
Introduction
- 본 논문에서는 semantic segmentation mask를 사진처럼 변환해주는 조건부 이미지 합성 방식을 제안한다.
- 기존에도 이와 같은 연구는 있었으나 semantic mask에 대해 wash away 현상이 나타난다는 문제점이 있었다.
- 따라서, spatially-adaptive normalization 기법을 활용하여 semantic 정보에서도 최적의 결과를 보일 수 있는 네트워크를 보인다.
- semantic과 style을 모두 control 할 수 있다.
Normalization
Unconditional Normalization
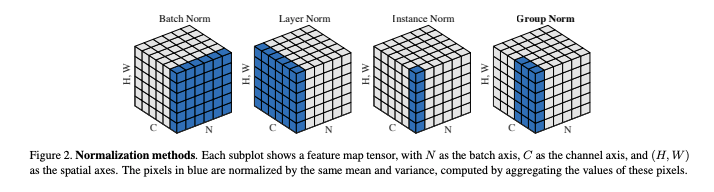
Normalization의 형태는 로 동일하나 평균과 표준 편차를 구하는 방식에 따라 구분이 된다.
Batch normalization
에 대해서만 연산을 하여 배치별 normalization을 한다.
Layer normalization
배치와 무관하게 에 대해 연산하여 채널별 normalization을 한다.
Instance normalization
에 해당하는 부분으로 배치, 채널과 무관하게 각 데이터에 대해 normalization을 한다.
Group Normalization
채널을 그룹으로 묶어 normalization을 한다. 모든 채널을 한 그룹으로 묶이면 layer normalization과 동일하며, 하나의 채널을 한 그룹으로 보면 instance normalization과 동일하다.
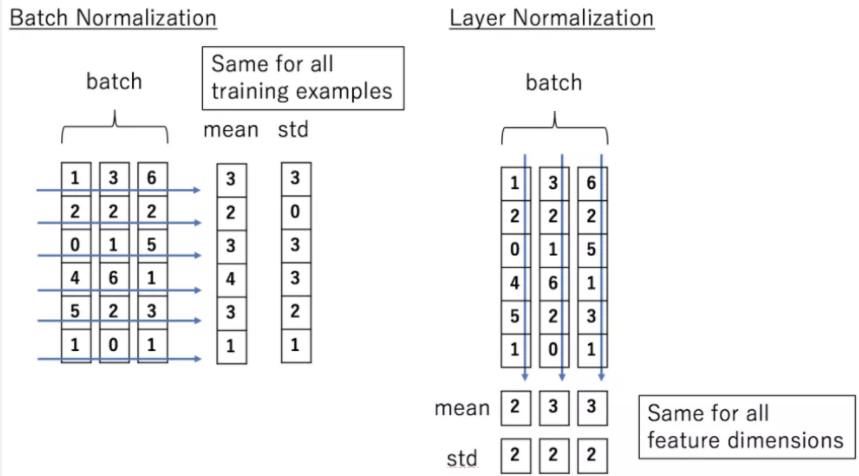
Conditional Normalization
- Normalization을 한 후 벡터 형태로 담겨있는 조건 변수를 곱하고(scaling) 더해준다(bias).
- AdaIN에서는 위와 같은 과정을 채널별로 수행한다.
SPADE(Spatially-Adaptive Denormalization)
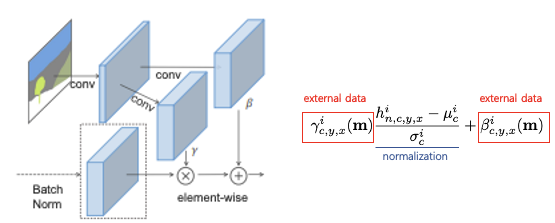
- 조건으로 주는 를 본 논문에서는 external data라고 칭하며 segmentation map으로부터 뽑는다.
- 벡터 형태였던 기존 conditional normalization과 달리 convolution layer를 거쳐 텐서 형태로 나타나 각 픽셀별로 적용될 수 있다.
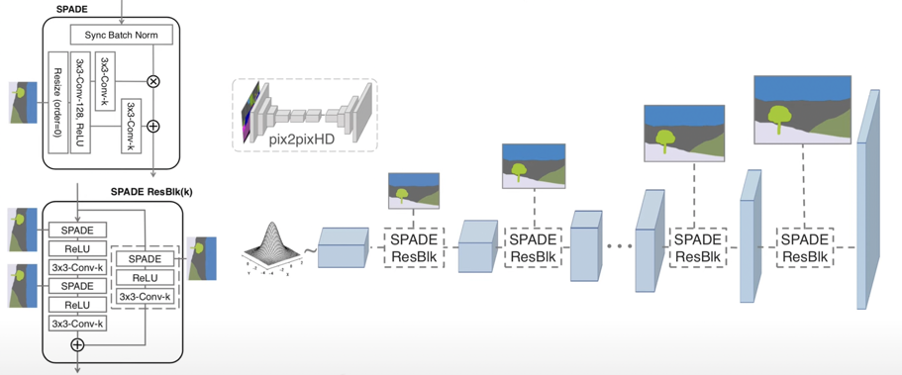
- SPADE는 residual block 형태로 구성된다.
- Learned modulation parameter()에 충분한 정보가 인코딩 되어있으므로 첫번째 레이어에서 segmentation map을 input으로 받을 필요가 없으며 encoder 구조가 생략된다.
- Input으로 랜덤 벡터를 받아 multi-modal synthesis가 가능해졌다.
- Loss function은 pix2pixHD와 동일하며, least squared loss가 hinge loss로만 바뀌었다.

- 기존의 conditional image synthesis model들은 균일한 값을 가진 segmentation mask가 input으로 들어올 때 그 정보들을 날려버리는 wash away 현상을 보였다.
- 이는 single label segmentation mask가 convolution layer, normalization, activation function을 거칠 때 그 값이 0이 되기 때문이다.
- SPADE의 경우 normarlize 된 input이 들어와 segmentation mask는 활성화 함수만 거치기 때문에 wash away 문제가 발생하지 않는다.
Multi-modal synthesis
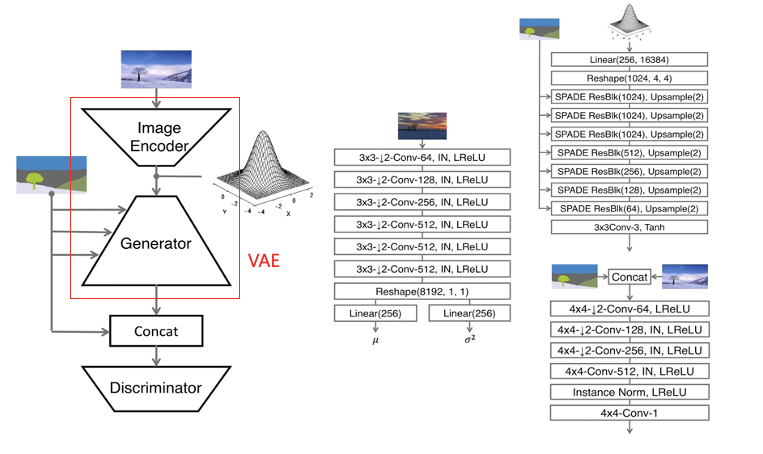
- 이미지로부터 평균과 분산을 뽑는 인코더를 만들면 이로부터 확률분포를 만들어 input값으로 활용할 수 있으므로 이미지에 따라 스타일에 변화를 줄 수 있다.
- 이 과정에서 VAE 구조를 가지기 때문에 KL-Divergence Loss를 추가하였다.
- Generator의 결과는 실제 이미지와 concatenation을 수행한 후 Discrimnator로 전달된다.

