논문
1.[논문리뷰] YOLO v1(You Only Look Once)
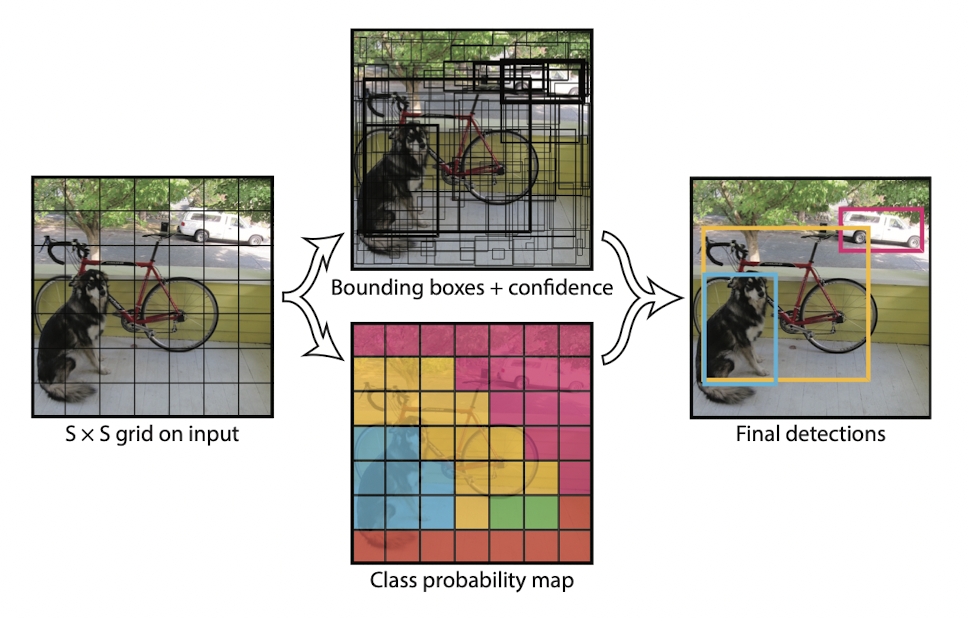
하나의 네트워크로 bounding box 예측과 class 분류를 모두 해결(One-Stage)45FPS로 실시간 detection이 가능(Fast-YOLO에서는 155FPS)localization error가 증가했지만 배경에 대해 false positive가 줄었다
2.[논문 리뷰] Deep SORT(Simple Online and Realtime Tracking with a Deep Association Metric)

SORT에서는 state estimation uncertainty가 낮을 때만 association metric이 정확하여 객체가 계속 스위칭 되는 현상이 있었다. 즉, occlusion에 취약했다.Deep SORT에서는 motion과 appearance를 결합한 me
3.다양한 생성망 모델들(GAN,VAE,DCGAN,LSGAN,CatGAN)
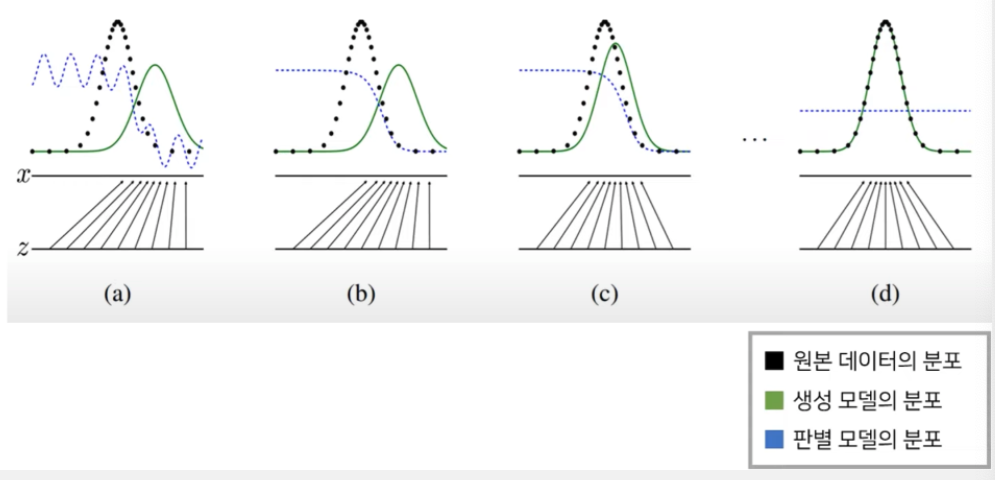
위조 지폐범(Generator)와 경찰(Discriminator)의 대결G는 최대한 진짜 같은 모조품을 만들며, D는 진품과 모조품을 구별한다. 경쟁적 학습을 통해 결국 완전한 모조품을 만드는 것이 목표(위조 지폐범의 승리) GAN은 실존하지는 않지만 있을법한 이미지
4.[논문리뷰] SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks
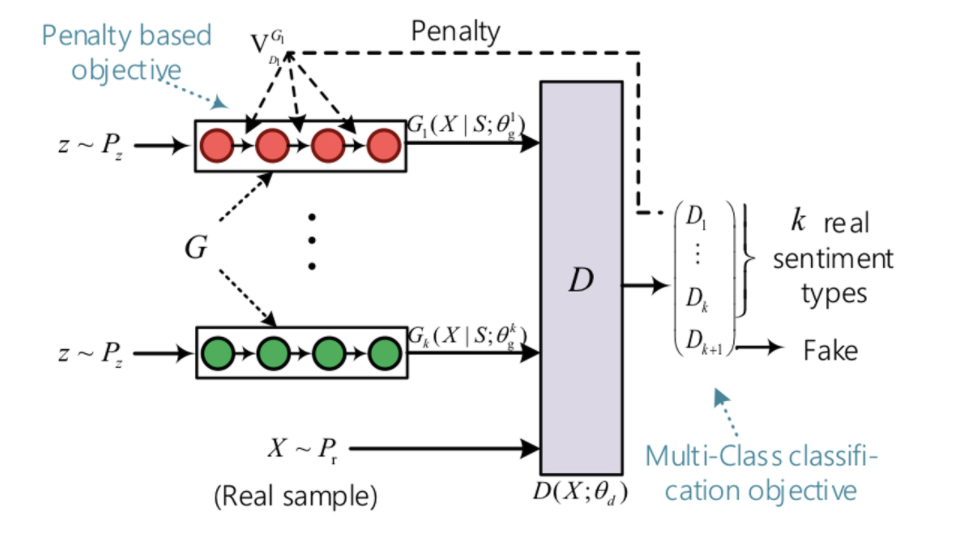
기계가 감정이 담긴 텍스트를 이해하고 생성한다는 것은 지능적이며, 사람들에게는 친화적이다. 하지만 감정 텍스트의 분류에는 큰 발전이 있었음에도 불구하고 생성모델에 대한 시도는 그동안 많이 이루어지지 않았다.저자들은 GAN을 활용한 텍스트 생성을 시도하려 했으나 mode
5.[논문리뷰] R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
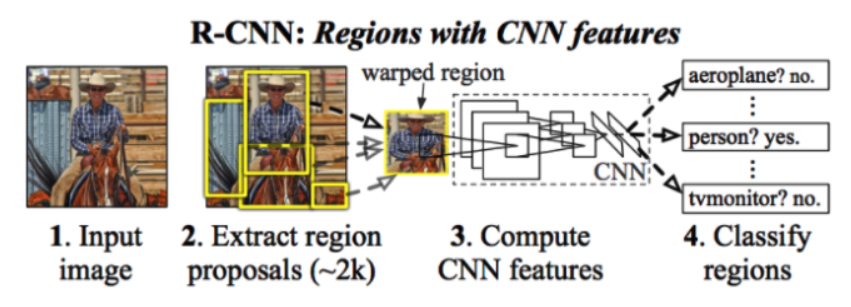
Object Detection이란 물체의 위치 정보를 파악하는 Localization과 어떤 물체인지 분류하는 Classification을 모두 수행하는 알고리즘이다. Object Detection은 크게 1-stage Detector와 2-stage Detecto
6.[논문 리뷰] SaimMask: Fast Online Object Tracking and Segmentation: A Unifying Approach
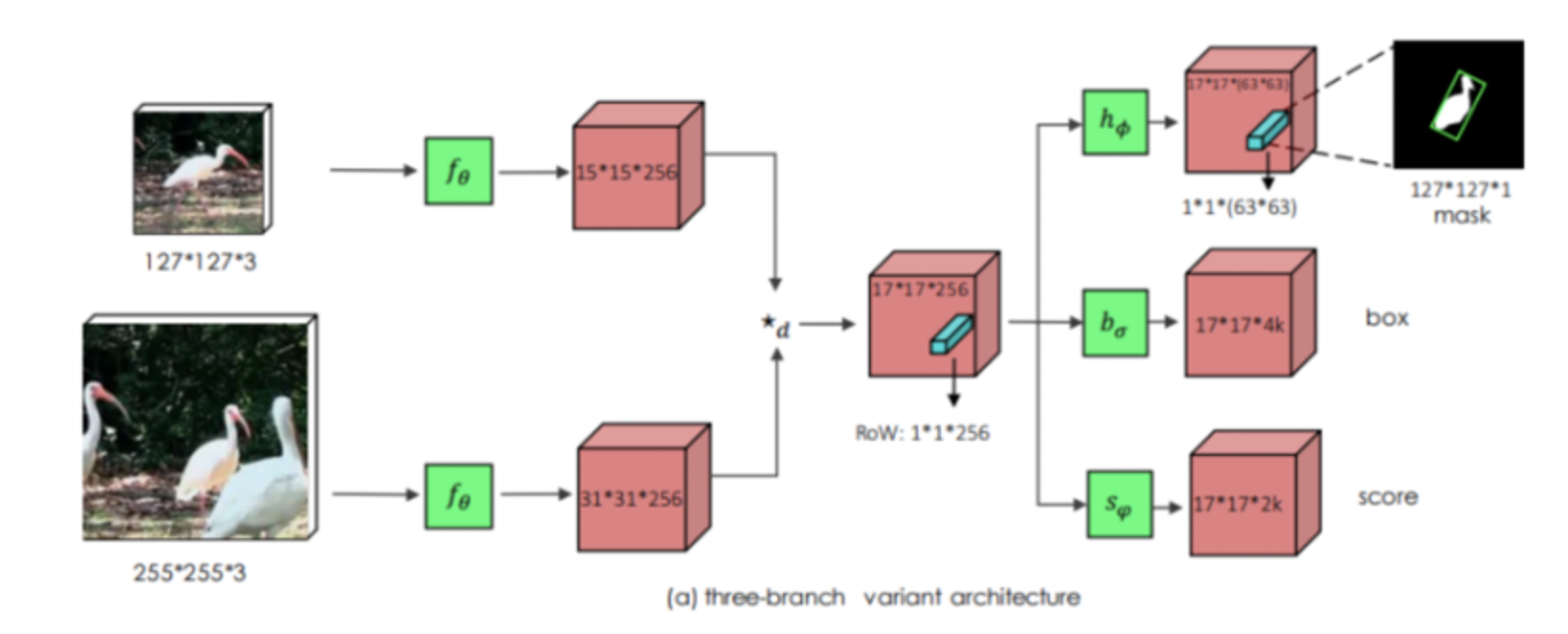
VOS(Visual Object Segmentation)는 픽셀 단위로 객체 포함 여부를 확인하여 속도가 느리므로 실시간 tracking에 적합하지 않다.본 논문에서는 SiamMask를 통해 tracking과 segmentation 두 가지 문제를 동시에 해결한다.이를
7.[논문 리뷰] EfficientDet: Scalable and Efficient Object Detection
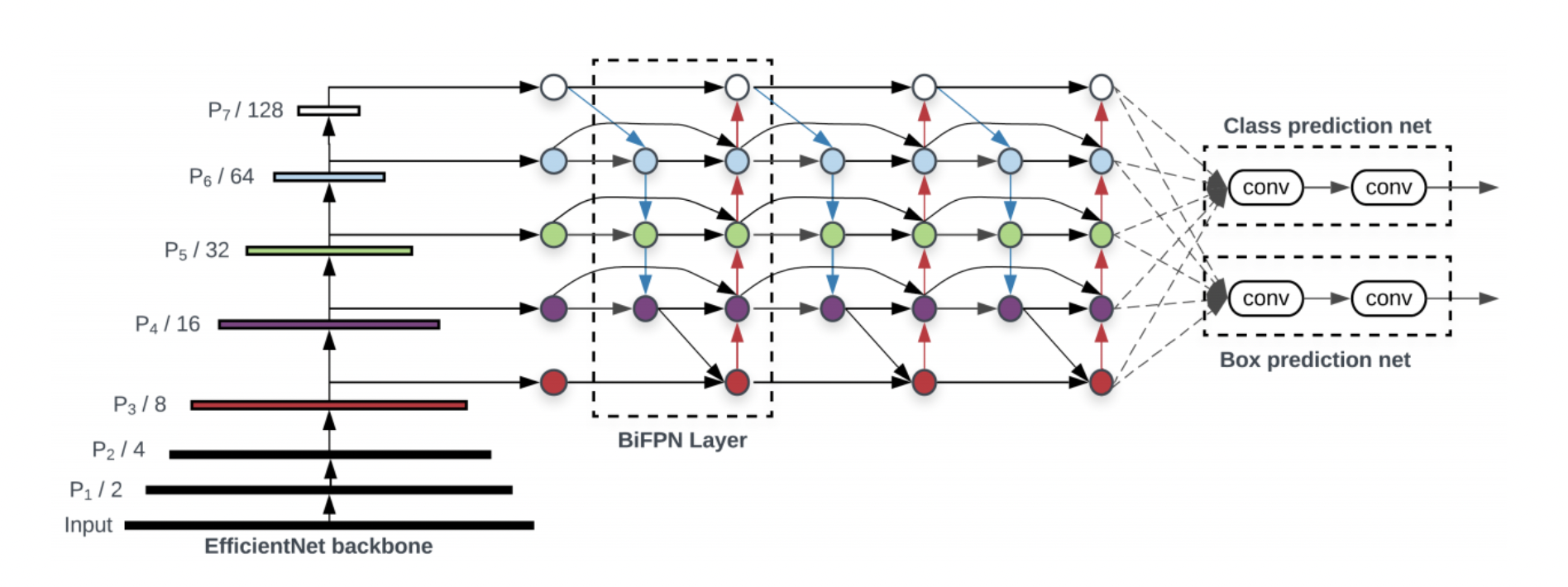
본 연구에서는 크게 두 가지의 관점에서 object detection의 성능을 높이고자 한다.기존의 연구들은 multi-scale feature fusion을 사용할 때 단순하게 합하는 방식을 사용해왔다.하지만 서로 다른 input features는 output fea
8.[논문 리뷰] Transformer: Attention Is All You Need
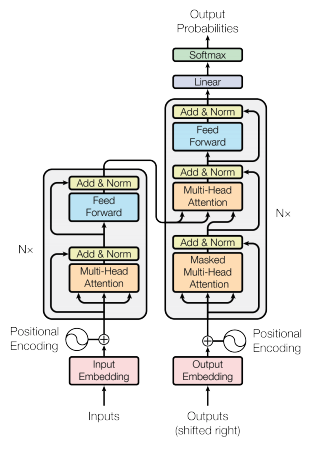
Seq2Seq 모델들은 Encoder의 정보들을 벡터화하여 손실되는 문제가 있어 Decoding 시 개별 토큰과의 관계 파악이 어려움또한, Sequence가 길어지는 경우 Gradient vanishing 문제 발생문제 해결을 위해 Attention value 도입인코
9.[논문 리뷰] NCF: Neural Collaborative Filtering
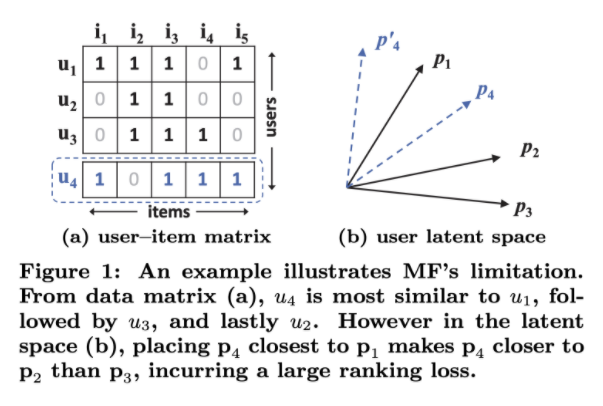
추천시스템에서 Matrix Factorization(MF)는 사용자와 아이템이 공유하는 잠재 벡터를 찾아 효과적으로 연관성을 찾는 모델이다.그동안 MF의 성능을 향상시키기 위한 다양한 연구들이 진행되었지만 내적의 특성상 선형적인 관계를 표현하기에 그친다는 한계가 있었다
10.[논문 리뷰] ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
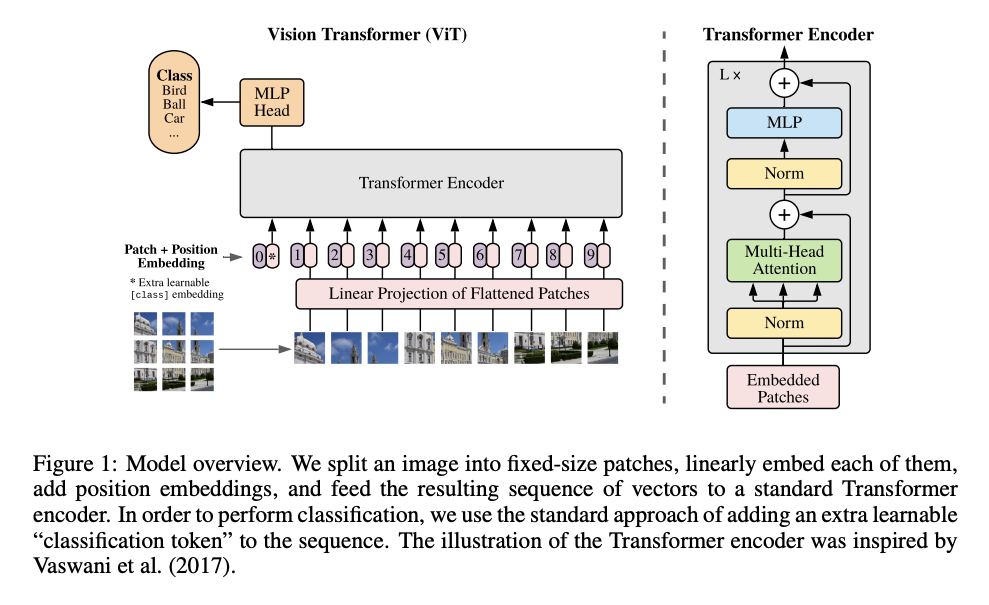
NLP에서 transformer는 큰 성과를 이루며 실질적인 표준이 되었으나, CV에서의 응용은 제한적그동안 vision 분야에서는 attention을 CNN과 혼용하여 사용하거나, CNN의 구조는 유지하되 일부 요소들만 대체하는 방식으로 사용해왔다.본 논문에서는 CN
11.[논문 리뷰] Tracktor: Tracking without bells and whistles
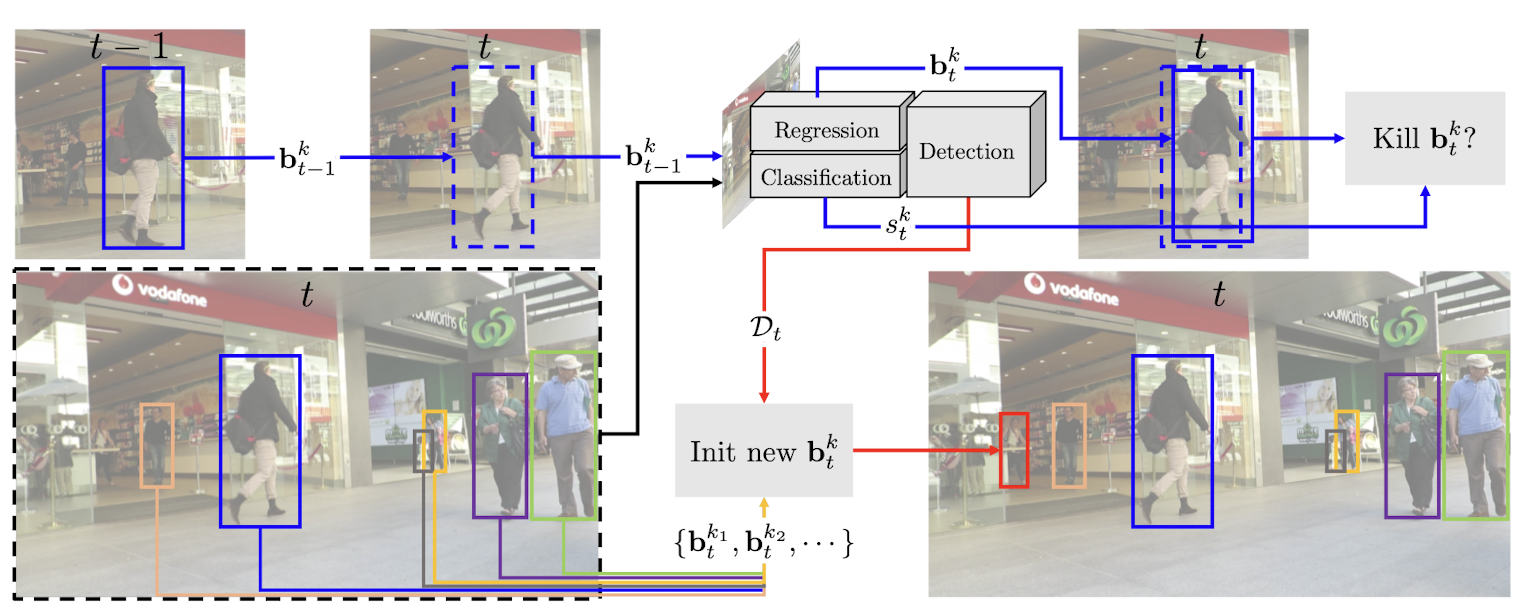
기존의 tracking-by-detection 방식은 re-identification, motion prediction, dealing with occlusion의 task를 포함한다.본 논문에서는 bounding box regression을 활용하여 기존의 불필요한
12.[논문 리뷰] FCN: Fully Convolutional Networks for Semantic Segmentation
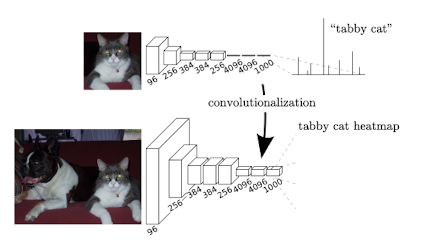
Convolutional Network의 구조를 end-to-end, pixells-to-pixels 방식으로 학습시켜 semantic segmentation 분야에서 SOTA 달성임의의 사이즈의 이미지를 인풋으로 넣었을 때, 동일한 사이즈의 아웃풋이 나오도록 full
13.[논문 리뷰] Mask R-CNN
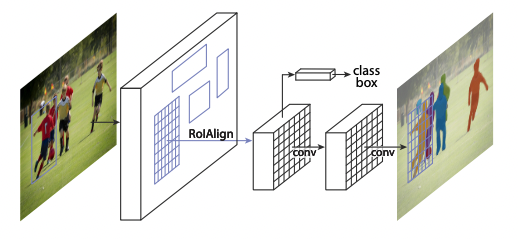
그동안 Object detection, Semantic segmentation에서는 큰 성과가 있었으나 Instance segmentation은 모든 객체들에 대한 정확한 detection과 segmentation이 이루어져야 하기에 어려움이 있었다.따라서 복잡한 과정
14.[ 논문 리뷰 ] U-Net : Convolutional Networks for Biomedical Image Segmentation
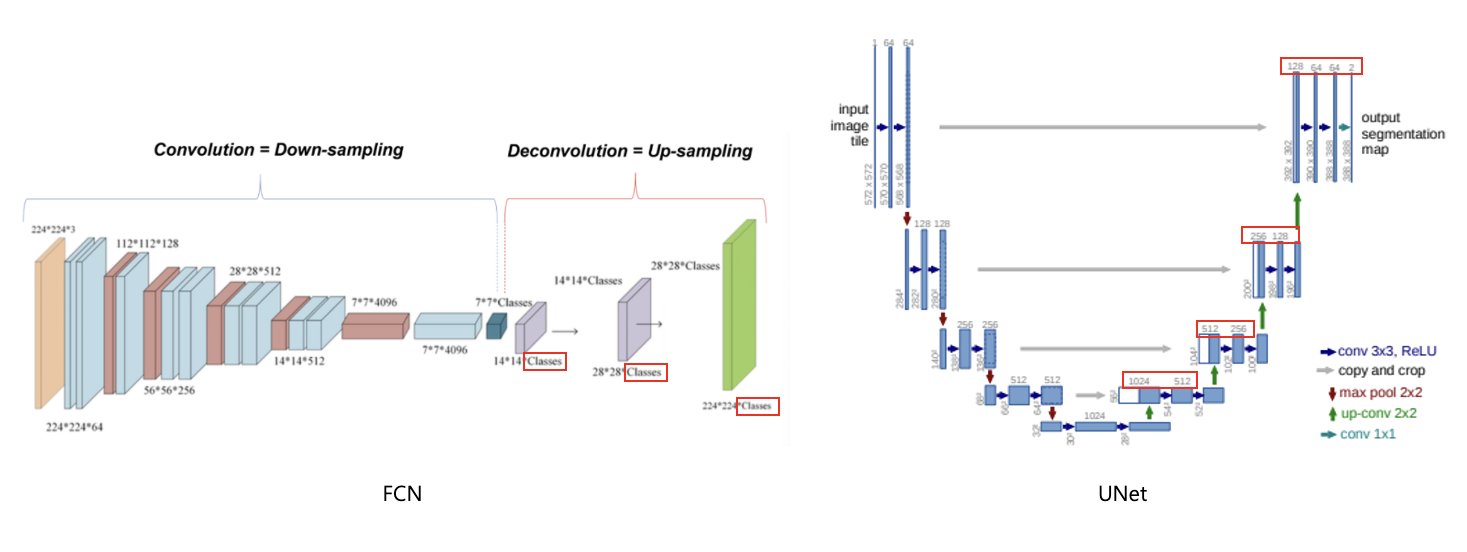
그동안 객체 인식 분야에서 컨볼루션 네트워크를 활용한 수많은 모델들이 있었지만 train dataset과 네트워크의 크기에 영향을 받아 실질적인 사용이 제한적이었다.따라서, 본 논문에서는 적은 데이터로도 학습이 가능한 여러가지 기법들을 소개한다.본 논문은 biomedi
15.[논문리뷰] SSD: Single Shot MultiBox Detector
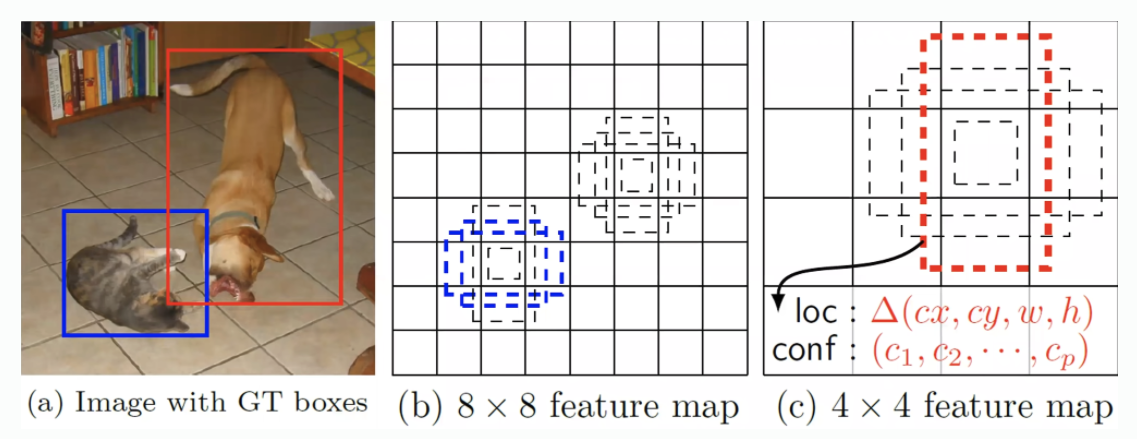
image SSD는 base network로 VGG16을 이용하였다. VGG16에는 FC레이어가 6,7,8로 세 개가 있는데 SDD에서는 6,7은 컨볼루션 레이어로 대체하였고 뒤에 보조적인 구조를 덧붙여 구성하였다. 추가된 레이어를 살펴보면 p개의 채널을 가진 m x
16.[논문 리뷰] Semantic Image Synthesis with Spatially-Adaptive Normalization

본 논문에서는 semantic segmentation mask를 사진처럼 변환해주는 조건부 이미지 합성 방식을 제안한다.기존에도 이와 같은 연구는 있었으나 semantic mask에 대해 "wash away" 현상이 나타난다는 문제점이 있었다.따라서, spatially
17.[논문 리뷰] SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color

딥러닝을 활용한 image completion method로 인해 그림에 전문성이 없는 사람들도 쉽게 이미지를 편집하는 것이 가능해졌다.가장 전형적인 방식은 square mask를 이용하는 것으로 encoder-decoder를 복원하는 생성자와 이를 실제 이미지인지 아
18.[논문 리뷰] Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere

Representation을 학습하는데 있어 $l2$ norm을 통해 feature의 영역을 unit hypershpere으로 제한하는 것은 학습 안정성을 높이고 클래스를 적절히 분류하여 선형 분리가 가능하도록 만든다. $l2$ norm은 보편적인 방법이지만 encod
19.[논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
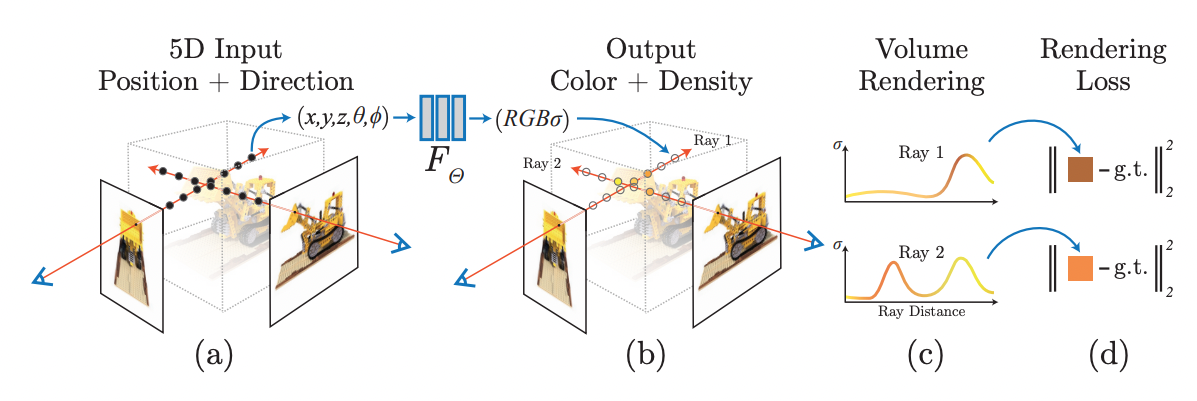
3D point $(x,y,z)$와 viewing directions $(\\theta, \\phi)$로 구성된 5D input을 통해 single volume density와 view-dependent RGB를 output으로 추출하는 view synthesis를 수
20.[논문 리뷰] High Quality Segmentation for Ultra High-resolution Images
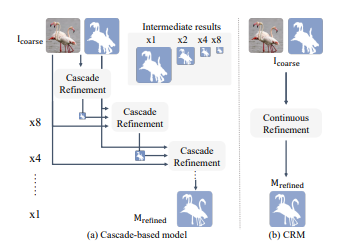
본 연구에서는 cascade기반의 decoder 대신 Continuous Alignment Module(CAM)과 Continuous Refinement Model(CRM)을 사용해 연산량을 줄이고 디테일을 살린다.CAM에서는 feature와 refinement tar
21.[논문 리뷰] SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
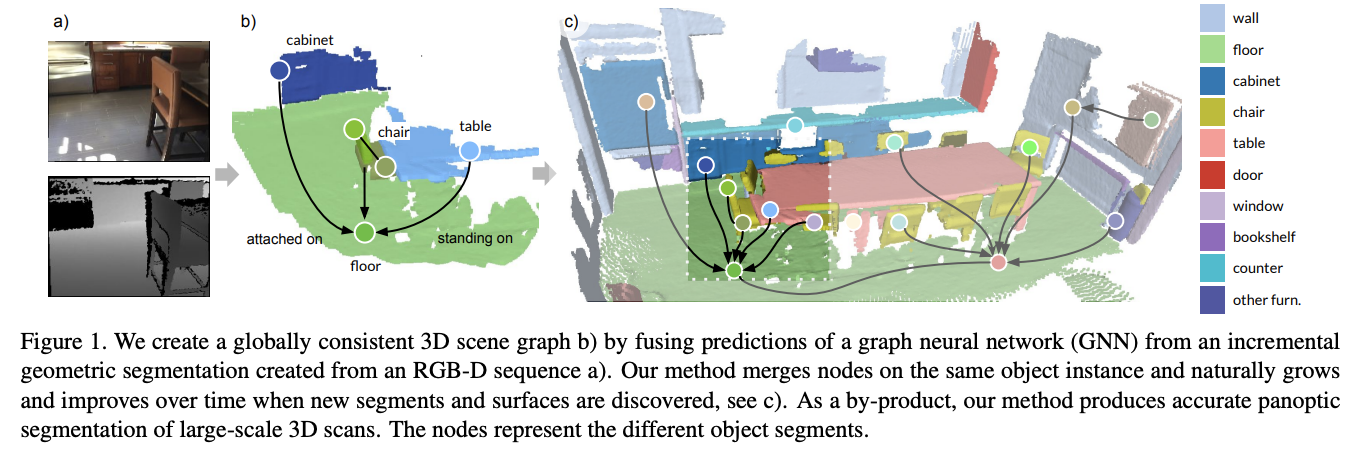
Depth sensor의 이용, real-time dense SLAM 알고리즘의 발달 등과 함께 3D scene reconstruction은 geometric 정보뿐만 아니라 semantic 정보의 복원까지 그 중요성이 부각되었다.그동안의 연구들은 완전한 3D scan
22.[논문 리뷰] DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization

Introduction 일반적인 카메라의 FoV(Field of View)는 60도이기 때문에 context 정보의 활용이 제한적이다. 본 논문에서는 360도 파노라마를 활용하여 obejects' shapes, 3D poses, semantic category, ro
23.[논문 리뷰] MC-Calib: A generic and robust calibration toolbox for multi-camera systems
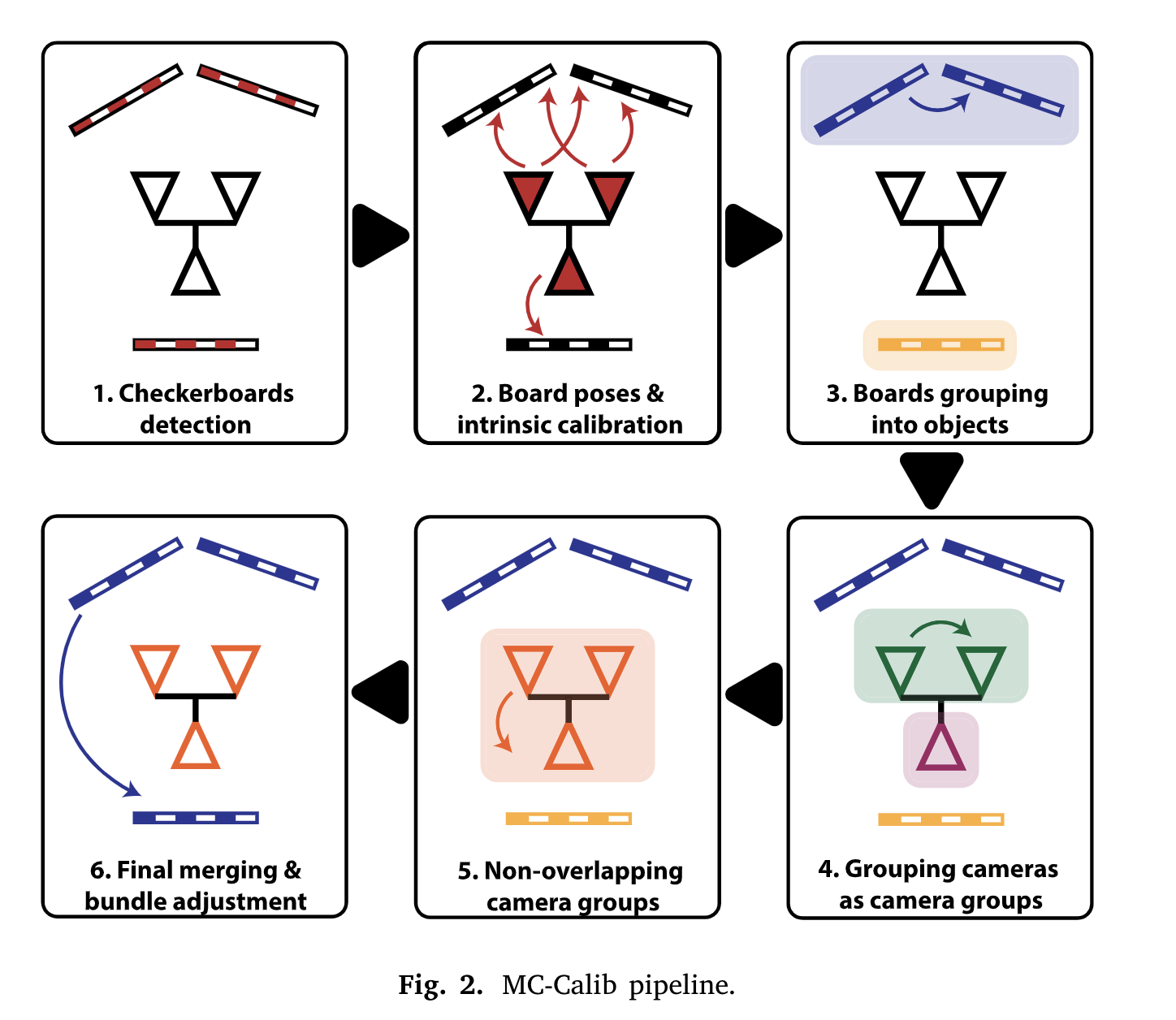
Charuco board detection을 통해 모든 카메라의 intrinsic parameter initializationN-point technique을 통해 관측되는 board에 대한 camera pose에 대해 추정Single image에서 보이는 board
24.[논문 리뷰] Image Generation from Scene Graphs
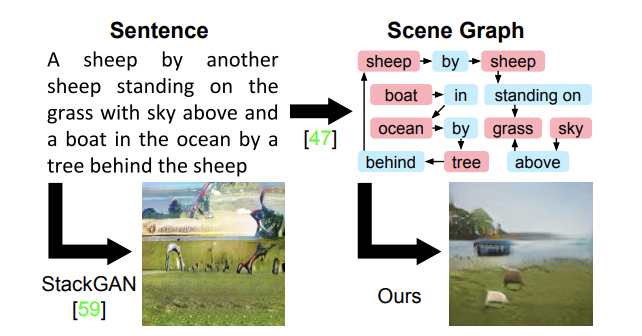
생성 모델의 유용성으로 text로부터 이미지를 생성하는 모델들이 나왔으나 sentence에 많은 object가 존재할 때는 생성에 어려움이 있었다.선형 구조의 sentence를 위 그림과 같이 objects와 relationships로 표현하는 scene grah로 나
25.[논문 리뷰] Knowledge-inspired 3D Scene Graph Prediction in Point Cloud
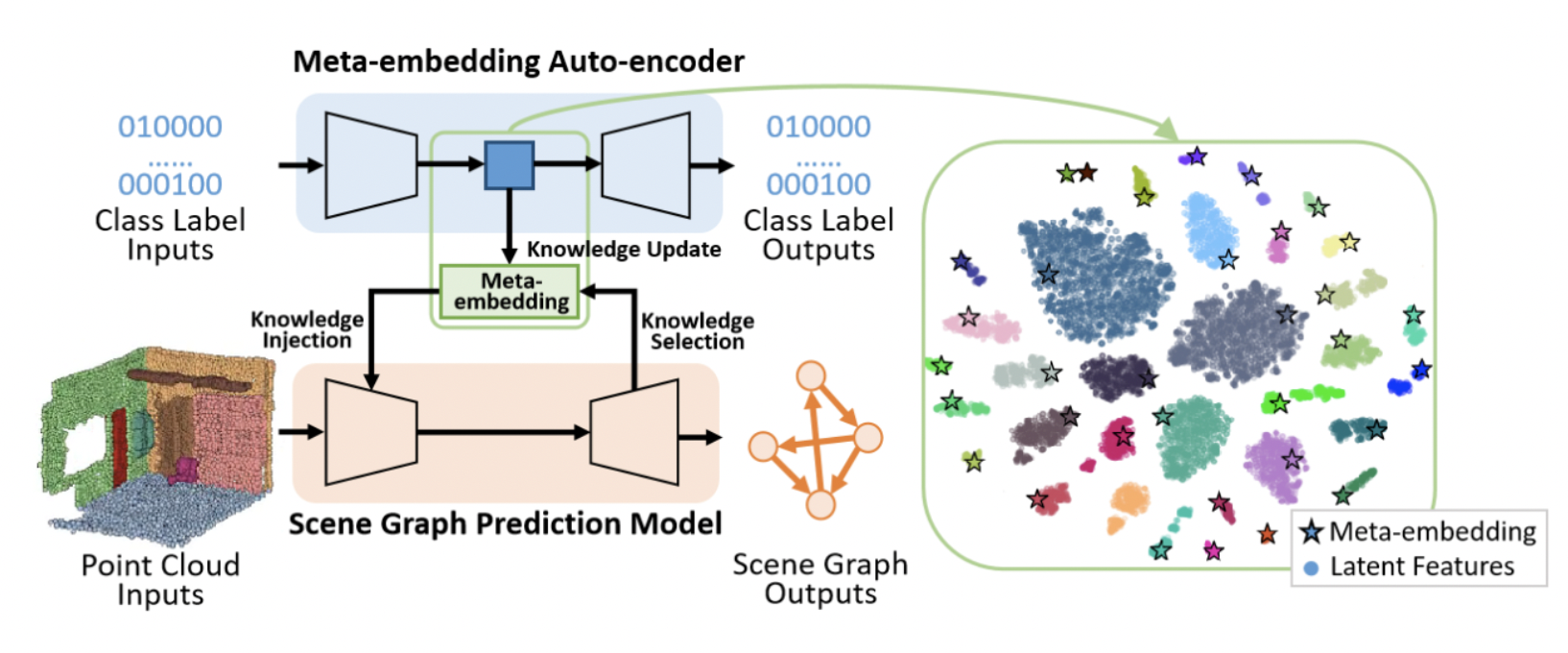
Scene understanding은 AR/VR, robot navigation 등 여러 분야에 유용하지만 scanned 3D data는 incomplete하기 때문에 scene을 정확하게 이해하는데 어려움이 있다.사람은 scene에 대해 이해할 때 visual per
26.[논문 리뷰] Scene Graph Expansion for Semantics-Guided Image Outpainting
Scene graph $\\mathcal{S}=(O,R)$은 N개의 objects $O={oi}{i=1:N}$과 relationship matrix $R=(r\_{ij})\\in\\mathbb{R}^{N\\times N}$으로 구성$oi$는 object label, $
27.[논문 리뷰] LGT-Net: Indoor Panoramic Room Layout Estimation with Geometry-Aware Transformer Network
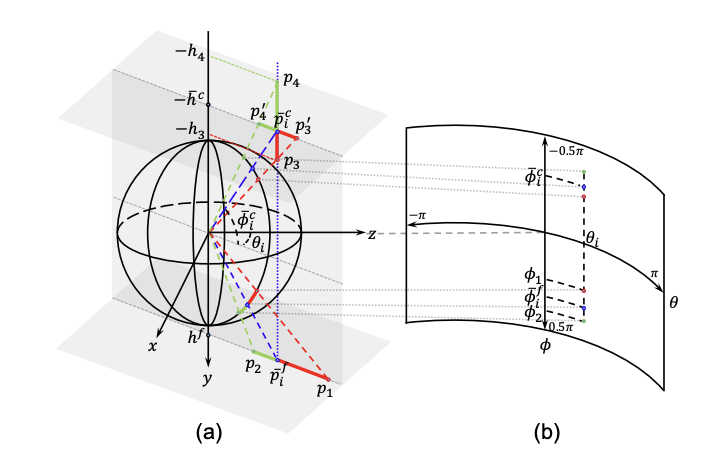
본 논문에서는 room layout을 floor boundary와 room heigth로 표현한다.동일한 경도 간격으로 $N$개(논문에서는 256)의 point를 샘플링한 후 horizon-depth로 변환한다.HorizonNet에서는 floor/ceiling의 위도를
28.[논문 리뷰] Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
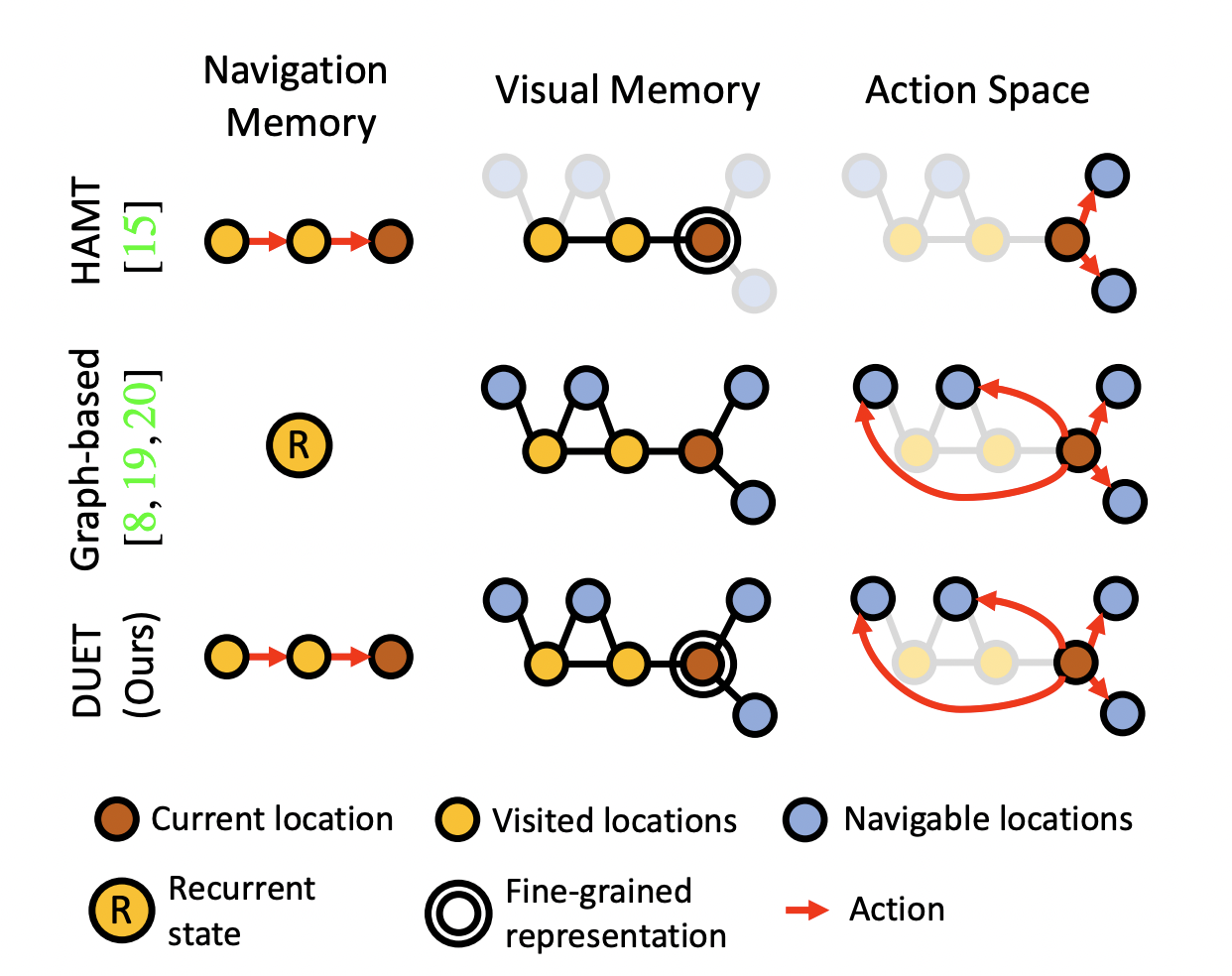
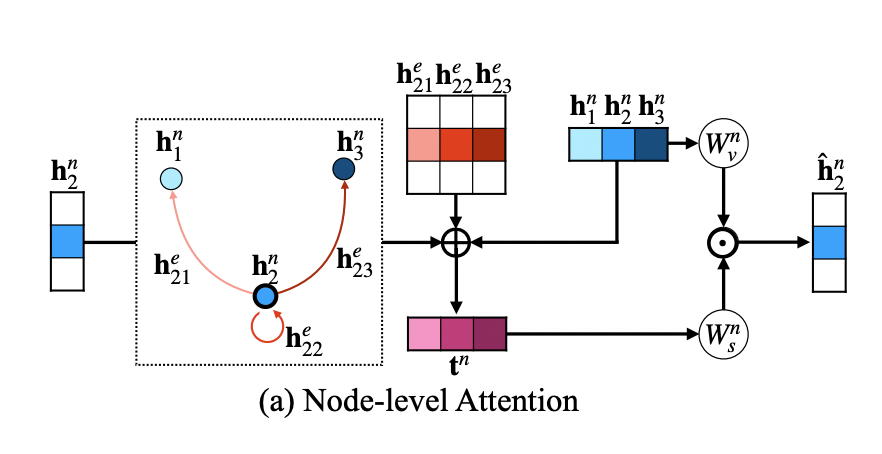
Vision-and-Language Navigation(VLN)은 agent가 language instruction에 따라 unseen environment에서 목적지로 도착하기 위한 task이다초기에는 step-by-step guidance로 세부적인 지시사항을 순차
29.[논문 리뷰] ATISS: Autoregressive Transformers for Indoor Scene Synthesis
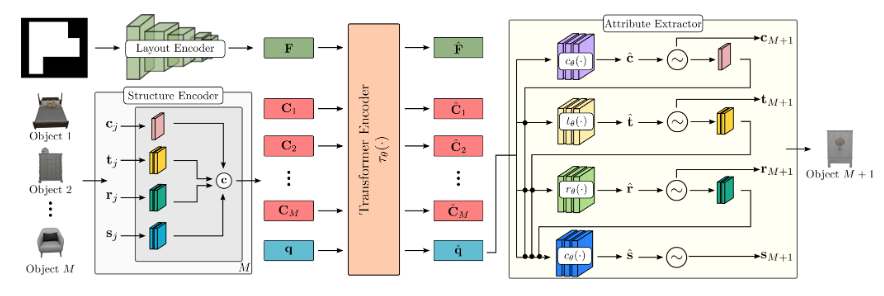
본 논문에서는 비어있거나 일부 objects가 채워진 방이 room type(e.g. bedroom) 및 floor shape과 함께 주어질 때 새로운 object를 배치하는 모델을 만들고자 한다.$\\mathcal{X}={\\mathcal{X}\_1, ..., \\m
30.[논문 리뷰] CPO: Change Robust Panorama to Point Cloud Localization
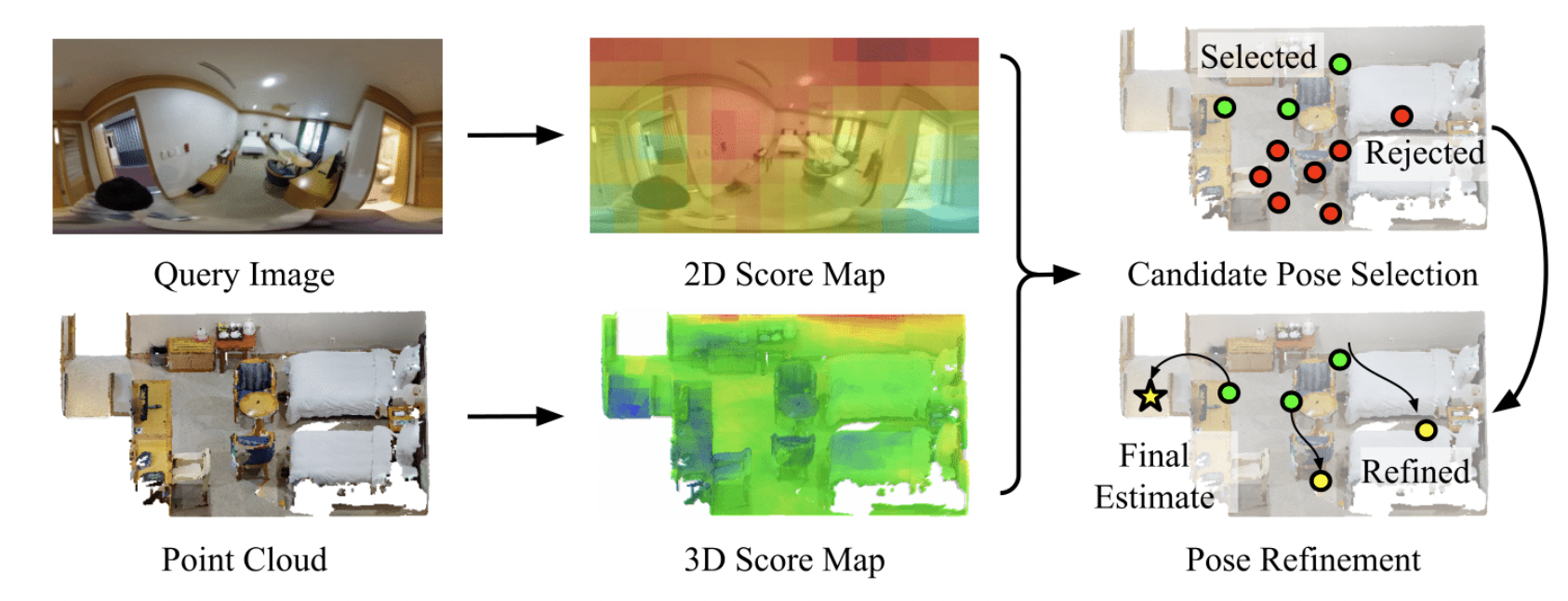
변화가 있는 3D map을 매번 최신 정보로 업데이트하는 것은 많은 비용이 들기 때문에 이러한 변화에도 robust한 localization을 하는 모델이 필수적이다.따라서, 본 논문에서는 regional color distribution을 이용하여 빠르고 변화에 ro
31.[논문 리뷰] P3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior

Monocular depth estiation에서 supervised 방식은 대부분 pixel-level loss를 활용하며 이는 실제 3D scene의 regularity를 반영하지 못한다.3D scene의 geometric한 특성을 활용하기 위한 전형적인 방법으로
32.[논문 리뷰] GEMS: Scene Expansion using Generative Models of Graphs
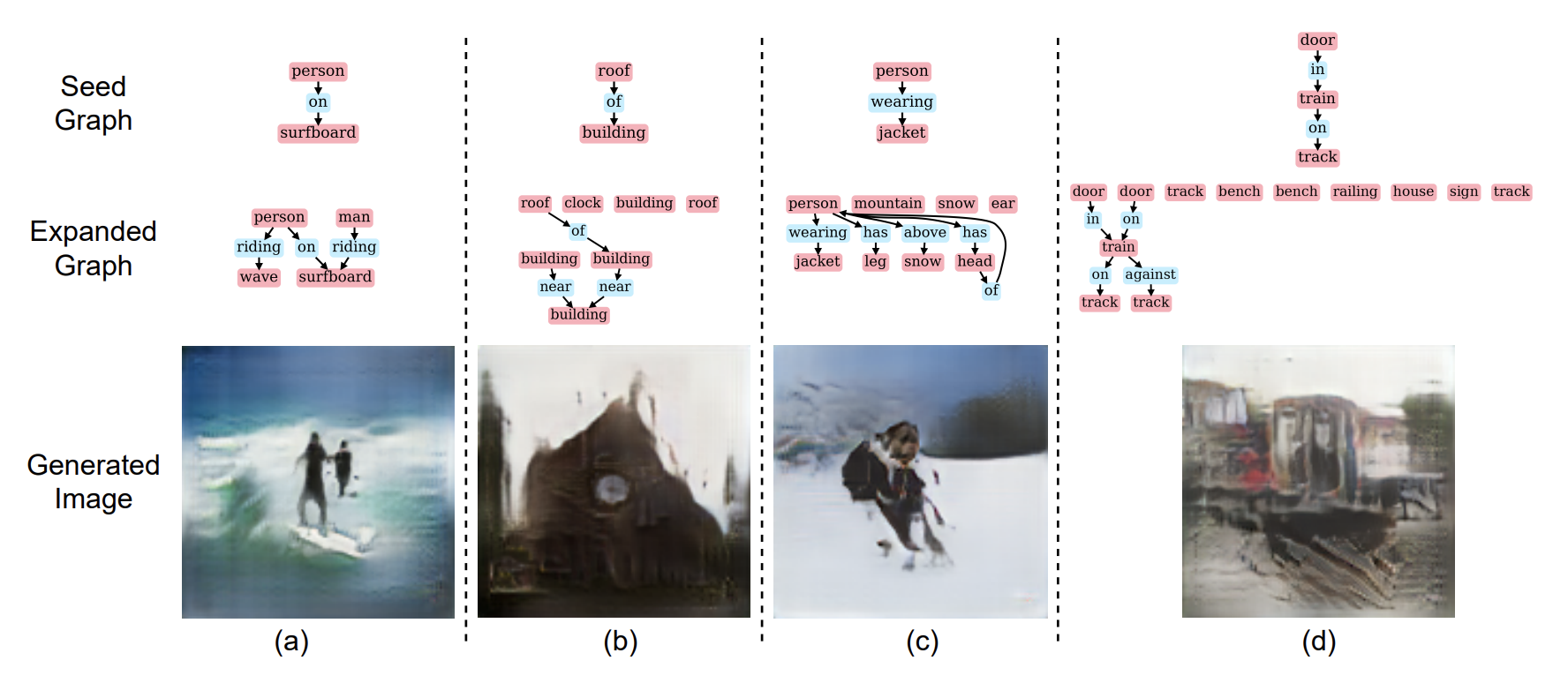
본 논문에서는 seed concept을 포함하는 다양한 scene을 제공해줄 수 있는 알고리즘을 제안한다.Scene graph expansion을 통해 seed graph에 새로운 object들을 추가하며 이 때 충족해야할 조건들은 다음과 같다.제안되는 추가 objec
33.[논문 리뷰] LASER: LAtent SpacE Rendering for 2D Visual Localization
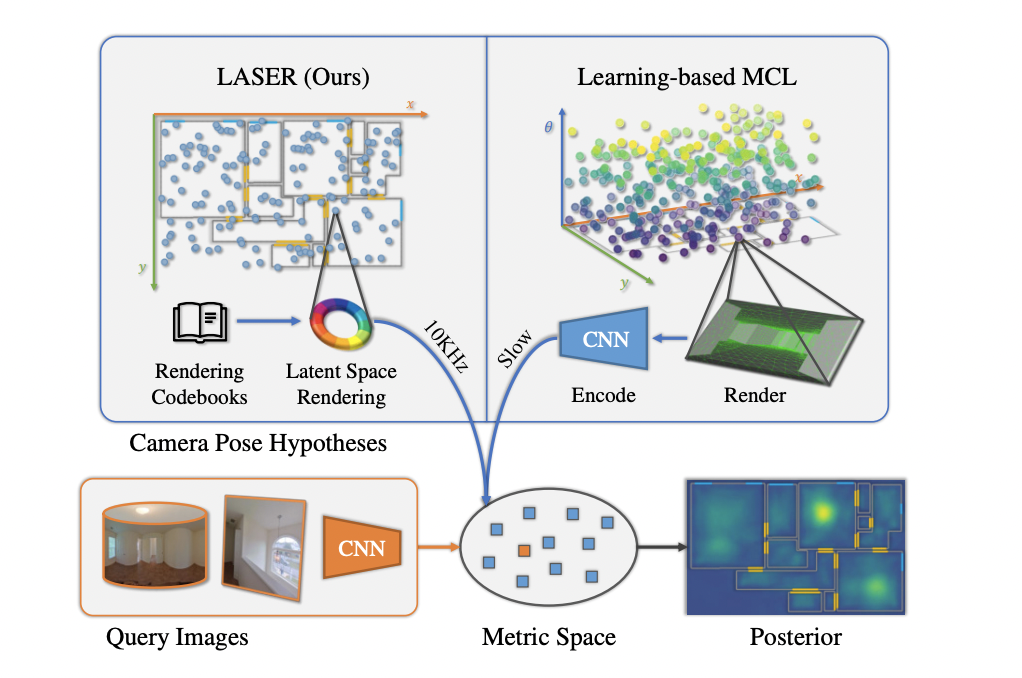
본 연구에서는 Monte Carlo Localization(MCL) framework를 활용해 2D floor map에 대한 query panorama/perspective image가 주어졌을 때 camera pose를 찾는다.MCL은 generative framew
34.[논문 리뷰] Learning Superpoint Graph Cut for 3D Instance Segmentation
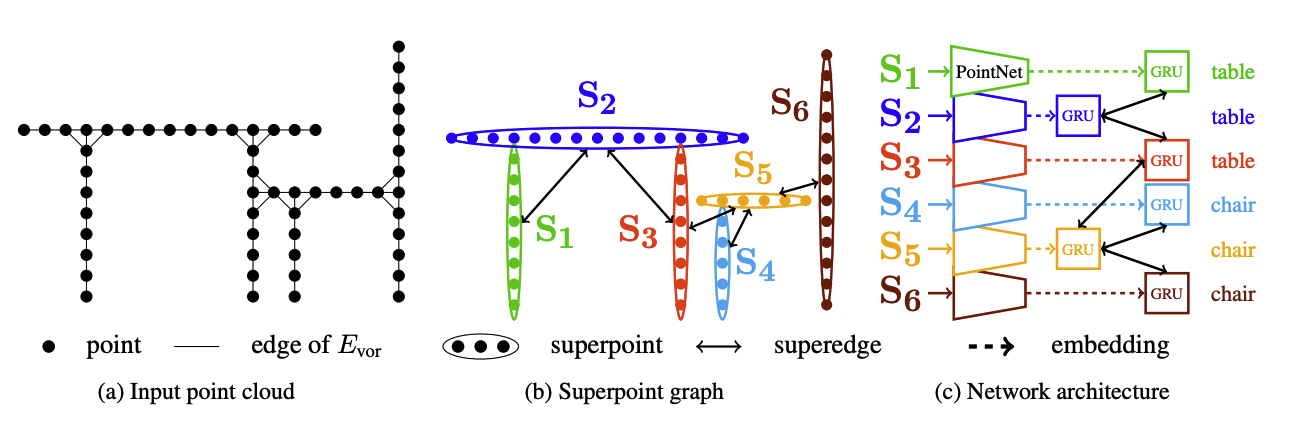
3D point cloud를 input으로 받아 instance segmentation을 하는 task로 기존의 detection-based, clustering-based 방식으로는 복잡한 geometric structure에서 잘 작동하지 못한다.본 논문에서는 su
35.[논문 리뷰] CoVisPose: Co-Visibility Pose Transformer for Wide-Baseline Relative Pose Estimation in 360◦ Indoor Panoramas
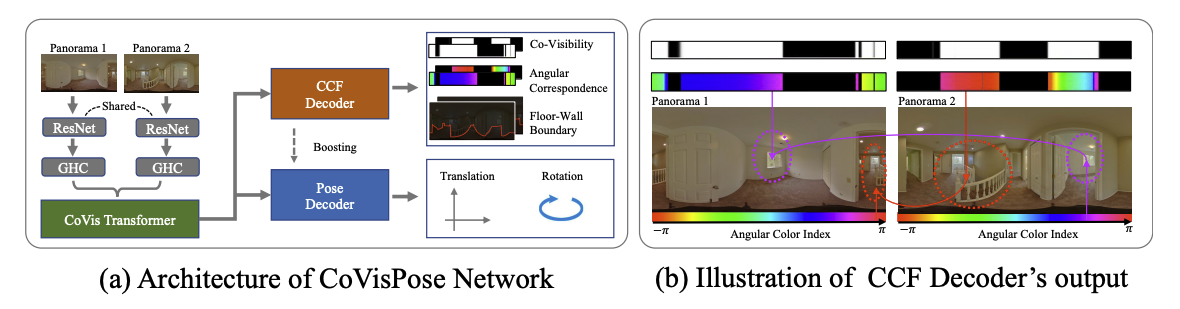
2개의 파노라마 이미지가 input으로 주어질 때 relative pose를 추정하는 연구Featureless region이 많거나 유사한 구조가 많은 이미지의 경우 feature-based 방식은 잘 작동하지 못하며 이를 보완하기 위해 denser RGB나 RGB-D
36.[논문 리뷰] 360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
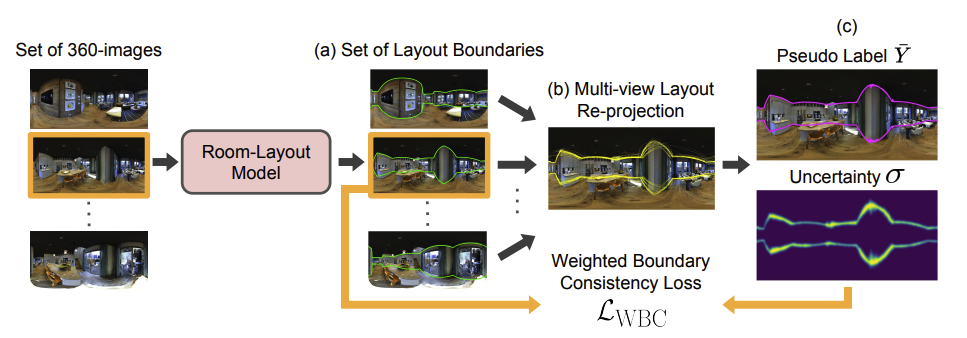
Pre-trained model은 novel view position, different lighting conditions, severe object occlusion과 같은 문제들로 인해 새로운 도메인에서 예측 성능이 떨어진다.이를 보완하기 위해 target dom
37.[Point Review] Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
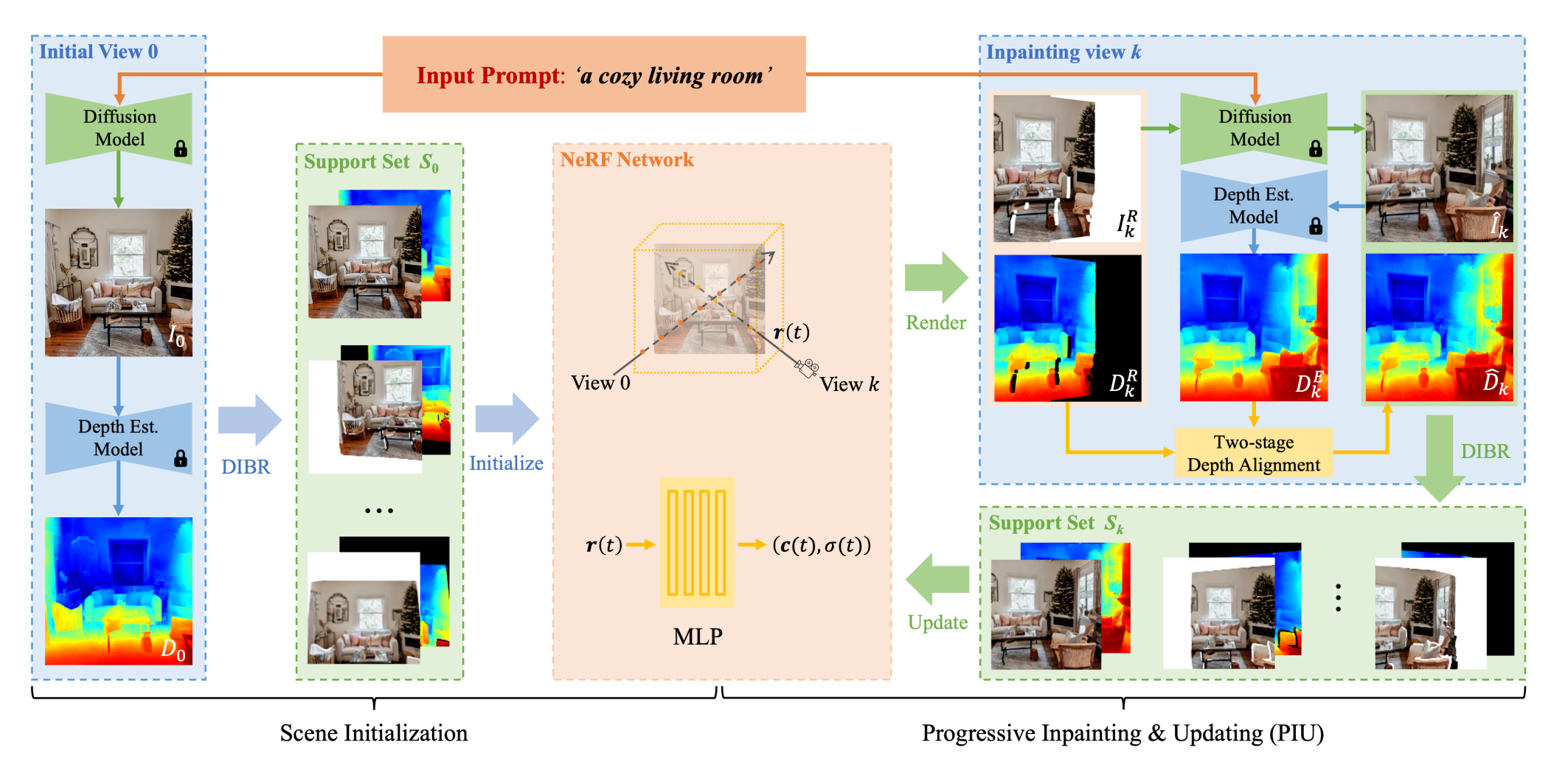
Input prompt $p$를 condition으로 하는 diffusion model로부터 2D image 생성Initial view를 warping하여 multi-view supervision 생성Warping된 이미지의 빈 영역은 다시 $p$를 condition으