Overview of multi-modal learning
-
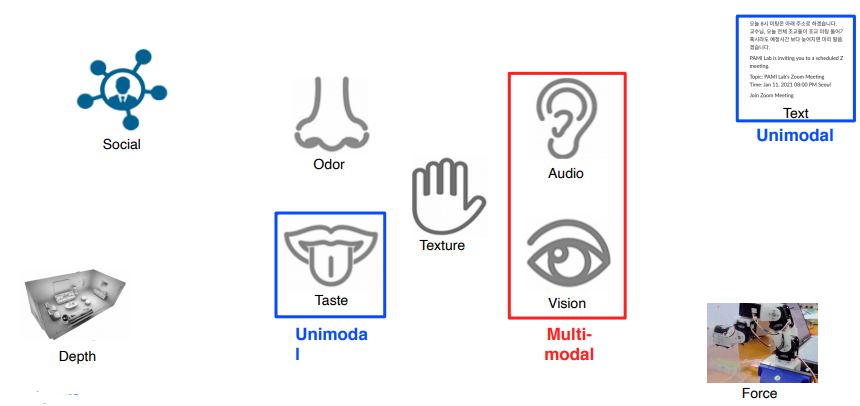
Multi-modal learning : 다른 특성을 갖는 데이터 타입들을 같이 활용하는 학습법
-
Multi Model은 데이터들의 표현 방법이 다 다르기 때문에 어렵다.

-
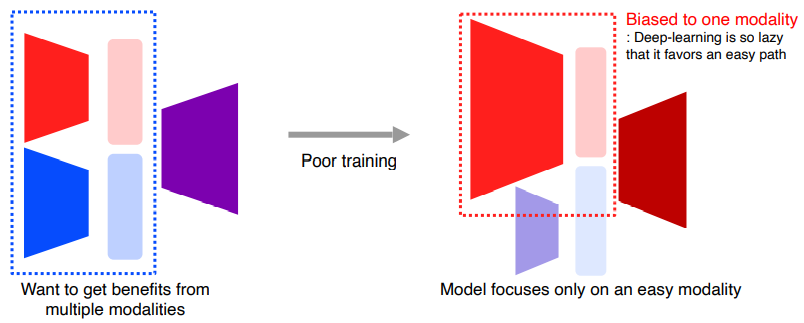
서로 다른 Modality에서 오는 정보의 양이 unbalance 하고 feature space에 대한 정보 또한 unbalance 하다.
. 여러 Modality를 썼을 때 공평하게 정보를 주어도 쉬운 정보와 어려운 정보의 차이가 생긴다.
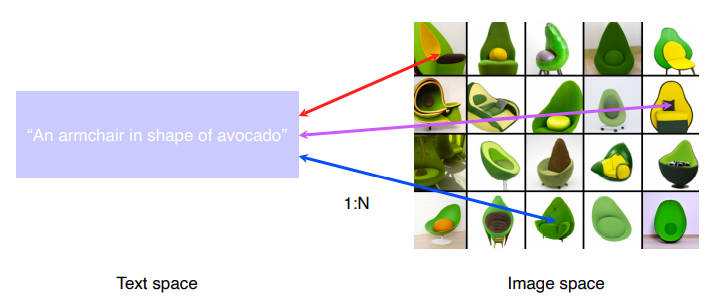
Multi-modal tasks(1) -Visual data & Text
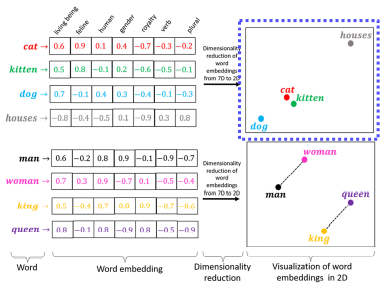
Text embedding
- Character만 사용하는 것은 어렵기 때문에 word level을 주로 사용한다.
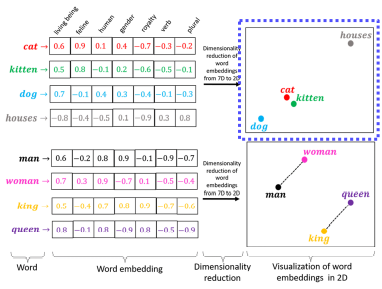
- 학습 방법 - word의 dense한 embedding한 vecotr가 주어진다. -> 일반화하는 능력이 생긴다.
- cat과 kitten이 가깝고 dog과 cat에 비해 cat과 houses의 거리가 먼 것을 확인가능
- man과 woman의 차이를 king을 더해주면 queen이 나오는 연관성 또한 파악 가능
Embedding Skill
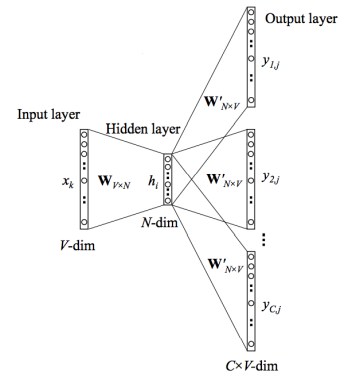
- word2vec라는 모델을 통해 학습한다.
- W와 W'를 학습하기위해 Train 된다.
- Skip-gram model
- Input layer의 Node들이 각각의 word를 의미한다.
- one-hot vector에 W가 곱해지면서 특정 row를 embedding하는 구조이다.
- W'연산 후 output layer에서는 선택된 단어 전후로 어떤 단어가 와야하는지 패턴을 학습한다.
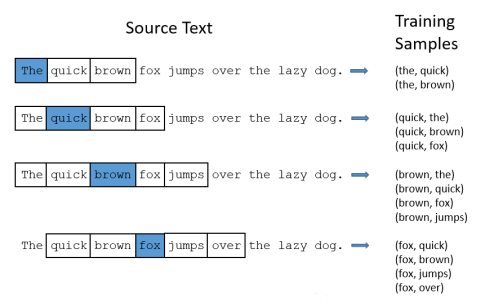
- 주위의 N개의 word를 예측하는 방식으로 학습을 하게 된다. 하나의 word와 그 관계성을 이해하는 방향으로 학습한다.
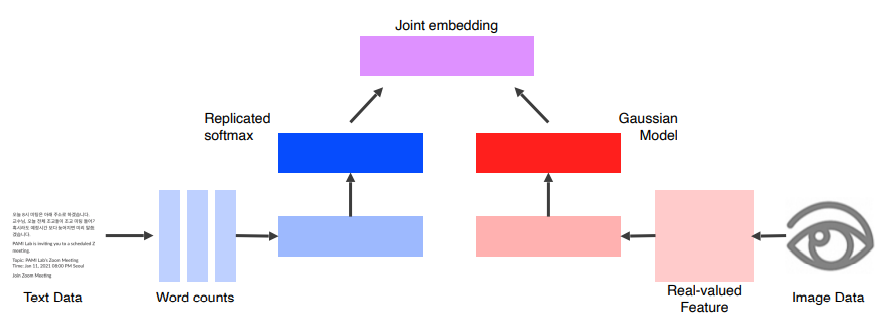
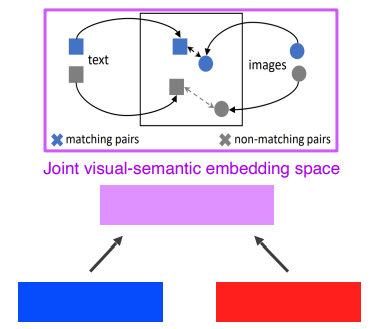
Joint embedding
- matching 하기 위한 공통된 vector들을 학습하는 것이다.
- 주어진 이미지로부터 Tag를 생성할 수 있고, 주어진 Tag 키워드로부터 이미지를 나타낼 수 있다.

- 구현 방법 : Pre-trained 된 unimodal들을 합친다.
- Text Data, Image Data 와 관계없이 feature vector로 표현한다.
- 같은 Dimension으로 같은 space를 공유할 수 있게 하고 joint embedding 한다.
Cross modal translation
Image captioning
- 이미지가 주어지면 이미지를 가장 잘 설명해내는 문구를 생성해주는 연구이다.
- 한 단어를 출력해주면 그것을 다시 input으로 넣는것을 반복한다.
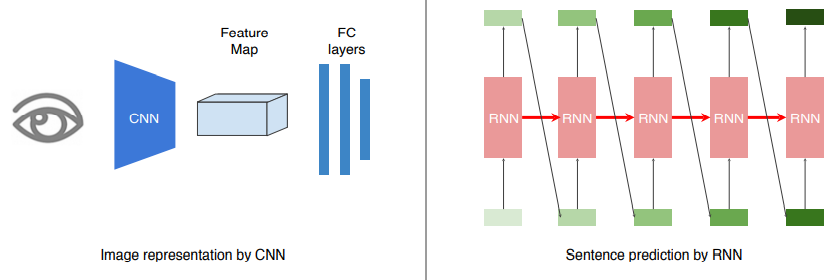
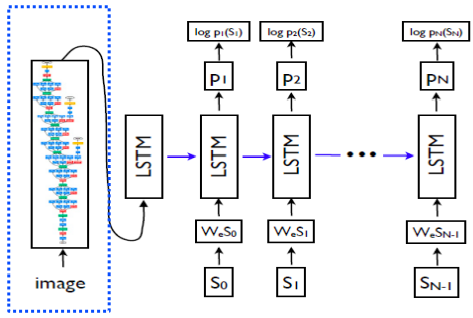
- 위와 같이 CNN + RNN을 Show and tell이라고 한다.
- Image가 Input으로 들어오면 그것을 fix-dimensional vector로 바꿔주기 위해선 Encoder가 필요한데 이 때 ImageNet에서 Pre-trained된 CNN을 사용한다.
- 그것을 Condition으로 제공하고, LSTM에 시작 token으로 넣는다. 이것을 end가 출력될 때까지 반복한다.
Show,attend and tell
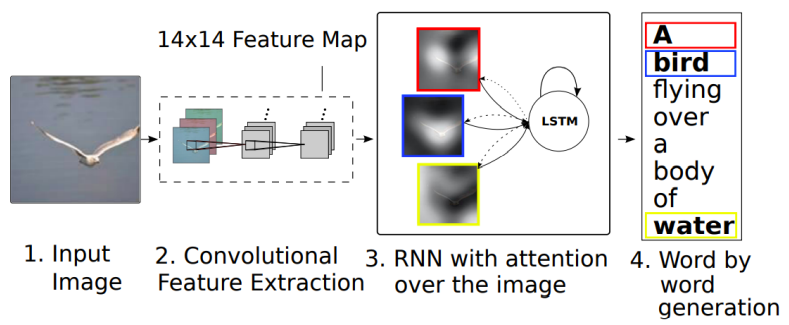
- sentence를 보고 이미지를 출력할 때 그 단어가 가리키는 것을 더 주목한다.
- input 이미지를 넣고 CNN을 통해서 feature map을 뽑아주는데 그냥 fixed 된 dimensional vector 대신 14x14 정보를 담고있는 feature map을 출력한다. 그것을 RNN에 넣어서 하나의 word를 생성할 때마다 14x14를 reference 해서 어떤 단어를 출력해야할 지 예측해 나가면서 단어를 생성한다.
- show, attention and tell -> attention
- Attention 매커니즘은 spatial한 feature가 들어오게 되면 RNN을 넣어서 어디를 보고 있는지 heatmap을 만들어 주고 이것과 feature를 잘 결합해 z(weighted sum)을 만들어준다.

Cross modal reasoning
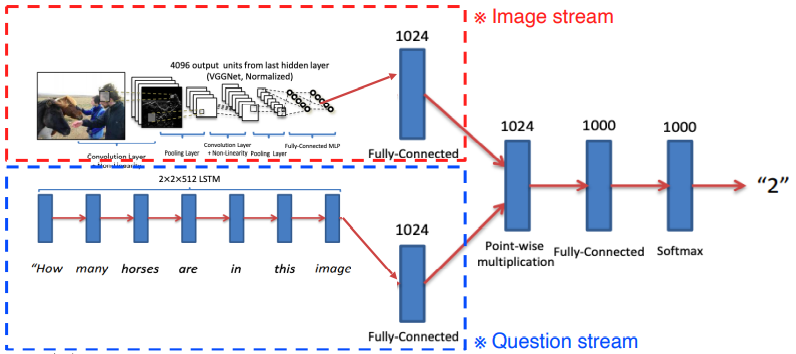
Visual question answering
- 영상이 주어지고 질문이 주어질 때 답을 도출하는 형태의 task이다.
- question stream : text의 sequence로 RNN으로 encoding하여 fixed dimensional vector를 생성한다.
- Image Stream : Pre-trained neural network를 사용하여 fixed dimensional vector를 생성한다.
- 앞선 두 vector를 point-wise multiplication하여 두 개의 embedding vector가 interaction한다.
Multi-modal tasks(2) - Visual data & Audio
Sound representation
- 머신러닝이나 딥러닝에서는 Spectogram으로 변환하여 사용한다.
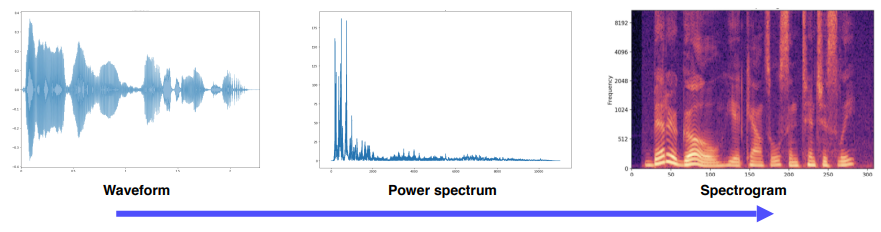
- Fourier transform : 시간축에 대한 표현이 불가능하므로 STFT 활용한다.
- STFT : 전체 구간이 아니라 아주 짧은 구간에 대해서만 Fourier transform을 적용한다.
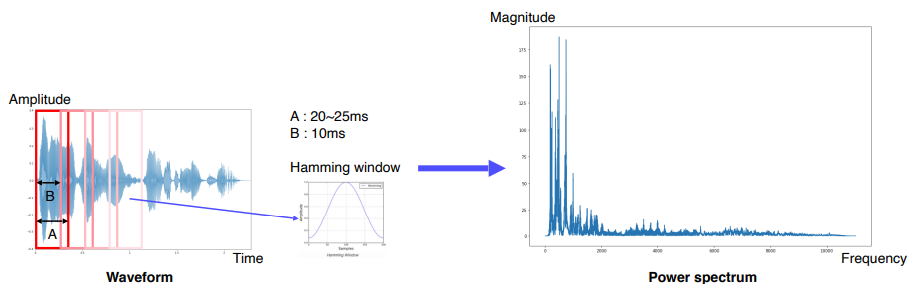
- 주파수 성분을 잘 표현할 수 있도록 변환한다.
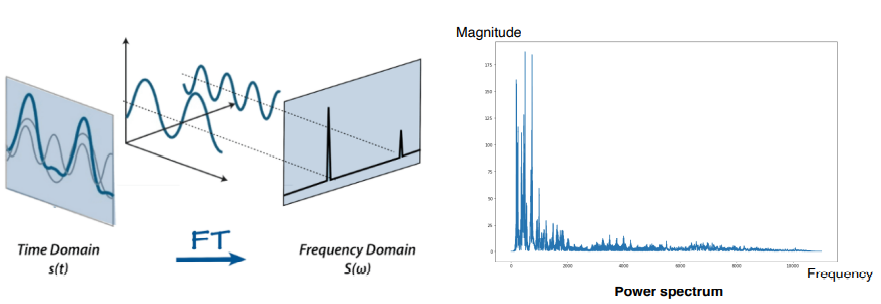
- Spectogram : x(time), y(frequency), 시간에 따른 주파수 변화량을 볼 수 잇음
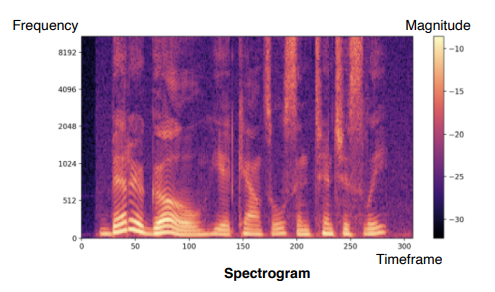
Joint embedding
SoundNet
- 오디오 표현을 어떻게 할 지 방법론을 제시했다.
- pre-trained된 모델을 통해 어떤 object가 덜어있는지에 대한 distribution과 현재 video가 어떤 장면에서 촬영되고 있는지 scene distribution을 출력한다.
- audio는 raw waveform형태로 CNN input에 넣는다.
- two heads로 나눠서 각 distribution과 매칭한다.
- spectrogram 대신 waveform을 활용했다.
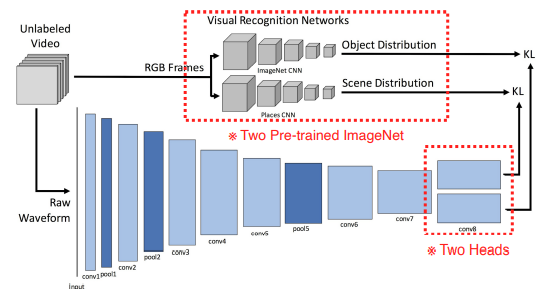
Cross modal translation
Speach2Face : 음성을 듣고 얼굴을 상상하는 모델
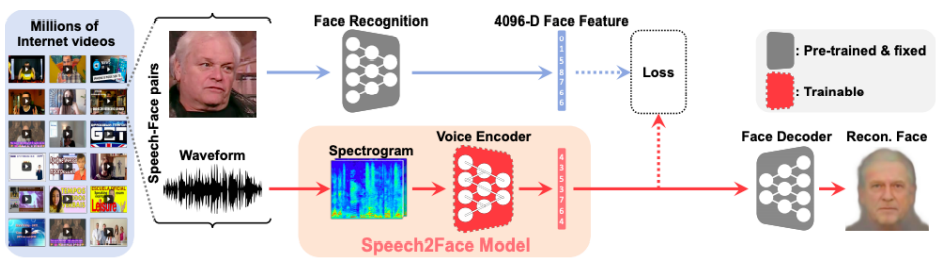
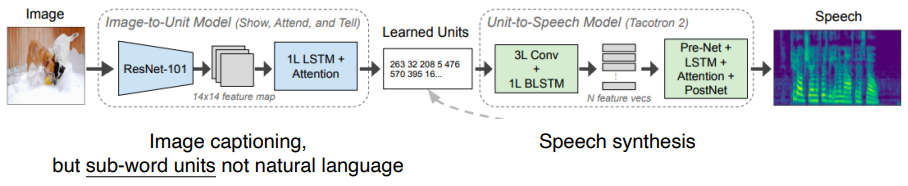
Image-to-speech synthesis
- Module networks
- Image-to-Unit Model
- Unit-to-Speech Model
두 모델의 호환성을 맞춰야 한다.


{kind=link}