Conditonal Generative Model

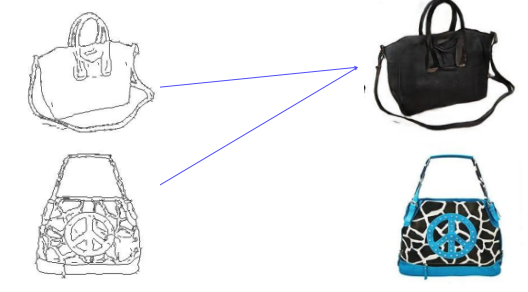
sketch of a bag이 주어졌을 때 X인 이미지가 나올 확률
Generative Model vs Conditional Generative Model
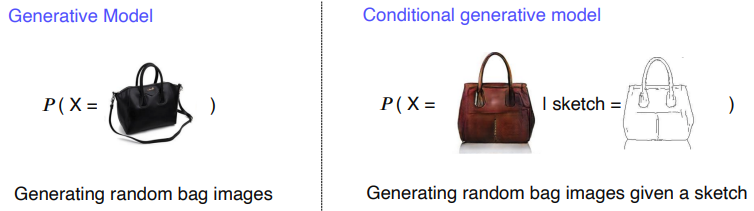
- Generative Model은 Random Sample을 생성하고 Conditional Generative Model은 조건이 주어졌을 때 Random Sample을 생성한다.
GAN
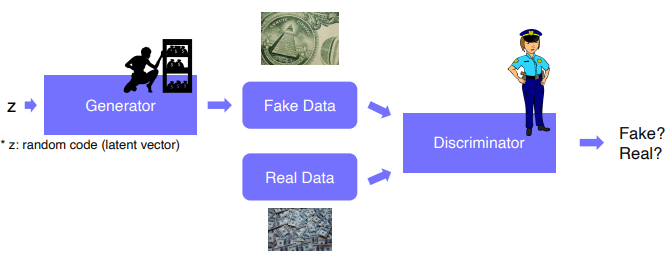
- Adversarial train(적대적 학습법) : Generator는 Fake Data를 더 잘 만들기 위해 학습하고, Discriminator는 Fake Data와 Real Data를 더 잘 구분하기 위해 학습함으로써 둘 다 성능이 올라간다.
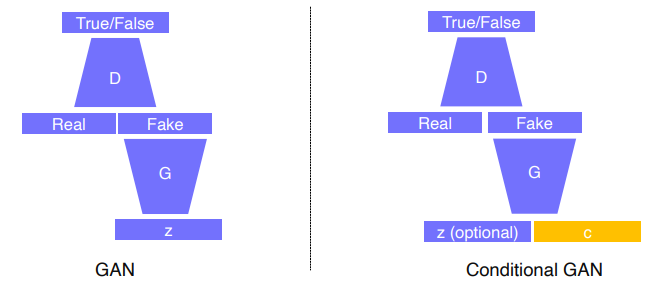
Gan vs cGan
Naive Regression Model
- Comparison of MAE, MSE and GAN losses in an image manifold
- MAE/MSE는 픽셀의 intensity의 차이를 계산하므로 많은 유사한 패치들이 존재한다.
- 안전한 평균 영상이 만들어진다. but, 다소 blurry, 거리가 먼 패치들은 distance가 큼.
- 하지만 GAN loss는 이러한 현상이 발생하지 않는다.
- real data와 비교하여 학습하기 때문에 이미 loss가 낮다.

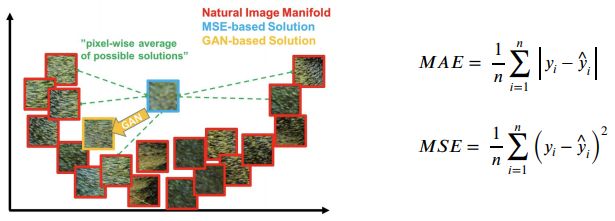
Image Transltation GANs
Pix2Pix

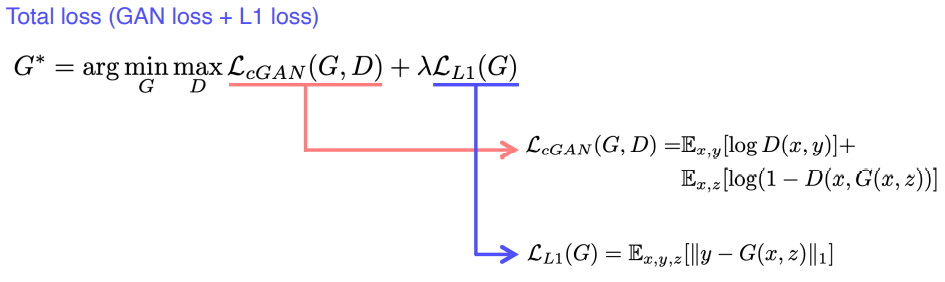
- Loss function of Pix2Pix
- GAN loss는 realistic한 ouput을 낸다
- L1 Loss는 정답 label과 직접 비교를 한다. 하지만 GAN은 입력 영상을 정답 label과 직접 비교하지 않기 때문에 real data와 비슷한 데이터를 만들 수 없다.
CycleGAN
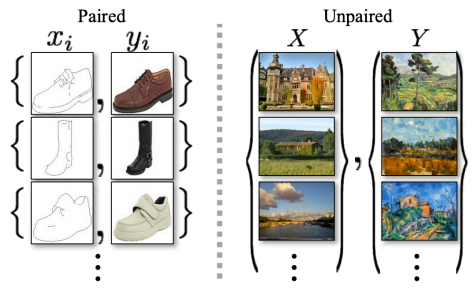
- Pix2Pix에서는 "pairwise data"가 필요했다. 그렇기 때문에 지도 학습이 가능했다.
- pairwise dataset을 얻는 것은 어렵고 불가능할 수도 있기 때문에 이 문제를 해결하고자 CycleGAN이 나왔다.
Loss function of CycleGAN
Cycle-consistency loss는 이미지와 그것을 translation 하고 다시 translation하여 돌아온 이미지가 비슷해야 한다는 것이다.

Gan loss in CycleGAN
- X를 통해 generator G를 생성한 뒤 discriminator y를 통해 y와 비슷한지 판단한다.
- y에서 다른 generator F를 생성한 뒤 discriminator x를 통해 x와 비슷한지 판단한다.
- GAN loss만 사용하게 되면 다음과 같은 문제가 생김(Mode Collapse)
입력에 상관없이 하나의 아웃풋만 계속 출력하는 형태로 학습
어떤 입력이 들어오던지 하나의 realistic한 y만 뽑아내면 discriminator y는 항상 realistic하다고 판단하고 generator G는 더 이상 학습하지 않는다.

Cycle-consistency loss to preserve contents
- style만 보는 것이 아니라 안의 contents도 고려한다.

Perceptual loss
- GAN을 사용하는 이유는 quality 때문이다. 하지만 GAN은 학습하기가 어렵다는 단점이 있다.
- Perceptual loss는 high quality output을 만들기 위해 나온 loss이다.
GAN Loss (Adversarial loss)
- Relatively hard to train and code (Generator & Discriminator adversarially imporve)
- Do not require any pre-trained networks
- Since no pre-trained network is required, can be applied to various applications
- pre-trained 네트워크가 없기 때문에, 다양한 어플리케이션에 제약사항 없이 데이터만 주어지면 활용 가능하다. 물론 그 때문에 데이터 디펜던시가 생기긴 한다.
Perceptual loss
- Simple to train and code (trained only with simple forward & backward computation)
- Requiring a pre-trained network to measure a learned loss
- Pre-trained Image Classification Model의 filter를 살펴보면 사람의 시각과 비슷하다
- 그 네트워크의 초기 layer들은 edge, 방향성, color difference들을 찾는 filter들이 존재함
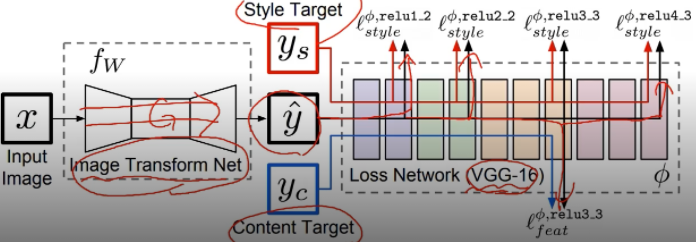
네트워크 학습의 과정
Image Transform Net : Output은 하나로 결정이 된다.
Loss Network : 학습된 loss를 측정하기 위해 Pre-trained VGG 16 모델을 사용했다.
- VGG-16에 생성된 이미지를 넣어서 중간중간 feature를 뽑아준다.
- Pre-trained 되어 있고 training 동안에는 fix 되어서 update되지 않는다.
- Loss를 측정하면서 backpropagation해서 예측값 y를 update할 수록 Image Tranform Net을 학습시켜준다.
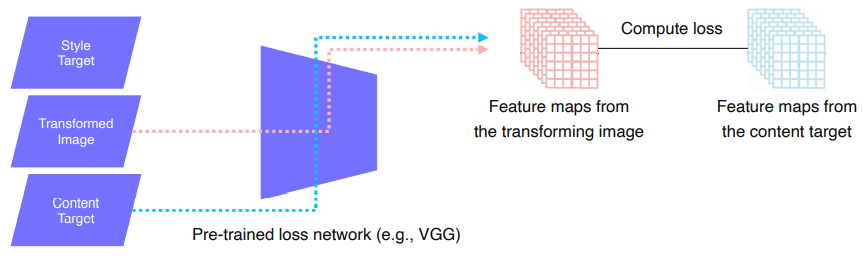
Feature Reconstrucion Loss
- Transform된 Image가 X의 content를 잘 가지고 있는지 확인해주는 Loss -> Input으로 원래 X, 변화하기 전 X를 넣어준다.
- Transform된 이미지에서 온 feature과 content target으로부터 온 feature를 비교하여 L2-Loss를 계산하고 backpropagation을 통해 Y를 update한다.
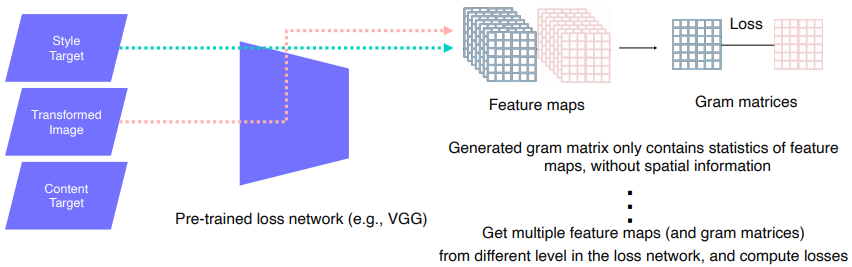
Style Reconstruction Loss
- 변화하고 싶은 style 이미지를 target으로 넣어준다.
- 중간에 Conv layer feature map을 출력하기 때문에 3D Tensor의 형태로 출력된다.
- style을 담기 위해 gram matrices로 작업해준다.
- 각 채널은 각각의 feature에 집중한다.
-> 가로 빗살무늬 feature와 세로 빗살무늬 feature가 많이 관찰되면 데이터는 가로 세로 빗살무늬가 많은 style일 가능성이 높다.