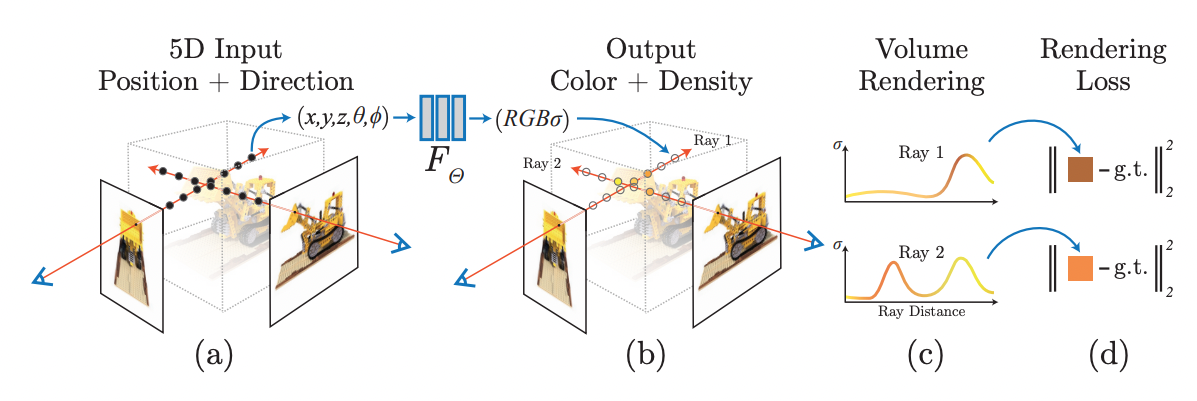
Introduction
- 3D point 와 viewing directions 로 구성된 5D input을 통해 single volume density와 view-dependent RGB를 output으로 추출하는 view synthesis를 수행하여 렌더링을 한다.
- 즉, 가 MLP를 거쳐 를 output으로 나오게 만드는데 단순히 이 방법만으로는 high resolution의 representation을 충분히 반영하지 못한다.
- 따라서, positional encoding과 hierarchical sampling이라는 기법을 추가적으로 소개한다.
- 기존에는 Voxel, Point cloud, Mesh 등의 discrete한 방법을 많이 사용하였으나 본 논문에서는 MLP를 사용하여 continuous한 implicit(coordinate-based) representation(픽셀별 RGB값을 얻는다)을 나타낸다.
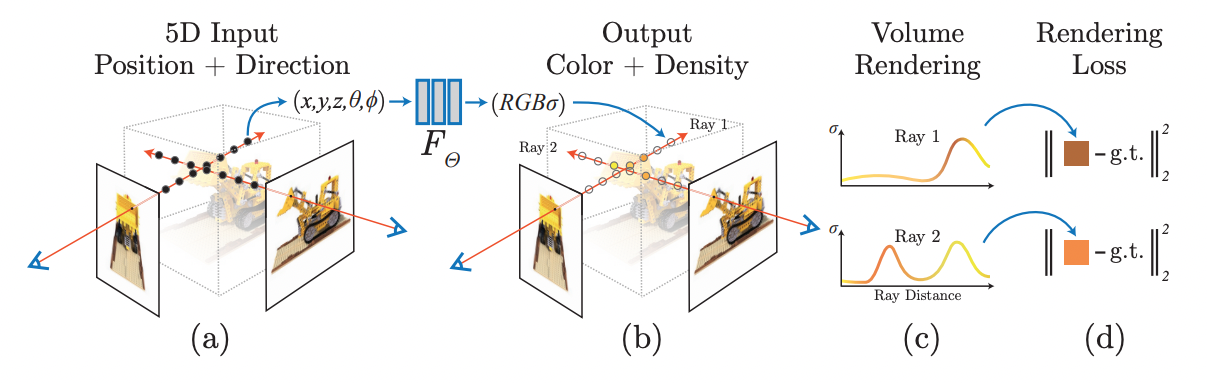
a) camera ray를 따라 5D coordinates를 샘플링한다.
b) 5D coordinates를 MLP에 통과시켜 volume density와 RGB값을 얻는다.
c) classic volume rendering 기법을 활용하여 렌더링을 한다.
d) GT 이미지와 렌더링된 이미지의 차이를 최소화하여 최적화시킨다.
Classic Volume Rendering

- Volume Ray Casting이란 3D 이미지를 특정 view point에서 바라볼 때 가지는 2D 이미지의 색상을 계산하는 것
- ray를 의미하는 는 눈 지점인 와 방향벡터 의 합으로 표현할 수 있다.
- 과 는 각각 관심영역의 시작점과 끝점을 의미한다.
- 그 사이 임의의 지점 에 대해 volume density인 와 색상 을 알고 있다면 2D로 투영되는 색상 을 구할 수 있다.
- 는 지점에서의 색상을 가리는 particle들의 밀도가 높을수록 작으므로 투과율을 의미한다.
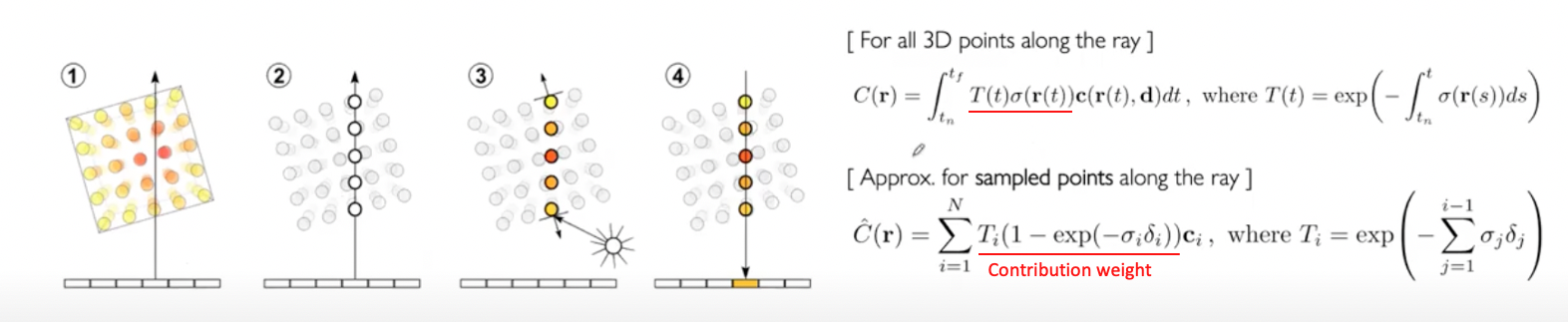
- 위 과정에서 모든 에 대한 정보를 얻을 수는 없기에 discrete하게 샘플링을 한다.
- 는 샘플링된 점들의 간격을 의미하며 위 식들에서 앞부분이 해당 색상이 2D 이미지에서 나타나는 색상에 반영되는 정도이기에 contribution weight라고 볼 수 있다.
- Loss는 total squared error를 사용하며 coarse network와 fine network를 모두 구한다.
Hierarchical volume sampling
Coarse Network
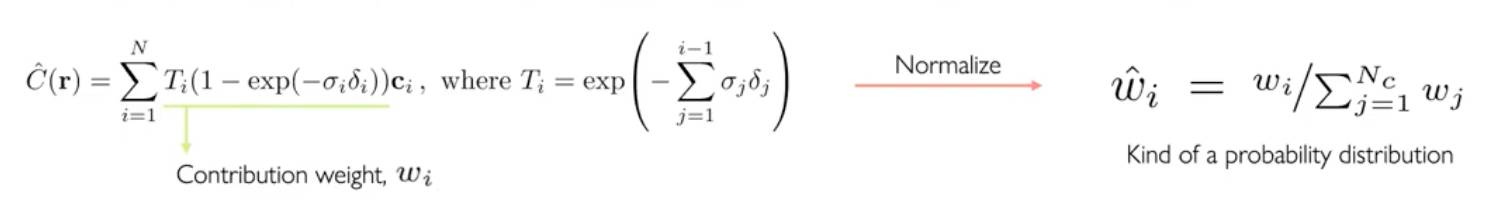
- Stratified sampling으로 (=64)개의 포인트를 뽑고 는 정규화한다.
- 이렇게 추출한 샘플들은 에 대해서 분포를 나타낼 수 있고 이 분포는 fine network를 위한 샘플링을 하는데 활용된다.
Fine Network

- 공기 부분에 해당하는 것보다는 을 구하는데 기여도가 높은 즉, 가 큰 곳에서 샘플링을 많이 하는 것이 좋기 때문에 위에서 구한 PDF를 활용한다.
- PDF를 통해 CDF를 구하고 로부터 균일한게 점을 찍어 이에 상응하는 를 찾아 샘플링하는 Inverse transform sampling을 활용한다.
Positional encoding
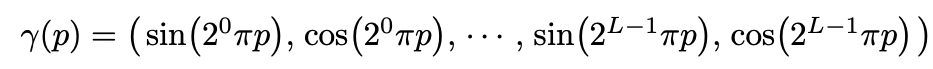
- 5D input을 바로 MLP에 넣는 것이 high frequency를 학습하는데 좋지 않아 고차원의 공간()으로 맵핑하는 과정을 거친다.
- 에서의 , 에서의
MLP Network
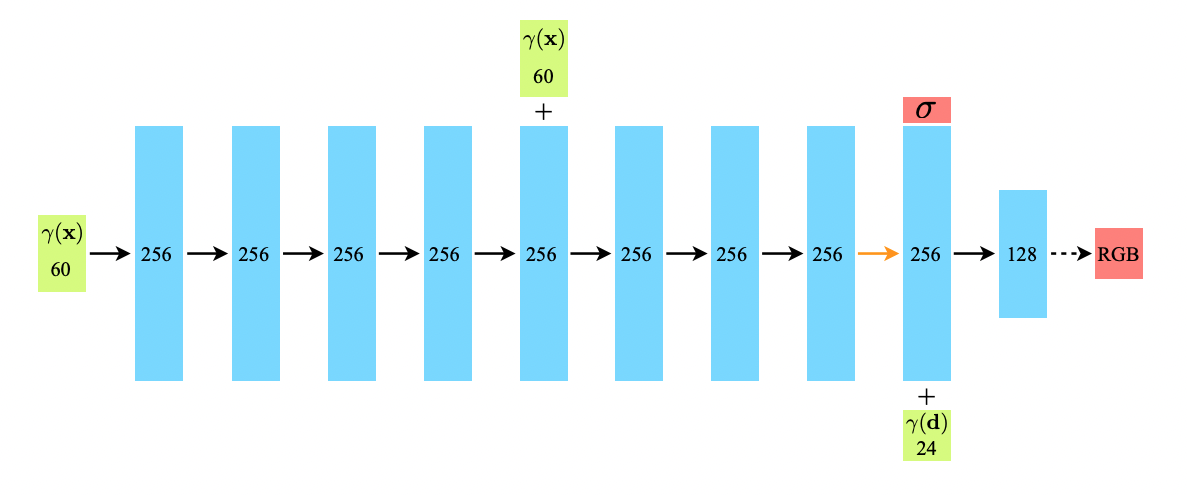
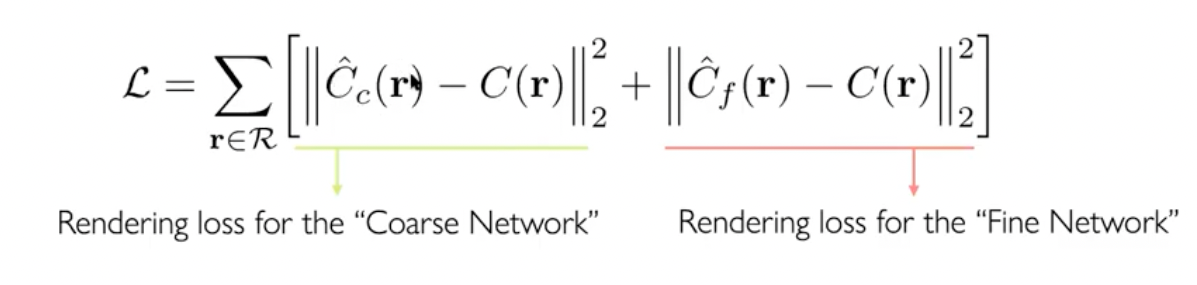
- 3D location 와 2D viewing direction 를 받아 해당 location에서 방출하는 color 와 volume density인 를 얻는 MLP 네트워크 를 구성한다.
- MLP는 먼저 3D 좌표 를 8개의 FC layer에 통과시켜 와 256차원의 특징 벡터를 얻은 뒤 viewing direction을 concatenation 하여 하나의 FC layer에 통과시켜 RGB값을 얻는다.
