-
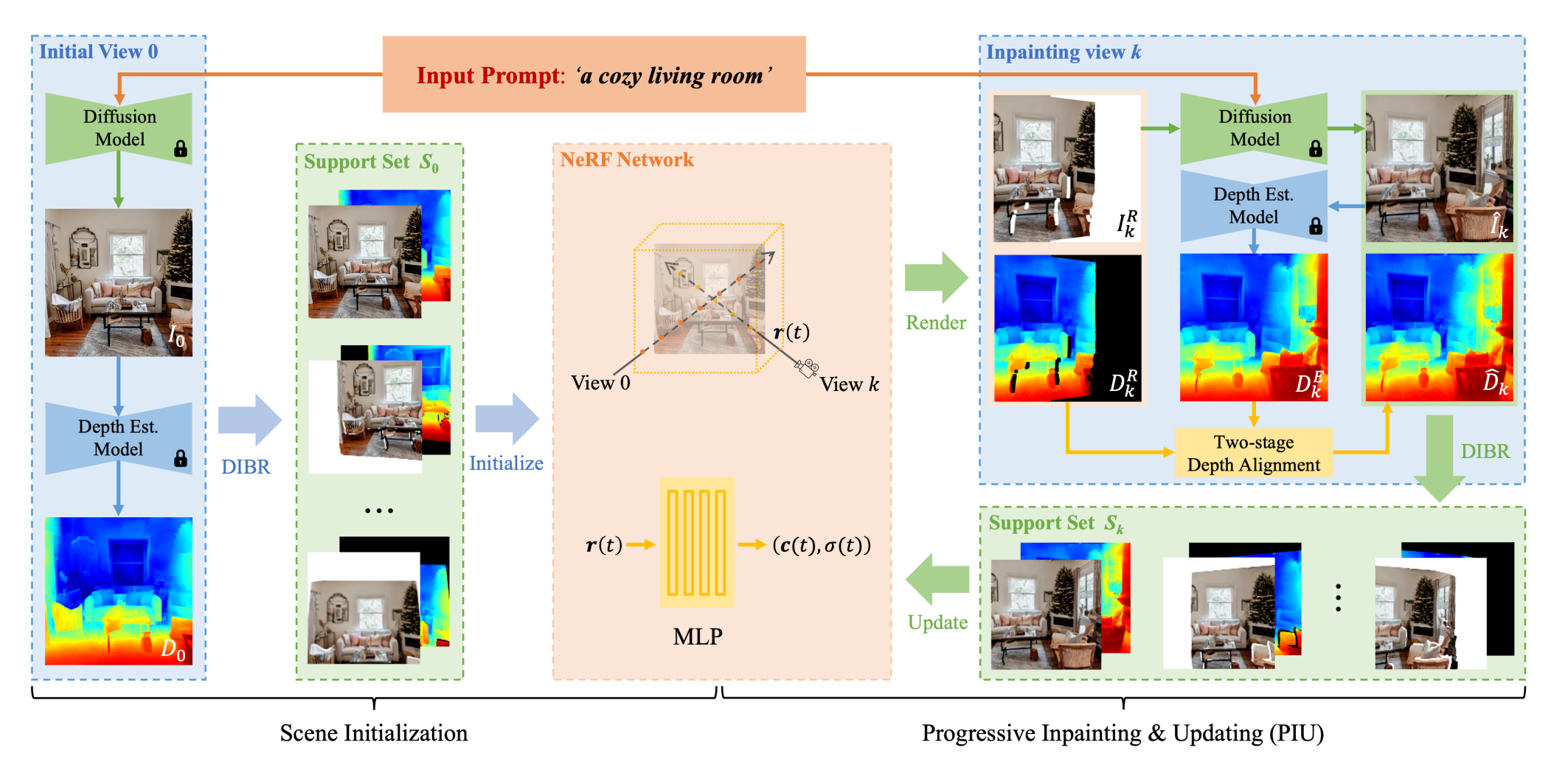
Input prompt 를 condition으로 하는 diffusion model로부터 2D image 생성
-
Initial view를 warping하여 multi-view supervision 생성
-
Warping된 이미지의 빈 영역은 다시 를 condition으로 주는 diffusion model에 태움. 이 때, inpainting의 quality를 보장할 수 없기 때문에 30개의 후보군을 생성한 뒤 CLIP semantic space에 서 initial view와 가장 유사한 것을 선택
-
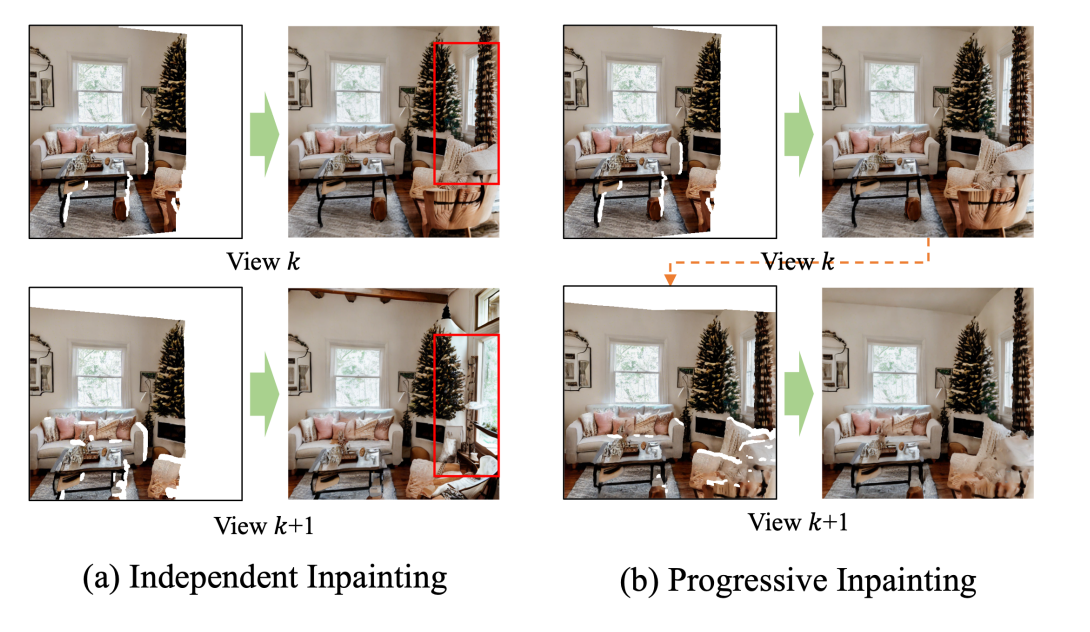
3D constraint가 없어 서로 다른 view에서 inpainting된 overlapping 영역이 inconsistent 할 수 있기 때문에 radiance field를 update 한 후 다음 inpainting을 진행하는 방식을 활용
-
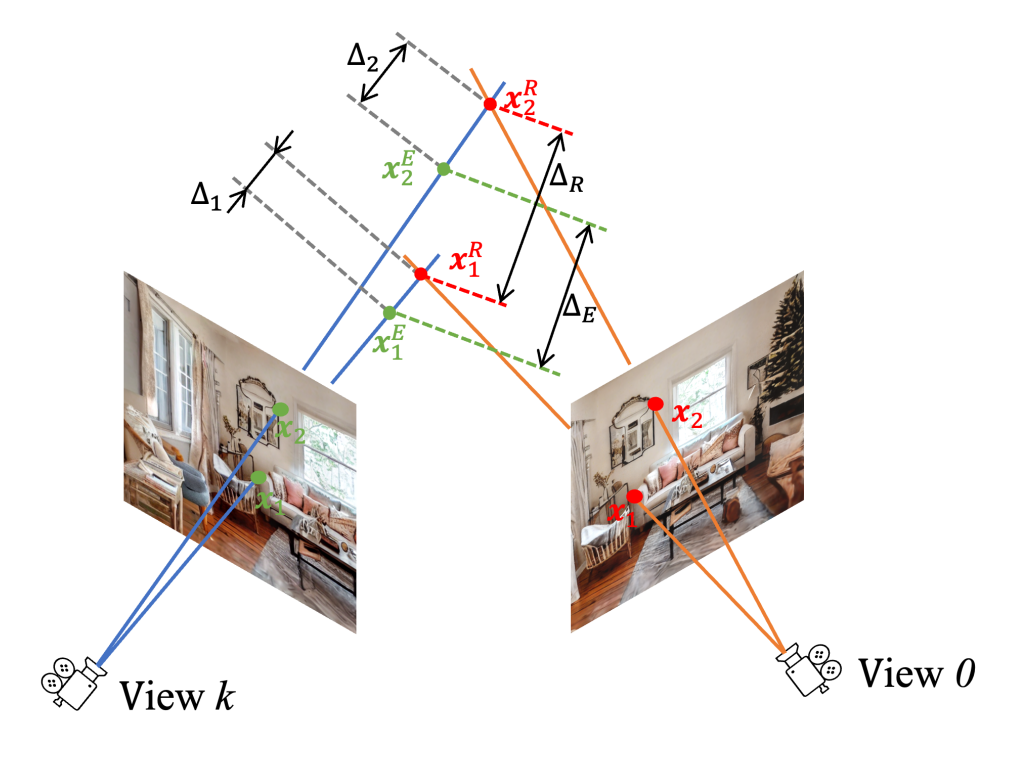
Rendering된 depth와 estimated depth 사이에 scale disparity와 distance disparity가 존재할 수 있기 때문에 이를 align 해주는 과정이 있음
