[논문 리뷰] SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
논문

Introduction
- 딥러닝을 활용한 image completion method로 인해 그림에 전문성이 없는 사람들도 쉽게 이미지를 편집하는 것이 가능해졌다.
- 가장 전형적인 방식은 square mask를 이용하는 것으로 encoder-decoder 구조를 활용한 생성자와 이를 실제 이미지인지 아닌지 구분하는 판별자로 구성된다.
- 하지만 이와 같은 방식은 해상도가 낮고, 엣지 부분이 어색하며, 사용자가 원하는대로 만들 수 없다는 단점이 있다.
- 따라서, 본 논문에서는 사용자가 색상이 포함된 간단한 스케치만으로 이미지를 고해상도로 편집할 수 있는 SC-FEGAN을 제안한다.
Related work
Deepfill v2
스케치를 input으로 사용하나 색상은 부여할 수 없다.
Guided Inpainting
삭제된 부분을 복구하기 위해 다른 이미지를 활용한다. 사용자가 원하는 부분을 추론하기 어렵기 때문에 디테일한 부분을 복원할 수 없다.

Ideep color
색상을 지정하여 바꿀 수 있으나 삭제된 부분을 복원하거나 구조를 바꿀 수 없다.

FaceShop
본 논문과 같이 스케치와 색상 변경이 모두 가능하나 두 가지 문제점이 있다. 첫째, random rectangular rotatable mask를 사용하여 판별자에서 local path를 resize해야 한다. 이 과정에서 정보가 왜곡되며 부자연스러운 엣지가 형성된다. 둘째, 제거되는 영역이 넓을 경우 정상적으로 복원하지 못한다.

Training data
이미지를 학습시키기 위해 다음과 같은 전처리 과정들을 거쳤다.
- CelebA-HQ 데이터셋을 사용하였으며 랜덤하게 2세트의 29000개 training dataset과 1000개의 test dataset을 뽑았다.
- 스케치 및 컬러 데이터셋을 확보하기 전에 512x512로 resize 해준다.
- 눈의 복잡한 형태를 잘 표현하기 위해 눈 부분에 free-form mask를 활용하였으며, 특수한 특성을 가지는 머리카락 부분에도 랜덤하게 GFC를 활용한 마스크를 적용하였다.
- 스케치 도메인은 HED로 엣지를 추출한 뒤 커브를 완만하게 만들고 작은 엣지들을 제거하여 얻는다.
- 컬러 도메인은 median 필터로 이미지를 blur하게 만든 뒤 GFC를 통해 영역을 분할하고 중위값으로 색상을 부여한다.

결과적으로 본 논문에서는 아래 그림과 같이 5개의 이미지로 input이 구성된다.

Architecture
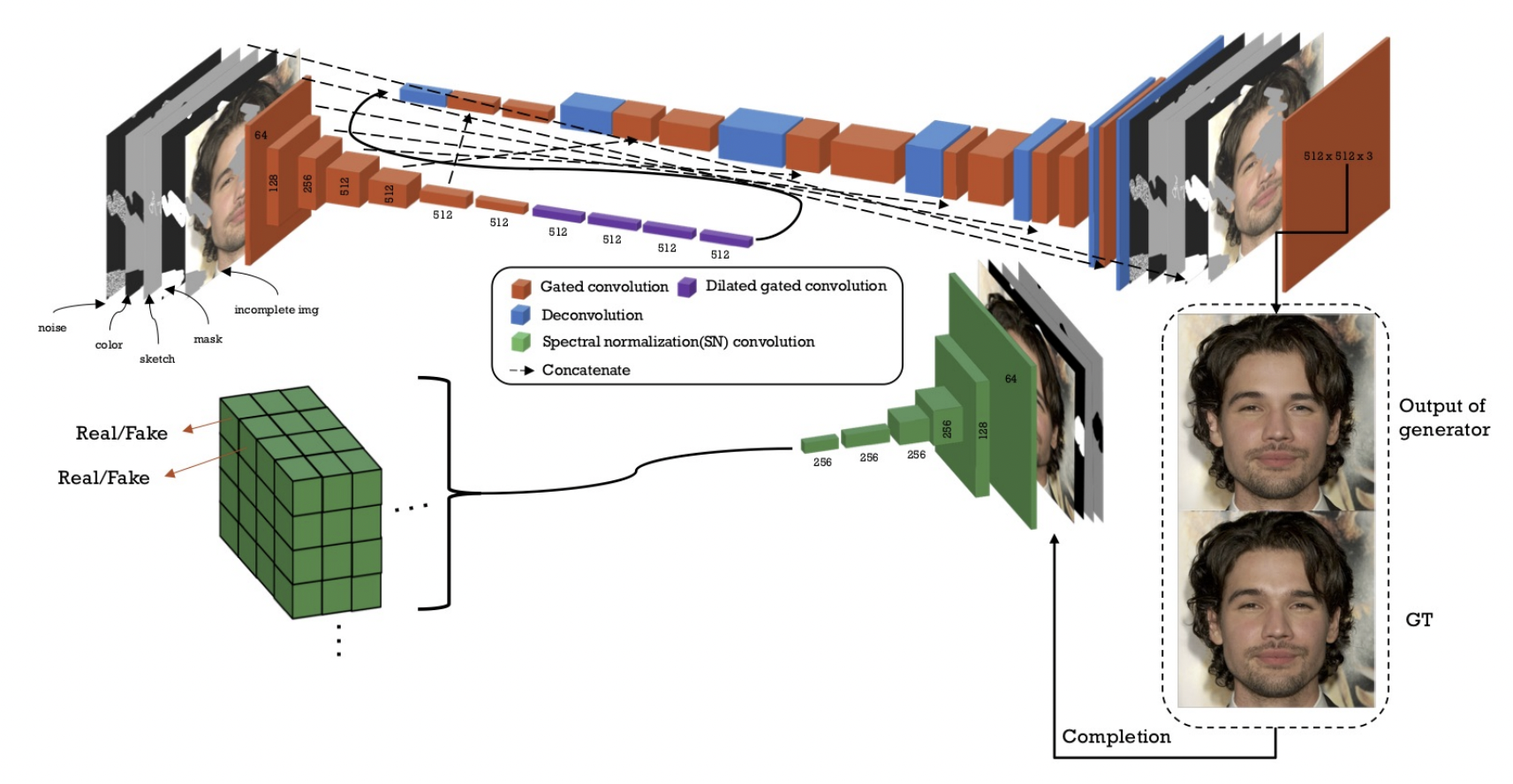
- 생성자는 U-Net 같은 encoder-decoder 구조를 가지며, 판별자는 SN-patchGAN에서 기반하였다.
- Deepfill v2와 달리 GAN loss에 ReLU를 적용하지 않았으며, 3x3 필터를 사용하고 추가적인 loss term을 사용하였다.
Loss function
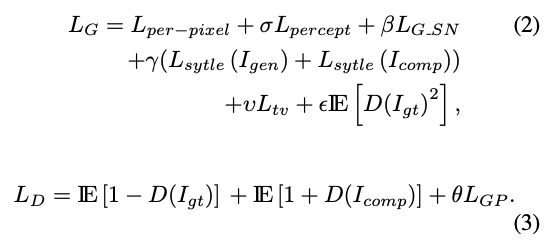
이 논문의 loss function은 굉장히 다양하다. 하나씩 살펴보자.
- : Input 가 판별자를 거쳐 나온 결과
- : Ground Truth 이미지
- : 생성이미지
- : 생성이미지 중 지워지지 않은 영역??잘 모르겠다..
- : binary mask map
- : feature a의 요소의 수
- : VGG-16의 q번째 레이어의 feature map
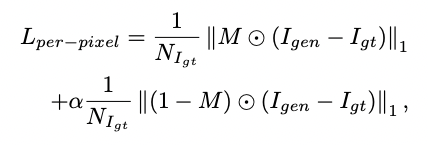
실제 이미지와 생성 이미지의 L1 distance로 >1로 설정하여 지워진 영역에 가중치를 준다.
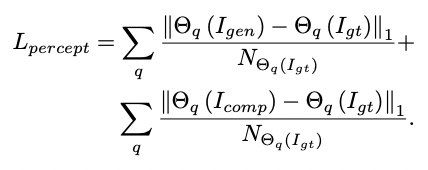
VGG-16의 feature space로 투영했을 때의 L1 distance를 계산한다. q는 VGG-6의 pool1, pool2, pool3를 사용한다.
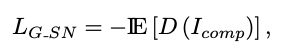
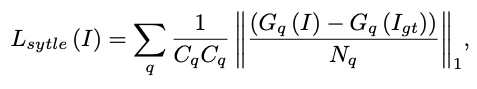
- style이란 각 채널들 사이에 분포하는 활성값들의 상관관계를 의미한다.
- 는 Gram matrix로 feature map의 상관관계를 나타내는 matrix다.
- 즉, 위 식은 생성 이미지와 실제 이미지 간의 스타일의 분포의 차이를 나타낸다.
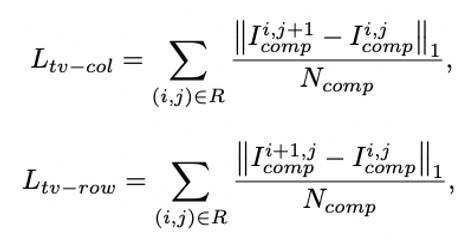
- total variation loss
- perceptual loss에서 나타나는 checkerboard artifacts를 개선한다.
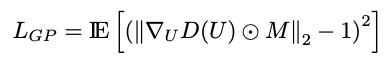
- WGAN-GP의 loss로 성능 향상에 도움이 된다
Results

UNet을 사용한 본 논문과 Coarse-Refined structure를 사용한 Deep-fillv2를 비교한 결과이다.

FaceShop에서 나타났던 문제인 넓은 영역을 복원하려 할 때 제대로 작동하지 않는 현상을 perceptual loss와 style loss로 해결한 모습
