Introduction
- 본 연구에서는 cascade기반의 decoder 대신 Continuous Alignment Module(CAM)과 Continuous Refinement Model(CRM)을 사용해 연산량을 줄이고 디테일을 살린다.
- CAM에서는 feature와 refinement target을 continuous space로 보내 position과 feature를 align한다.
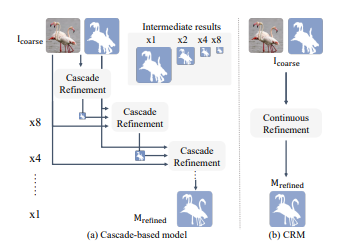
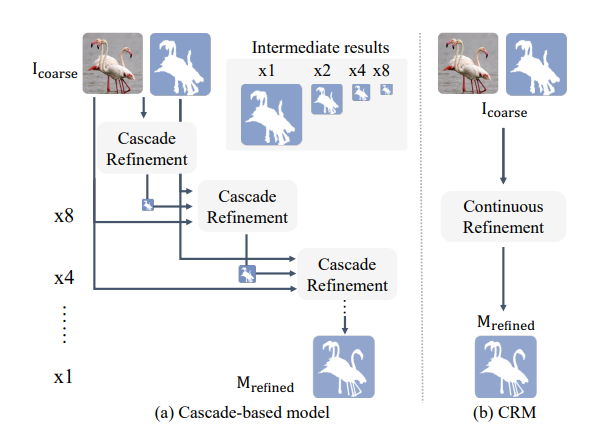
- Low-resolution mask를 cascade 방식을 통해 해상도를 키우는 것은 시간이 많이 소모되며 일반화 성능이 떨어지기 때문에 CRM에서는 implicit function을 통해 이를 대체한다.
- 학습과 추론 시 사용하는 해상도가 다른 resolution gap을 위해 multi-resolution inference를 이용한다.
Proposed Method
General Framework
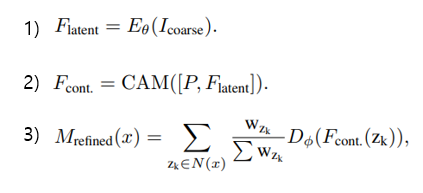
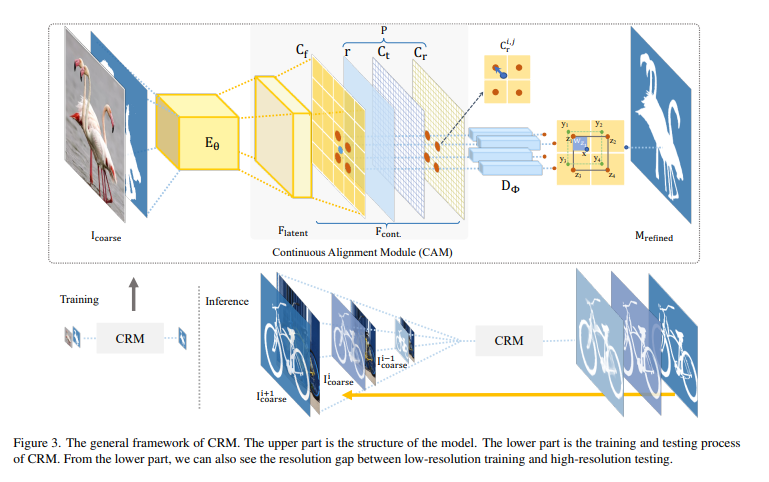
- 1) 이미지와 coarse segmentation mask를 concatenation하여 input으로 사용하며 인코더를 거친 latent embedding 얻는다.
- 2) CAM을 통해 과 위치 정보를 가진 를 연속적으로 align하여 target size feature인 를 만든다.
- 3) 는 implicit funtion을 활용한 디코더 와 aggregation 과정을 거쳐 refined mask 를 생성한다.
- : aligned point
- : 의 supporting point 의 집합.
- : aggregation weights
- : 상에서 의 특징벡터
Continuous Alignment Module
- 기존 연구들의 cascade decoder는 up-sampling 과정에서 정보의 손실이 있어 디테일을 보존하는데 한계가 있다.
- 또한, up-sampling 비율을 미리 정하는 discrete한 방식이기 때문에 generality를 낮추고 모델이 복잡해 시간이 오래 걸린다.
- 따라서, 위치 정보와 특징 정보를 align시키는 CAM을 사용하여 continuous deep feature 를 얻는다.
Position Information
- Refinement target의 좌표 를 feature map의 좌표 로 projection
다른 해상도에서 연속적인 좌표를 생성. Inference 시에 다양한 해상도를 이용할 수 있다. - CRM을 다양한 크기의 이미지에 대해 수행 가능하도록 하기 위해 은 [-1,1]로 정규화한다.
- Projection 이후 의 point와 이에 상응하는 의 포인트 간의 offset은 로 정의된다. 은 에서의 offset으로 위 그림에서 파란색 화살표에 해당한다.
- 은 feature와 target 간의 비율을 의미한다.
- 위치 정보 는 로 이루어진다.
Continuous Feature Alignment
- Segmentation refinement task를 위해 는 global-local 정보를 fusion하여 강화될 필요가 있다.
- 는 global feature라 할 수 있으며 refinement target의 각 픽셀을에 align 한 뒤 와 를 concatenation하여 continuous feature 를 만든다.
Implicit Function in CRM
Implicit function 는 CAM의 output 를 input으로 받으며 output은 가중치를 적용하여 aggregate한다.
- Queried point(파란 점)은 로 정의되며 정규화되지 않은 위치 정보이다.
- Neighbor point(녹색 점)은 target refinement mask 상에서 에 해당하는 점으로 로 정의된다.
- Supporting point(빨간 점)은 aligend feature map 상에서 과 가장 가까운 점으로 로 정의된다.
- : 의 특징 벡터
- : aggregation weights = area value
Loss funtion
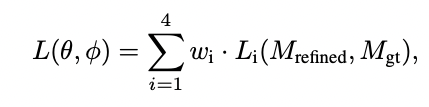
- : cross entropy, L1 loss, L2 loss, gradient loss
- : encoder 와 decoder 의 파라미터
Inference Strategy
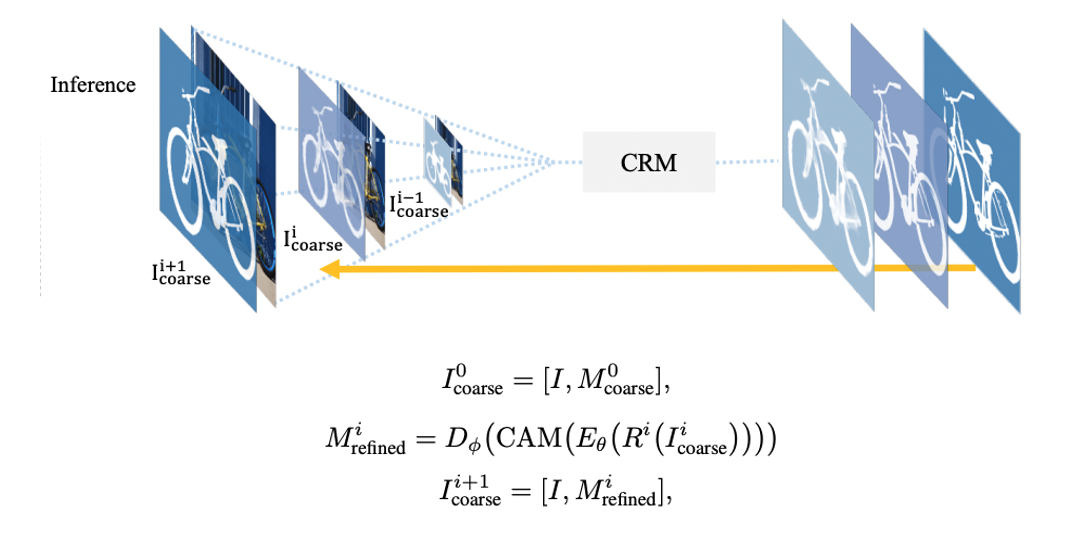
- 학습 시에는 300~1K의 해상도를 사용하고 추론 시에는 2K~6K를 사용하는 resolution gap을 위해 multi-resolution inference를 제안한다.
- 처음에는 학습 이미지와 유사한 해상도를 inference하며 점차 해상도를 키워나간다.
- 는 rescale function을 의미하며 는 refinement stage이다.
- 아래 그림이 refinement step을 거친 결과로 왼쪽->오른쪽, 위->아래 순서대로 와 0.125, 0.25, 0.5, 1.0의 비율도 rescale한 결과이다.

