FCN의 한계점
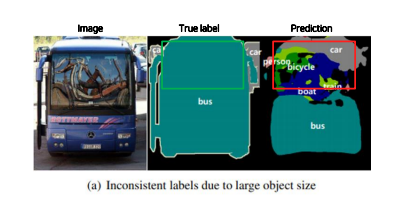
객체의 크기가 작은 경우 예측을 잘 하지 못함.
- 큰 Object의 경우 지역적인 정보만으로 예측한다.
- 같은 Object여도 다르게 labeling이 된다.
- 작은 Object가 무시되는 문제가 있다.

Object의 자세한 부분이 사라진다.

Decoder를 개선한 Models
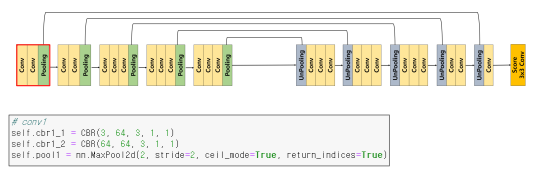
DeconvNet
Architecture
Decoder와 Encoder가 서로 대칭인 형태이다.

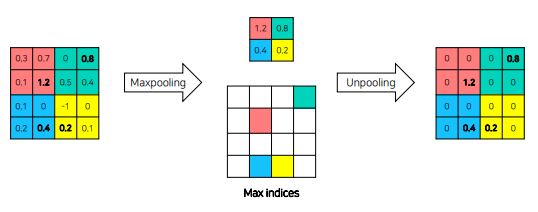
Unpooling vs Deconv
Unpooling은 maxpooling의 핵심이 되는 값의 위치정보를 같이 들고 pooling한다.
Unpooling은 Object의 경계를 복원한다.
Deconv는 안의 내용을 복원한다.
SegNet
1x1 대신 대칭해서 Decoder를 생성했다.
DeconvNet vs SegNet
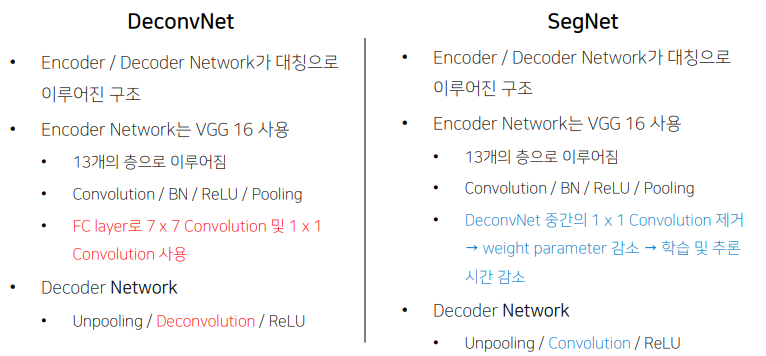
DeconvNet은 성능에 장점이 SegNet은 속도에 장점이 있다.
Skip Connection을 적용한 Models
FC DenseNet
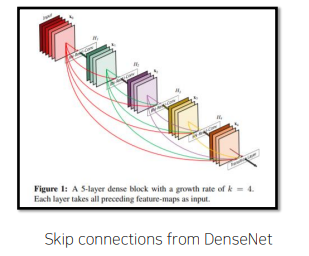
Neural Network에서 이전 Layer의 Output을 일부 Layer를 건너 뛴 후의 layer에게 입력으로 제공한다.
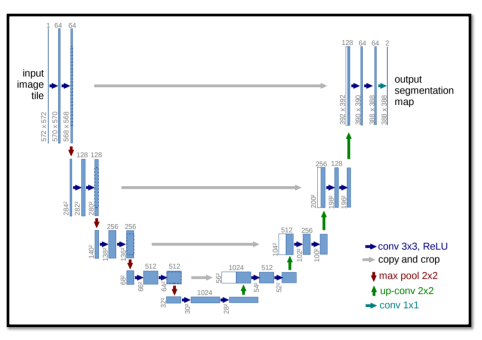
Unet
Receptive Field를 확장시킨 Models
DeepLaB v1
Receptive Field가 객체에 대한 정보를 다 포함하지 못하므로 정확도가 낮다.
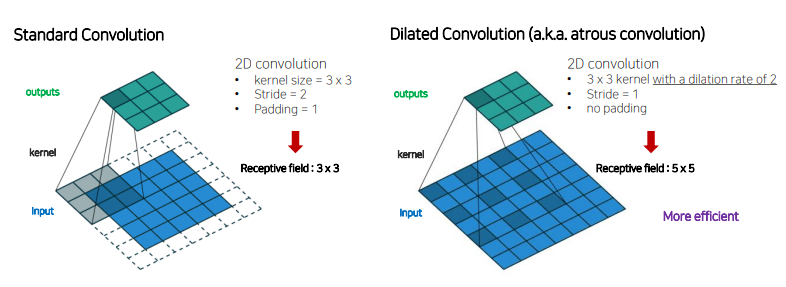
Dilated Convolution
이미지의 크기를 많이 줄이지 않고 파라미터 수는 유지하고 Receptive Field는 넓히는 방법
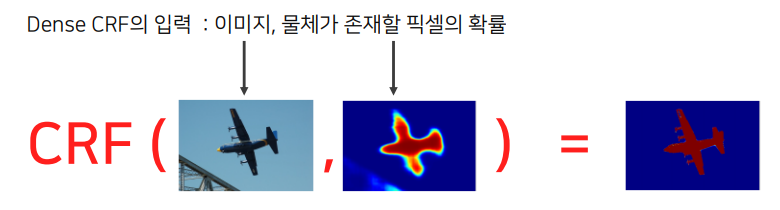
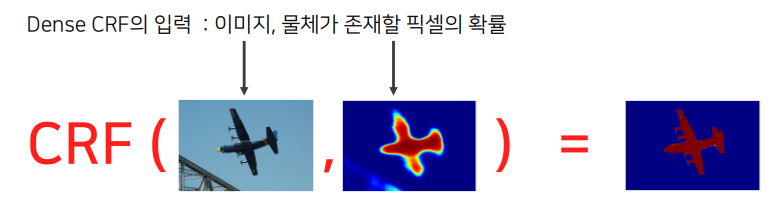
Dense CRF
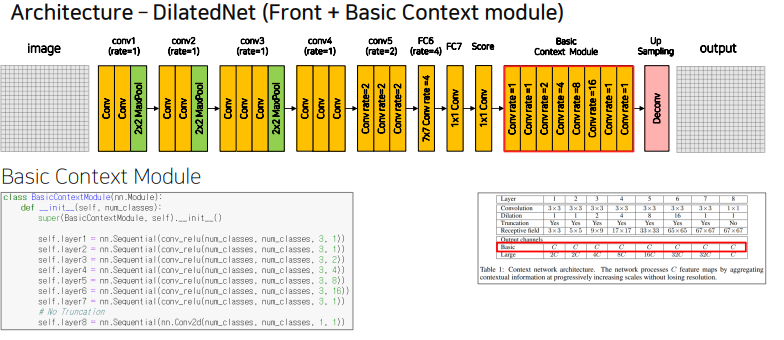
DilatedNet
dialtion과 padding의 크기를 같게하여 Conv layer에서 Resolution의 사이즈를 변하지 않게 조정한다.
basic Context module을 추가하여 크고 작은 사이즈도 잘 검출하게끔 한다.