 디자인이 특징
import seaborn as snsCountplot
sns.countplot(x : 그래프의 방향(세로)
y : 그래프의 방향(가로)
order : 순서 지정
hue : 데이터의 구분 기준을 정해서 색을 통해 구분지음
palette : 색상변경
color : hue로 지정된 그룹을 gradient 색생 전달 가능
hue_order : 색상의 순서를 정할 수 있다.
)Categorical API
사분위수는 데이터를 4등분한 관측값으로 다음과 같이 구분지을 수 있다.
min
25%(lower quartile)
50%(median)
75%(upper quartile)
max
Box Plot
Box Plot을 그리는 방법은 다음과 같다.
sns.boxplot(x='math score', data = student, ax=ax)이를 실행시켜 얻은 결과값은 다음과 같다.
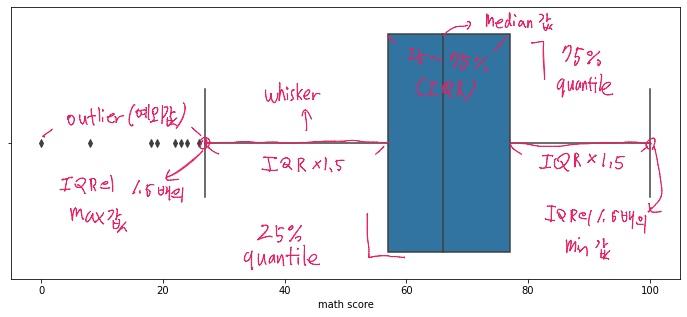
IQR : 25~ 75%
whrisker : 박스 외부의 범위를 나타내는 선
outlier : -IQR1.5와 +IQR1.5를 벗어나는 값
min : -IQR1.5 보다 크거나 같은 값들 중 최소값
max : +IQR1.5 보다 작거나 같은 값들 중 최대값
Violin Plot
Box Plot이 실제 분포를 표현하기에는 어려움이 따르기 때문에 이를 보완하고자 나온 방식. 다음과 같은 코드로 작성하여 나타낼 수 있다.
sns.violinplot(x='math score', data=student, ax=ax)이를 실행시켜 얻은 결과값은 다음과 같다.
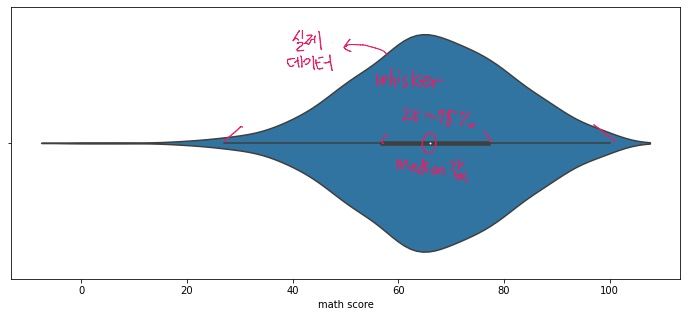
violin plot은 데이터가 연속적이지 않아도 그림과 같이 연속적으로 표현하고 데이터의 범위가 없는 데이터까지 표시하기때문에 오해가 생긴다. 이를 줄이기 위해 다음과 같은 파라미터들을 사용한다.
bw: 분포를 얼마나 자세히 나타낼지
cut : 끝부분을 얼마나 자를지
inner : 내부를 어떻게 표현할지
이를 활용하여 다시 작성해보면 다음과 같이 작성할 수 있다.
sns.violinplot(x='math score', data=student, ax=ax,
bw=0.1, # 분포 표현을 얼마나 자세히 할 것인지
cut=0, # 끝 부분을 얼마나 자를 지
inner='quartile' # 내부를 어떻게 표현할 지
)추가적으로 scale과 split 파라미터를 활용하여 비교를 할 수 있다.
scale : 각 바이올린의 종류(width : 너비가 같게, count : 실제 데이터의 양에 비례, count : 개수에 비례)
split : 동시 비교(True or False)
Distribution
범주형/연속형을 모두 살펴볼 수 있는 분포시각화
Univariate Distribution
hisplot : 히스토그램
kdeplot : Kernel Density Estimate
ecdfplot : 누적 밀도 함수
rugplot : 선을 사용한 밀도 함수
hisplot의 사용법은 다음과 같다.
sns.histplot(x='math score', data=student, ax=ax,
binwidth=50, # 막대의 너비 조정
bins=100, # 막대의 개수를 조정
element = 'ploy', # step, poly (그래프 모양)
multiple = 'stack' # layer, dodge, stack, fill(N개의 분포를 표현가능하다)
)kdeplot은 연속밀도를 보여주는 함수이다. 사용법은 다음과 같다.
sns.kdeplot(x='math score', data=student, ax=ax
fill = True, # 내부를 채워서 밀도 표현
bw_method = 0.05, # 그래프 형태를 좀 더 자세하게 표현
hue = 'race/ethnicity',
hue_order=sorted(student['race/ethnicity'].unique()))
multiple = 'layer',
cumulative = True, # 0부터 데이터를 쌓아서 표현
complementary=True, # 데이터를 쌓아서 내려오는것
)Joint Plot
sns.jointplot(x='math score', y='reading score',data=student,
hue = 'gender' # hue를 통해 성별같은 column으로 구분이 가능하다.
height=7)2개의 feature를 결합하여 결합확률 분포와 함께 각각의 분포도 볼 수 있다.
Pair Plot
모든 feature에 대한 쌍을 시각화한다.
sns.pairplot(data=iris,
hue='species' # 종에 대해 구분짓는다.
corner = True # Corner를 통해 상삼각행렬의 값을 보이지 않게 할 수 있다. Facet Grid
pairplot과 같이 다중 패널을 사용하는 시각화를 의미한다. 총 4개의 함수가 있다.
catplot : Categorical
displot : Distribution
relplot : Relational
Implot : Regression
FacetGrid는 행과 열의 category를 기반으로 해당 그래프의 개수가 조정된다.
