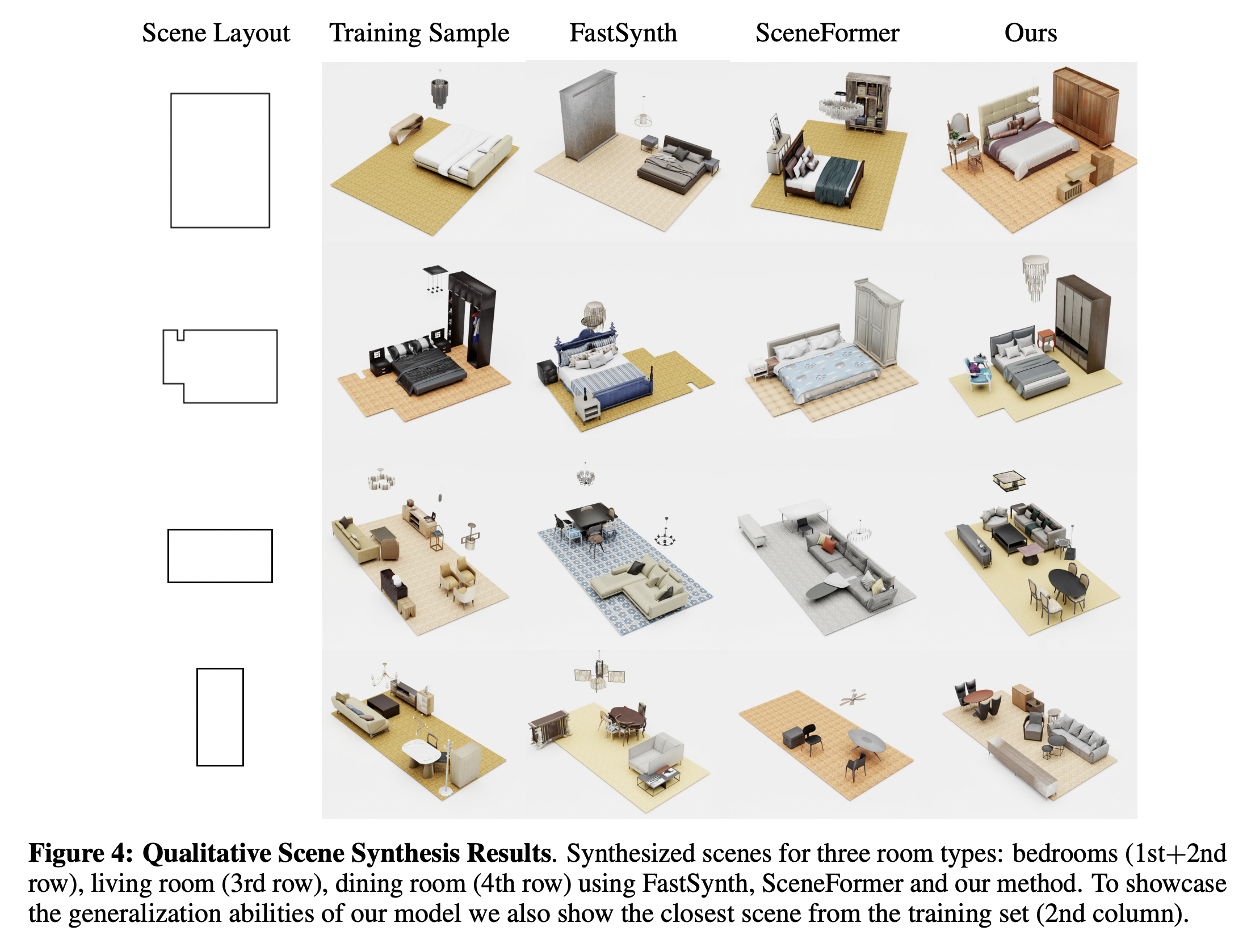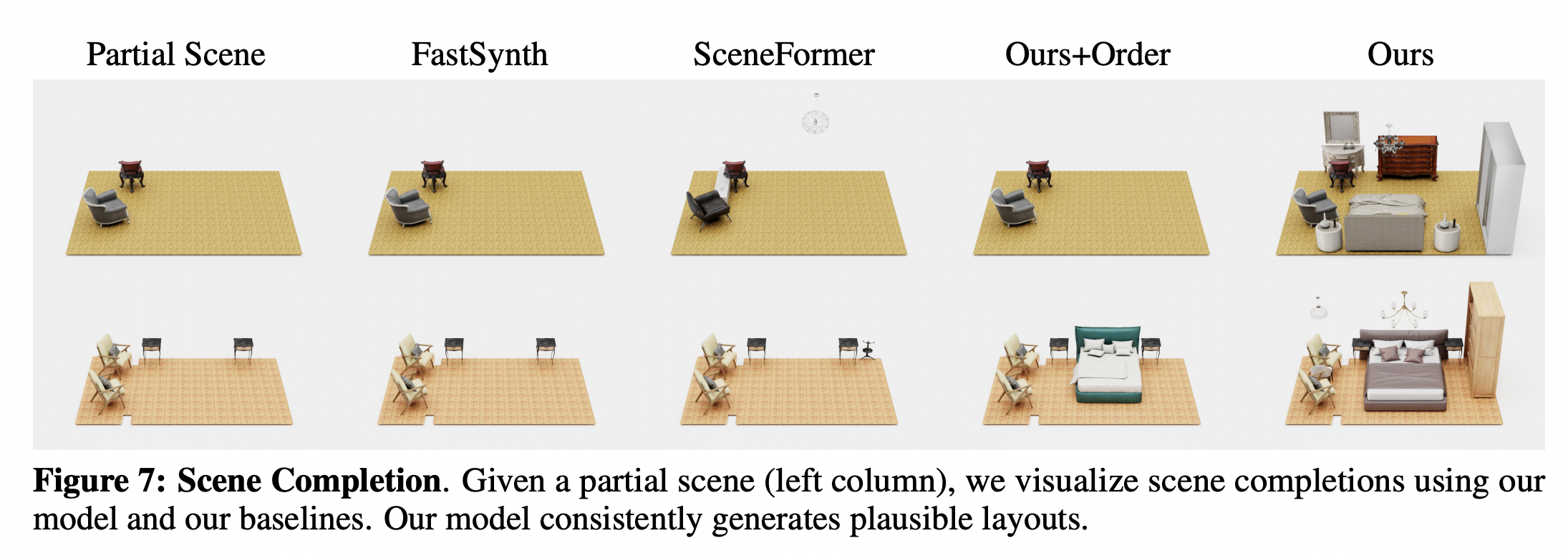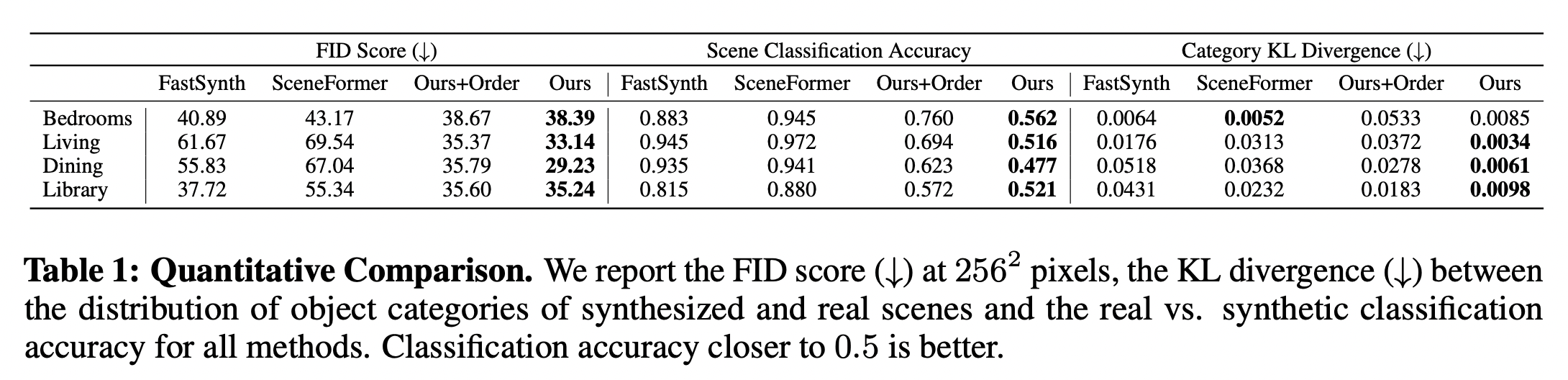
Method
본 논문에서는 비어있거나 일부 objects가 채워진 방이 room type(e.g. bedroom) 및 floor shape과 함께 주어질 때 새로운 object를 배치하는 모델을 만들고자 한다.
Autoregressive Set Generation
- 이 scene들의 집합이고 각 scene은 unorderd set of objects 와 floor layout 로 구성된다.
- 가 생성될 liklihood는 가 생성될 liklihood를 순서에 영향을 받지 않고 autoregressive하게 누적하여 구할 수 있다.
- 집합에 대한 전체 log-liklihood는 (2)와 같이 표현할 수 있다.
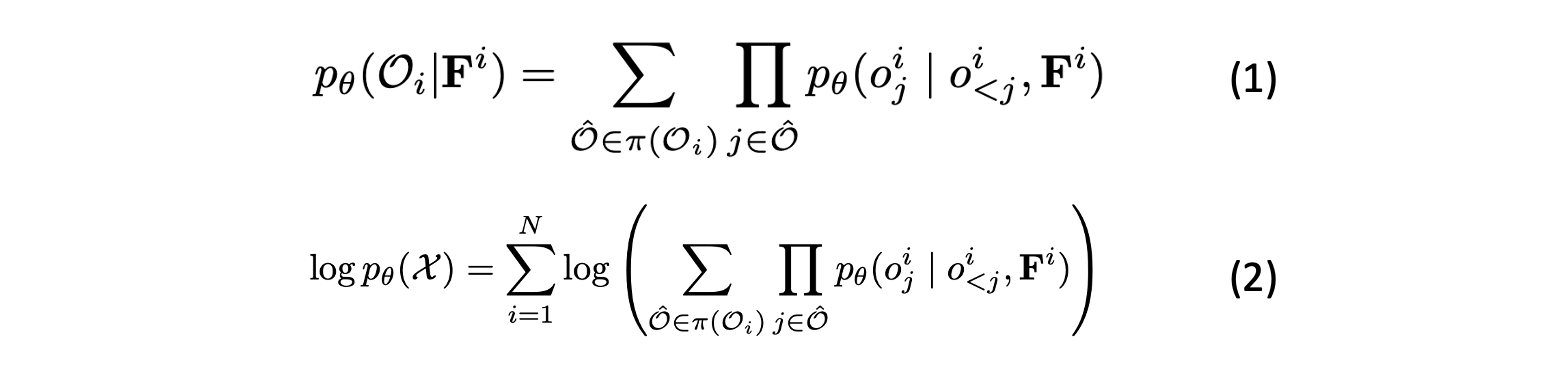
floor layout과 이전에 생성된 object들이 주어졌을 때 번째 object가 생성될 확률
모든 objects의 permutations 집합을 계산하는 permutation fucntion
- 하지만, MLE를 통해 generative model을 학습시키는 것은 모든 permutations에 대한 합을 다루기 어렵고 모든 ordering이 높은 확률을 가질 것을 보장 못한다는 문제점이 있다.
- 따라서, (2)를 maximize 하는 대신 모든 orderings에 대해서 scene을 생성시킬 liklihood를 maximize하는 것으로 문제를 재정의한다.
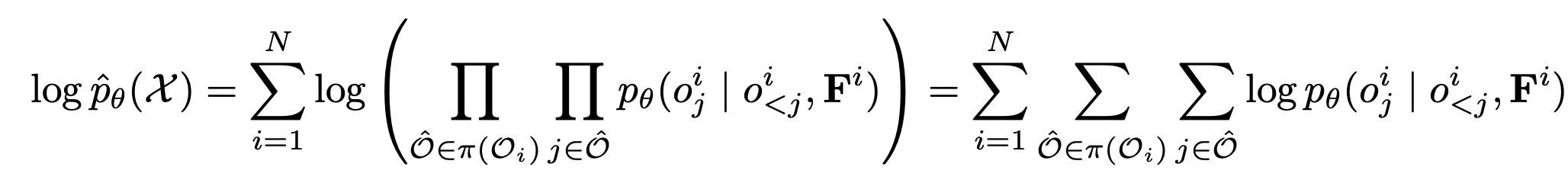
Modeling Object Attributes
- Objects는 labeled 3D bounding boxes와 4개의 random variable category, size, orientation, location로 나타낸다.
- Autoregressive하게 category, position, orientation, size 순서로 예측한다.
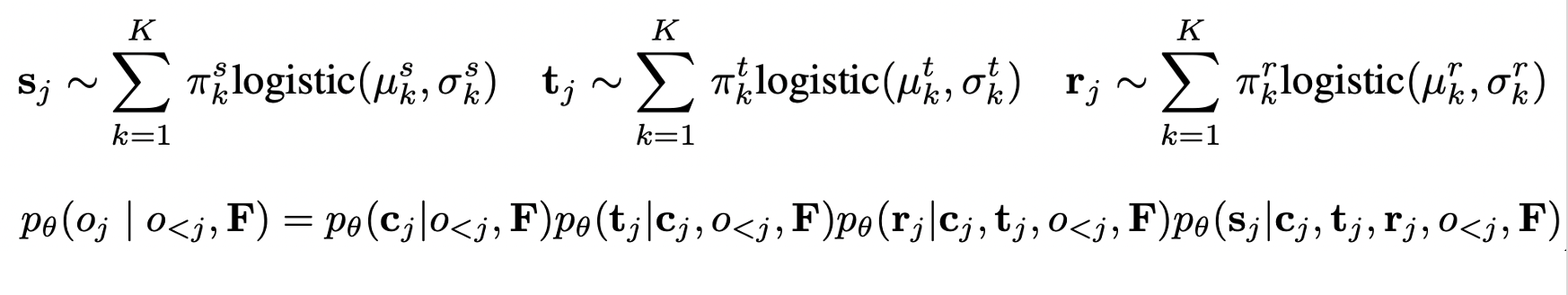
각 varialbe을 modeling 하기 위해 사용되는 번째 logistic distribution의 weight, mean, variance
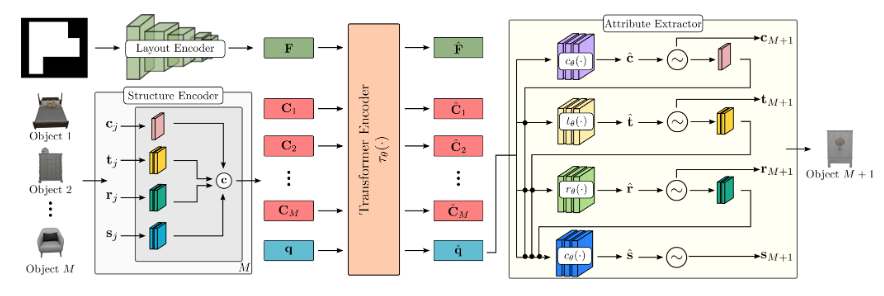
Network Architecture
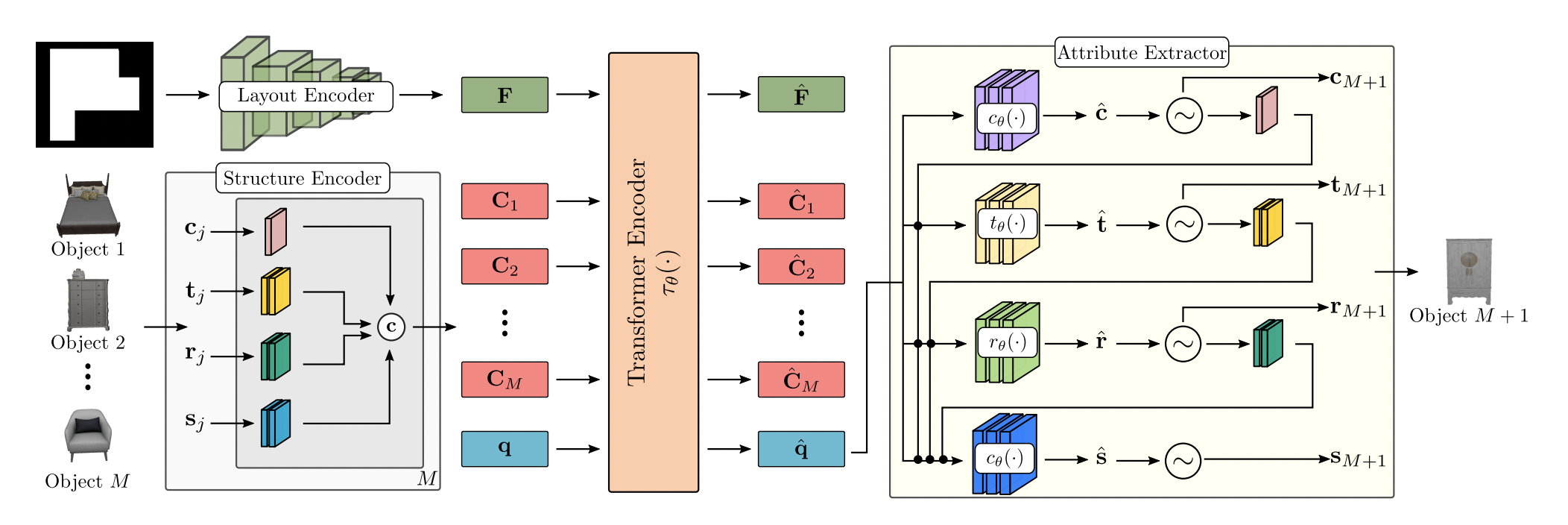
- Network는 layout encoder, structure encdoer , transformer encoder , attribute extractor로 이루어진다.
Layout Encoder
- ResNet-18을 통해 floor shape으로부터 feature representation 를 뽑아낸다
Structure Encoder
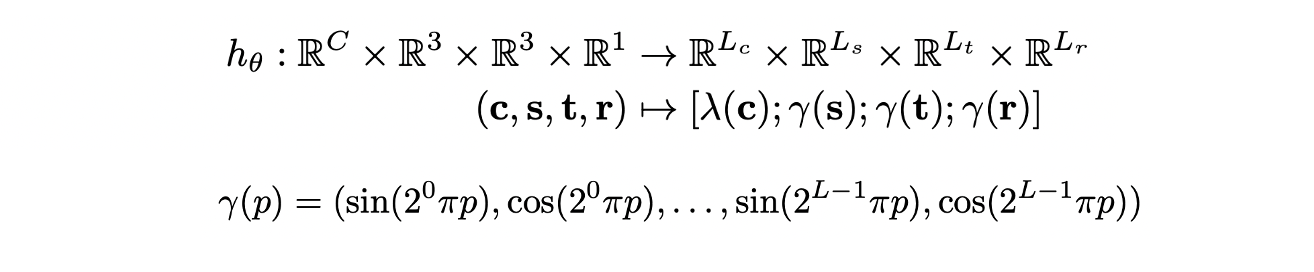
- 번째 object의 attribute를 per-object context embedding 로 mapping한다.
- size, position, orientation에 대해서는 positional encoding을 적용하고 category에 대해서는 learnable embedding 을 적용한 후 concat 한다.
- 는 다음 object를 예측하기 위한 condition으로 주어지며 transformer encoder를 통과하기 전에 64차원으로 mapping 된다.
Transformer Encoder
- Positional encoding 없이 multi-head attention transformerfmf 수행하여 order invariant한 feature를 뽑는다.
- 를 input로 받으며 는 query token으로 mask embedding 역할을 하여 다음 object를 예측한다.
Attribute Extractor
- MLP를 통해 attribute를 autoregressive하게 예측한다.
- 에 대해서는 개의 class 확률을 예측하며 에 대해서는 logistic distribution의 mean, variance, mixing coefficient를 예측한다.
Training
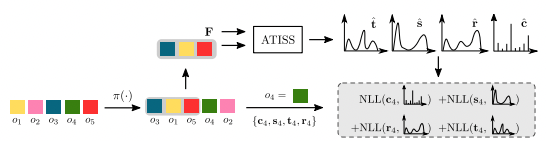
- Scene의 개의 objects에 대해 random permutation을 적용한 후 개의 objects를 랜덤하게 선택하여 context embedding 를 추출한다.
- 가 주어졌을 때, 네트워크에서 다음 object의 attribute distribution을 예측하며 object의 log-likelihood를 maximize 하도록 학습한다.
Inference
- Empty context embedding 와 로 시작해 predicted distribution으로부터 attribute values를 샘플링한다.
- Object가 생성되며 context 에 추가하여 다음 object를 생성하는데 활용하며 end symbol이 나올때 종료한다.
- 예측된 labeld bounding boxes를 3D model로 transform 할 때는 bounding box dimension의 dataset에서 euclidean distance가 가장 가까운 object를 retrieve 한다.
Experiments