Background
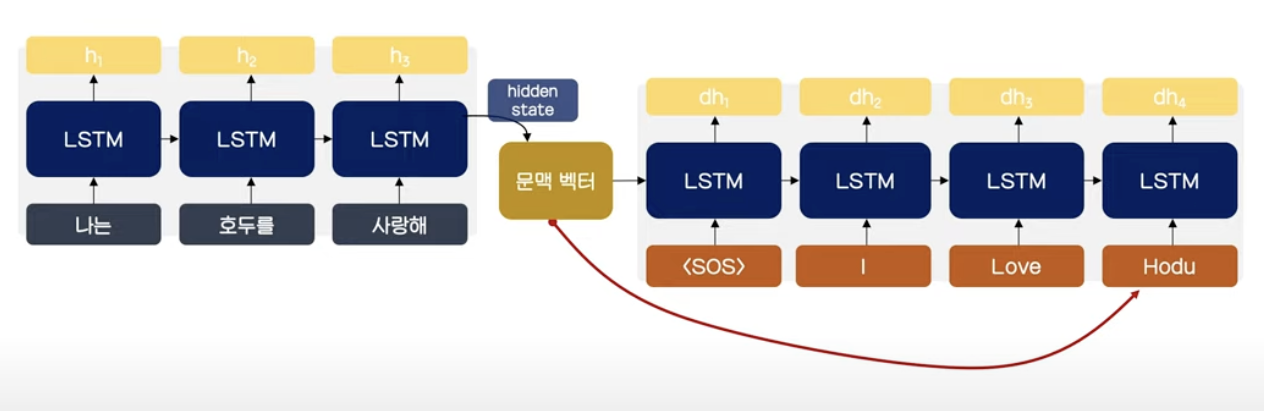
- Seq2Seq 모델들은 Encoder의 정보들을 벡터화하여 손실되는 문제가 있어 Decoding 시 개별 토큰과의 관계 파악이 어려움
- 또한, Sequence가 길어지는 경우 Gradient vanishing 문제 발생
- 문제 해결을 위해 Attention value 도입
- 인코더의 hidden state를 전부 보존하여 Decoder에서 다음 토큰을 예측하는데 사용
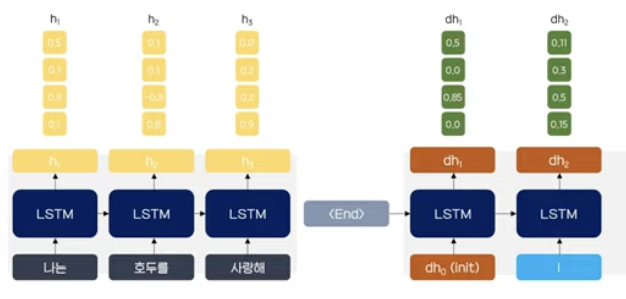
여러 종류의 어텐션이 있는데 가장 수식적으로 쉬운 닷-프로덕트 어텐션(Dot-Product Attention)을 살펴보면 다음과 같다.
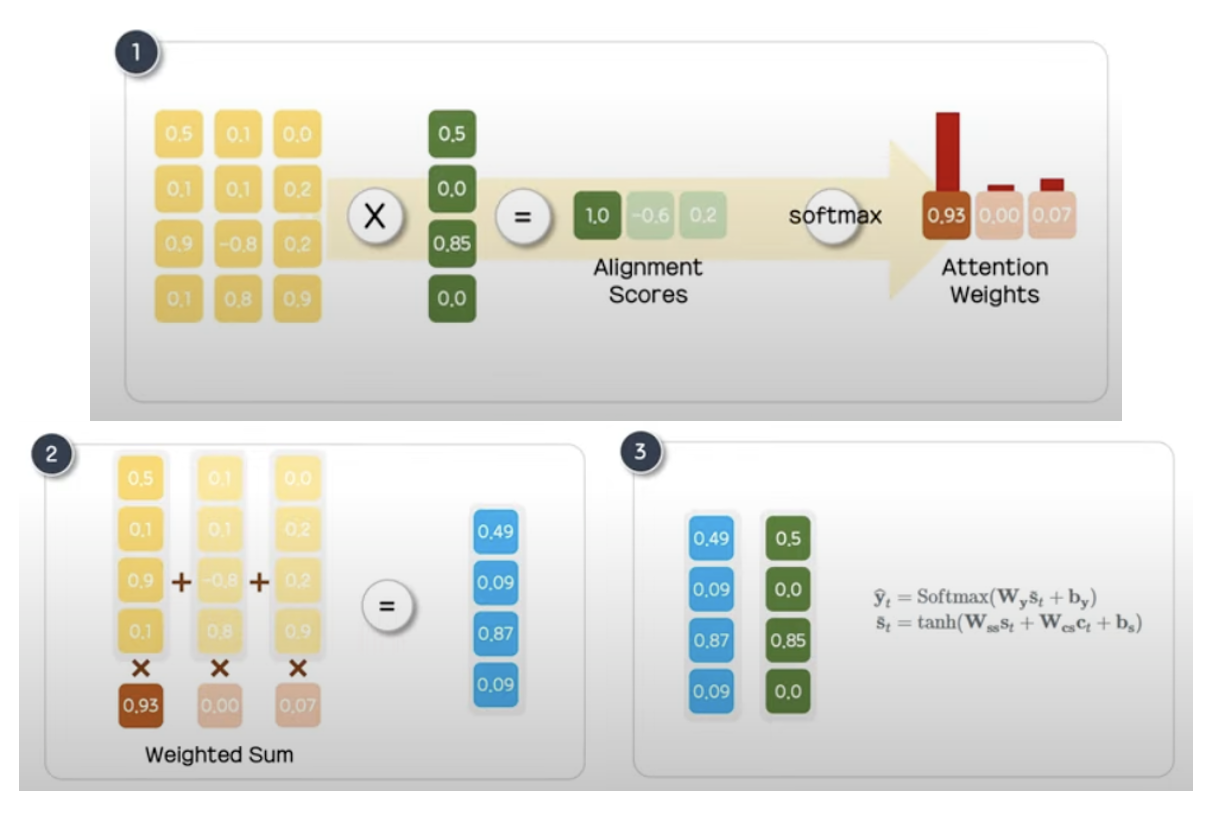
- 현재 예측하려는 t시점 디코더의 은닉 상태와 인코더의 모든 은닉 상태의 유사도를 도출하기 위해 Dot-product를 수행한 뒤 softmax를 통해 확률값(어텐션 분포)을 얻는다.
- 확률값을 가중치로 사용하여 각 은닉 상태에 곱해 어텐션 값을 얻는다.
- 어텐션값과 디코더의 은닉 상태를 결합하여 예측 벡터를 생성한다.
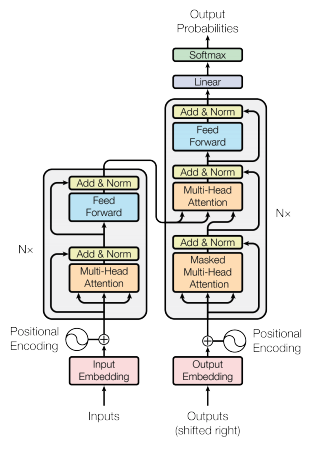
Model Architecture
Input
자연어 그 자체로는 컴퓨터가 알아들을 수 없기 때문에 임베딩(Embedding)이라는 과정을 거쳐 각 단어를 벡터로 표시하게 된다. 이 과정에서 Transformer는 Seq2Seq와 달리 토큰들을 한번에 입력하기 때문에 순서에 대한 정보를 잃는데 Positional encoding을 추가하여 보완한다.
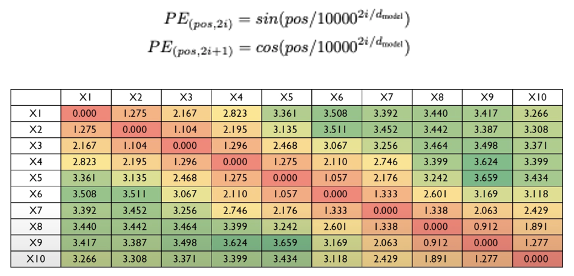
Positional encoding은 sin, cos함수를 이용하며 표에서 볼 수 있듯이 토큰 간의 거리가 멀수록 값이 커지는 경향성을 보인다.
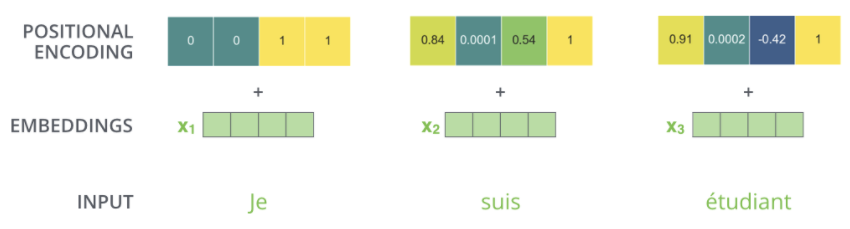
Positional encoding의 차원과 Embedding의 차원이 동일하여 합할 수 있어야 하며 본 논문에서는 512차원으로 설정하였다.
Encoder
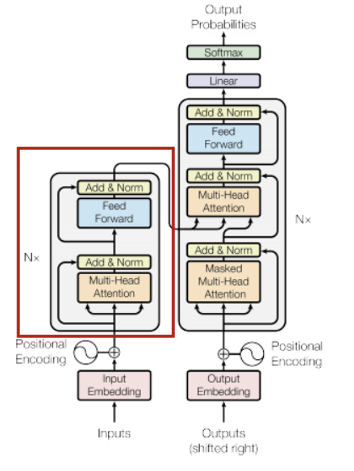
Encoder는 6개의 layer로 구성되며 각 layer는 2개의 sub-layer를 가진다.
- Multi Head Self-Attention
- Feed-Foward Neural Network
Multi Head Self-Attention
Attention에는 Query, Key, Value라는 개념이 등장하는데 파이썬 딕셔너리와 유사하다. 검색하고자 하는 Query와 같은 Key를 찾아 그에 해당 하는 실제 값인 Value를 얻고자 한다.

다만 파이썬의 딕셔너리는 Query와 Key가 완벽히 일치해야 한다면 Attention에서는 주어진 Query에 대해서 모든 Key와의 유사도를 구해 유사도가 가장 높은 것의 Value를 찾게된다. Transformer에서는 각 단어 토큰들의 벡터로 유사도를 계산한다.
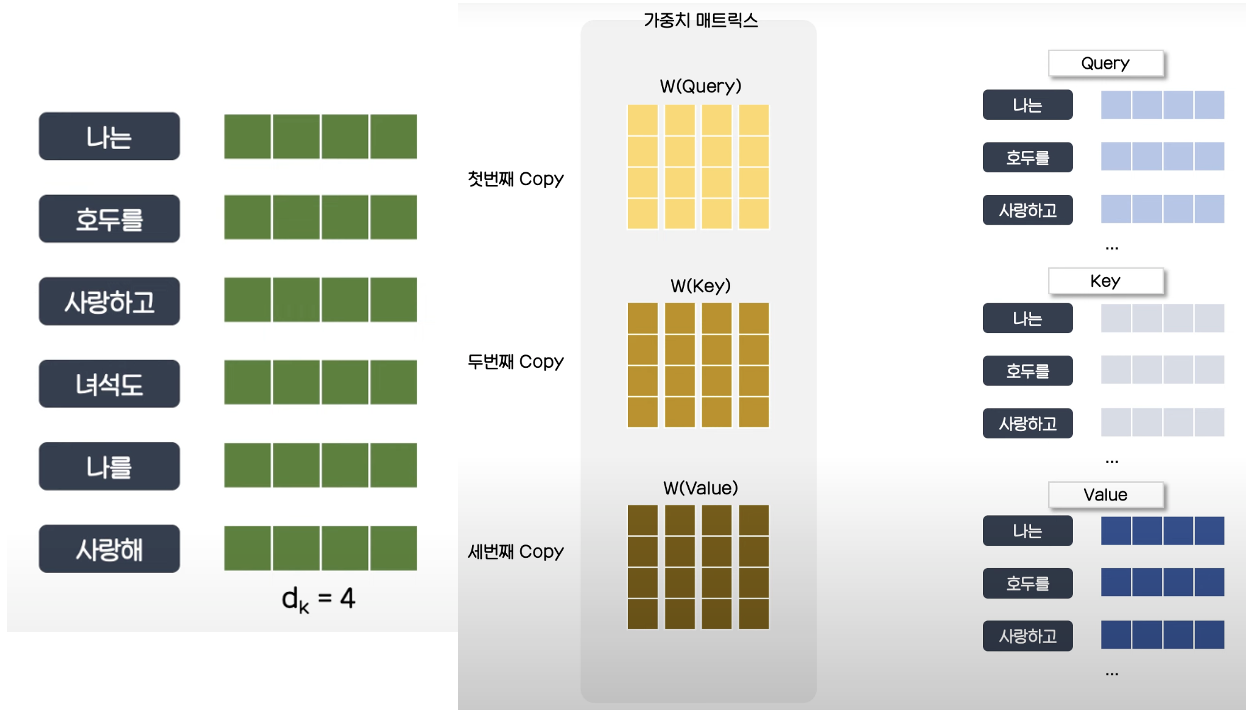
Query, Key, Value는 각각 다른 가중치 매트릭스를 거쳐 새로운 매트릭스가 형성되며 이 때 가중치 매트릭스는 학습에 의해 결정된다.
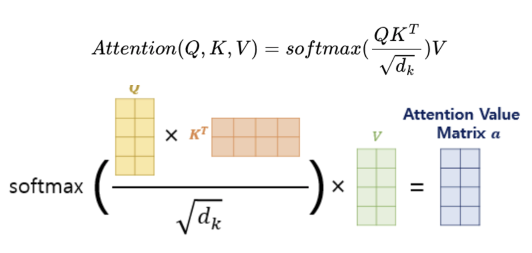
Attention Value는 위와 같은 방식으로 계산된다. 가 클 경우 내적값이 커져 softmax를 통과할 때 1에 근사하면 gradient가 0으로 수렴하여 학습이 매우 느리거나 안될 수가 있다. 따라서, 로 나눠 스케일링을 해준다.
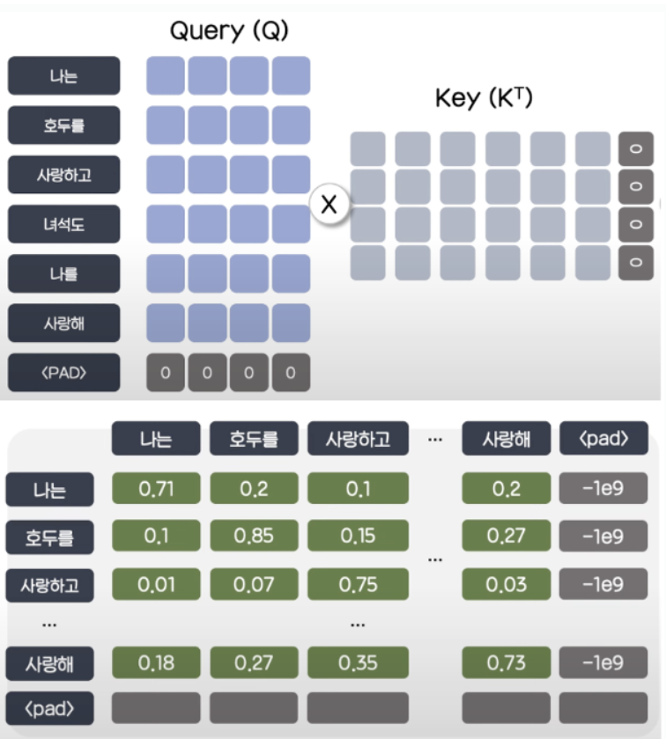
또한, 내적 결과 나온 패딩 부분을 아주 큰 음수로 바꿔주는 마스킹 처리도 들어가게 되는데, 이는 softmax 결과값이 0으로 나오게 하기 위함이다.
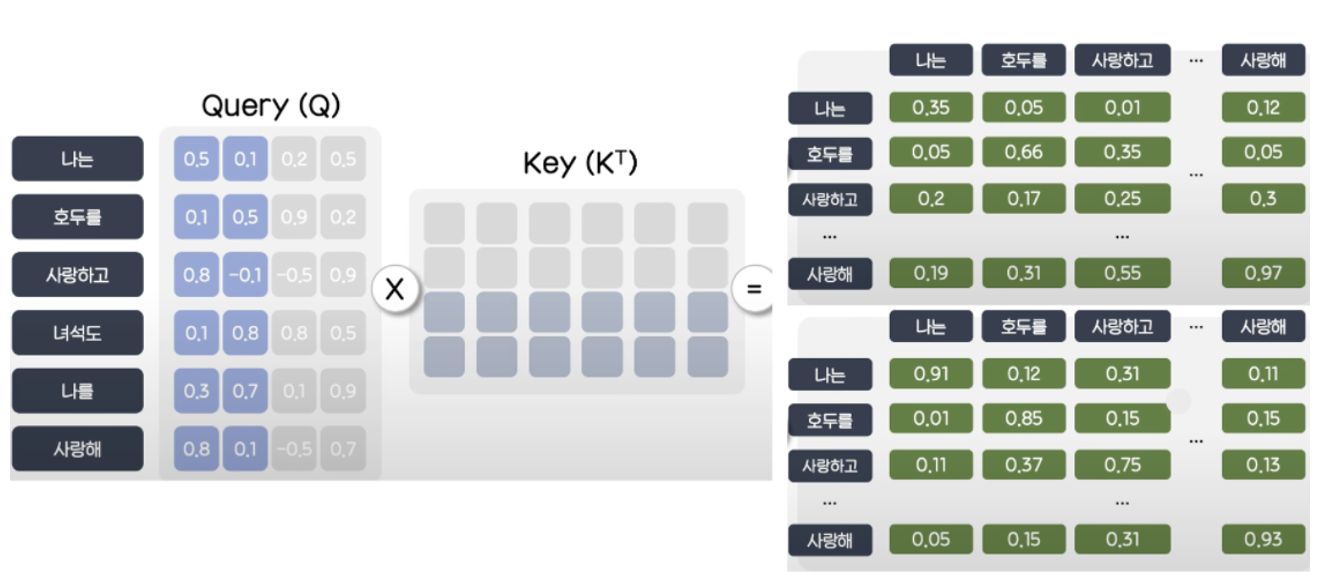
Transformer에서는 Multi Head를 사용하기 때문에 위와 같이 Head의 수만큼 분리해 계산하며 예시에서는 = 4, num_head = 2이지만 논문에서는 = 512, num_head = 8로 제안되었다.
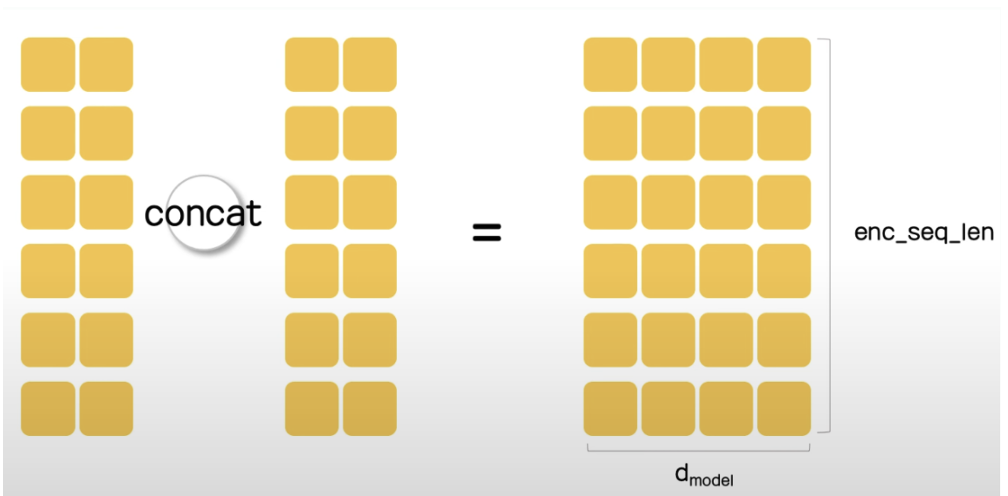
Multi Head를 사용할 경우 내적의 결과와 그에 따른 attention weight가 Head의 수만큼 나오게 되는데 최종적으로는 결합하여 Encoder의 input과 동일한 크기의 텐서를 가지게 된다.
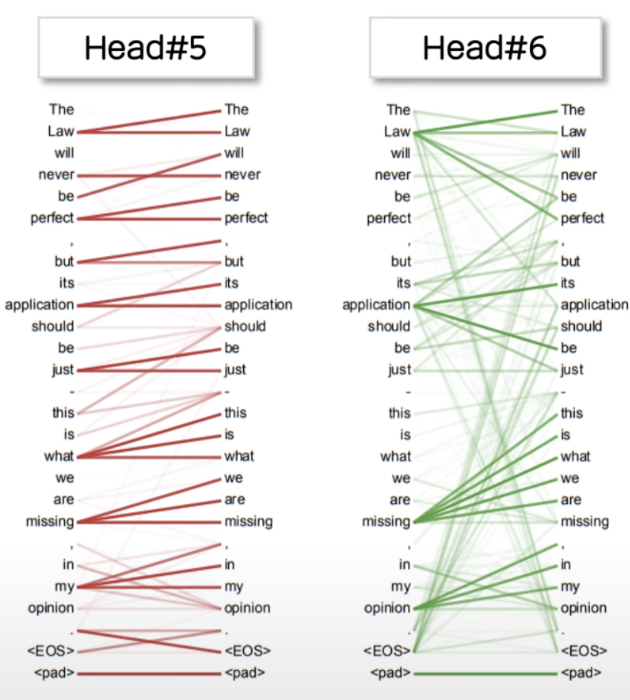
위 그림을 보면 Head#5에서는 짧은 블록들에 대해서 주로 attention을 하는 반명 Head#6에서는 연결된 대명사나 목적어 등을 조금 더 주시하는 모습을 보인다. 이와 같이 Attention head 별로 집중하는 부분이 다르기 때문에 다양한 task를 수행할 수 있다는 점이 Multi Head Attention의 장점이라 할 수 있다.
Feed-Foward Neural Network
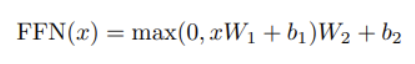
Multi Head Self-Attention의 결과값을 fc layer에 통과시킨다. 2개의 linear layer로 구성되어 있으며 활성화 함수로는 ReLU를 이용한다.
Residual Connection/Layer Normalization
Multi-head Attention과 FFN의 사이, FFN 이후를 보면 Add & Norm이라는 과정이 있다. Add는 sub layer의 Input과 Output을 더해주는 작업을 의미하며 Layer normalization은 Batch Normalization과 같은 일종의 정규화 기법 중 하나이다.
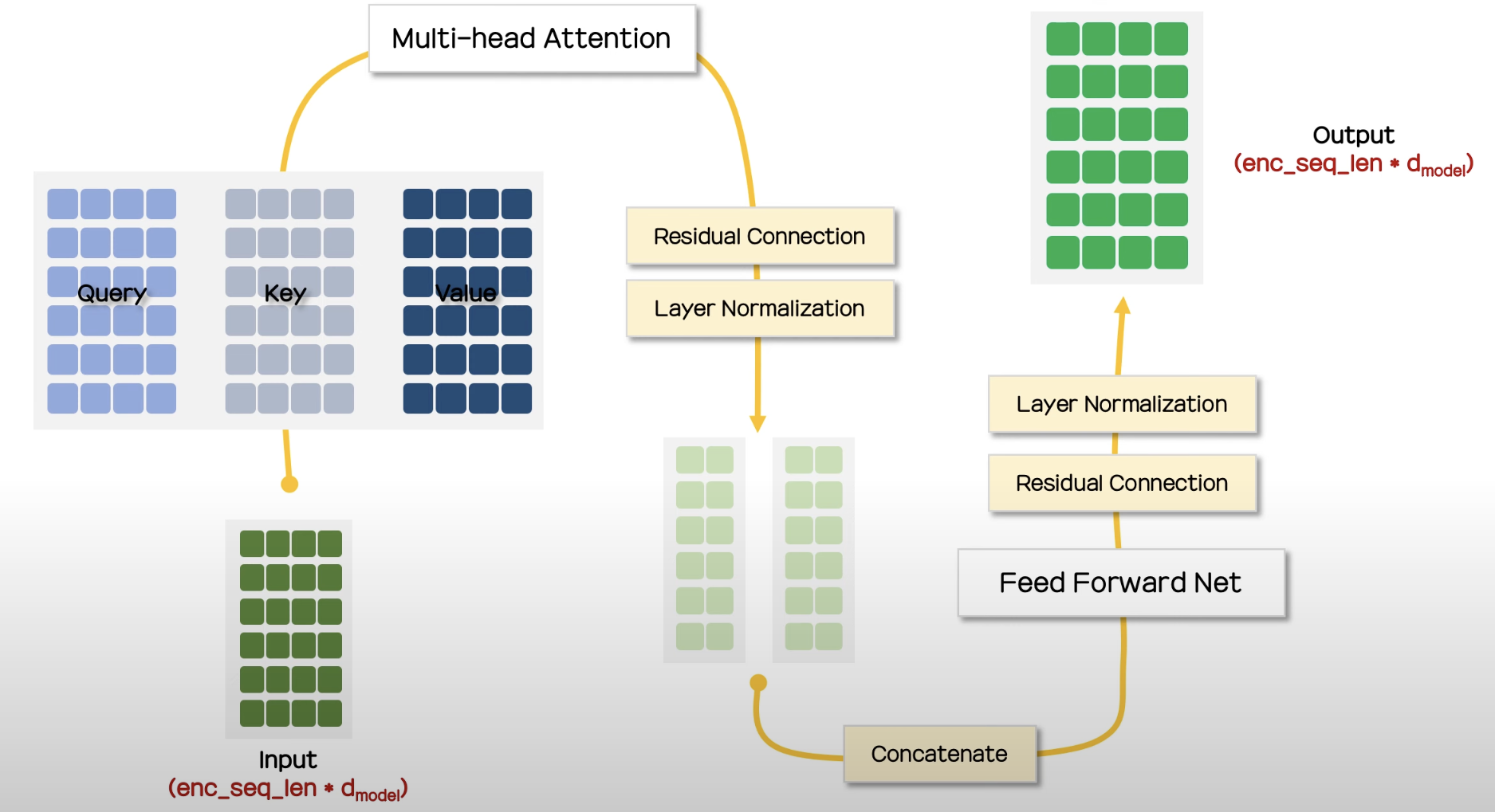
최종적인 Encoder의 구조는 다음과 같다.
Decoder
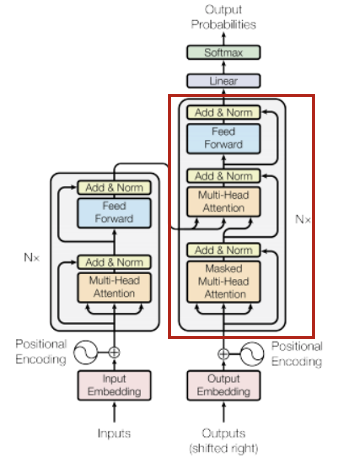
Decoder 또한 6개의 layer를 가지지만 패딩의 Mask 처리와 encoder와 동일한 두 sub-layer 사이에 encoder의 output에 대해 multi-head attention을 수행하는 sub-layer를 추가로 삽입했다는 점이 다르다.
Masking
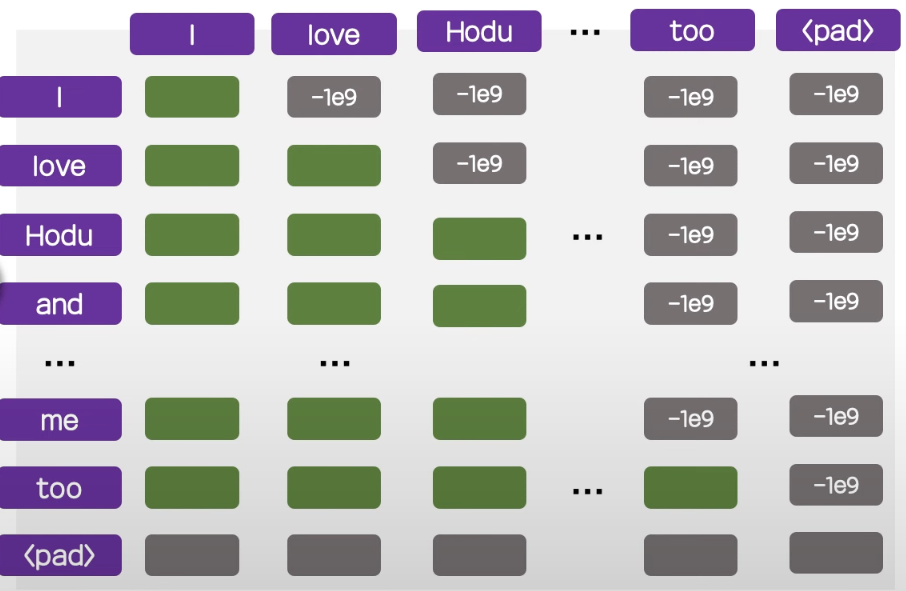
Decoder의 Mask는 뒤의 토큰들을 미리 보는 것을 방지하기 위해 자기 자신과 그 이전 단어들만을 참고할 수 있도록 구성한다.
Encoder-Decoder Attention
Decoder에서는 Self Attention을 수행한 후 또 하나의 attention layer가 존재하는데 이 층의 Query는 decoder의 output을 이용하지만 Key와 Value에는 incoder의 ouuput이 들어간다.
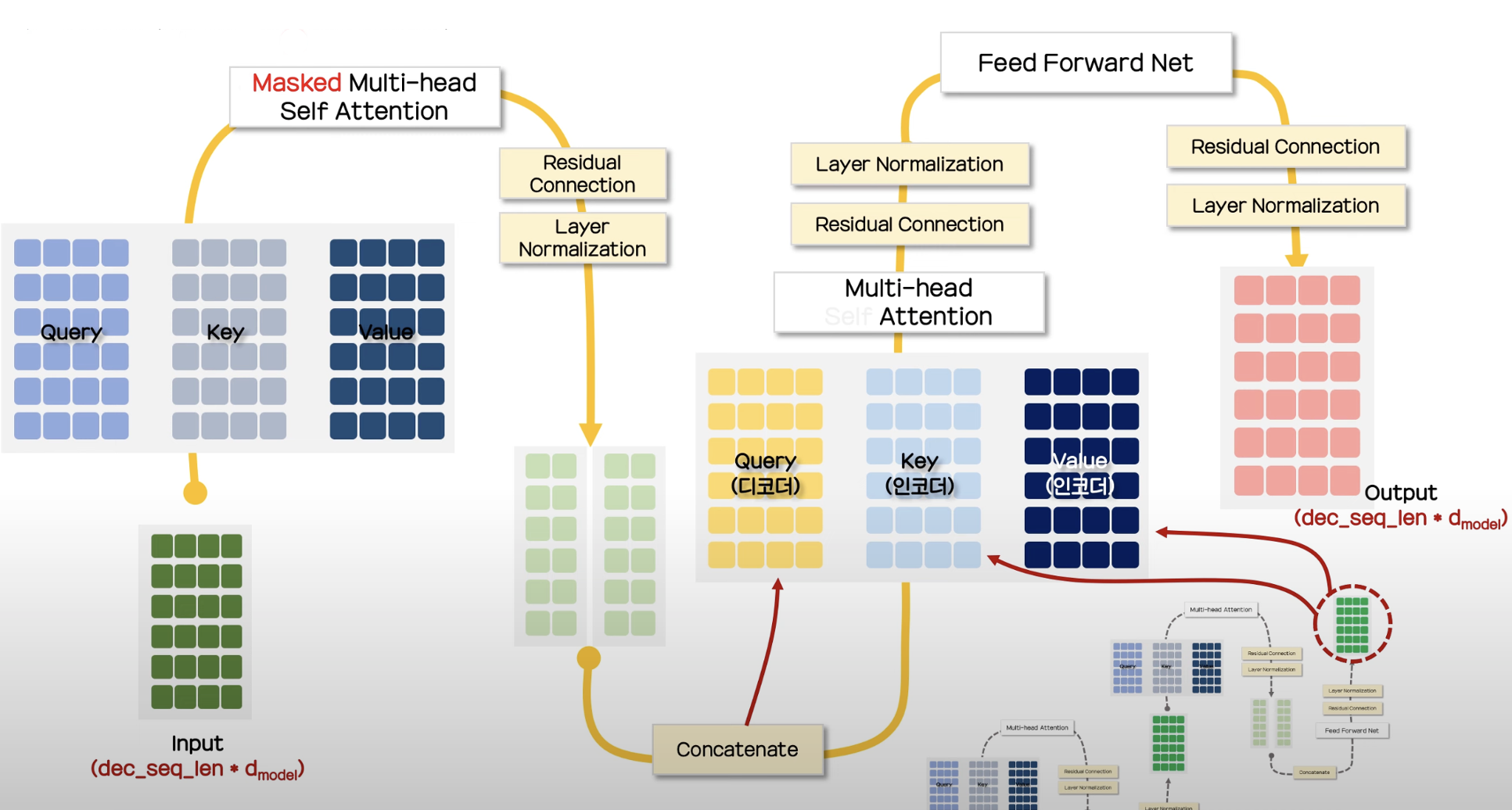
Decoder의 전체적인 구조는 다음과 같다.
Output
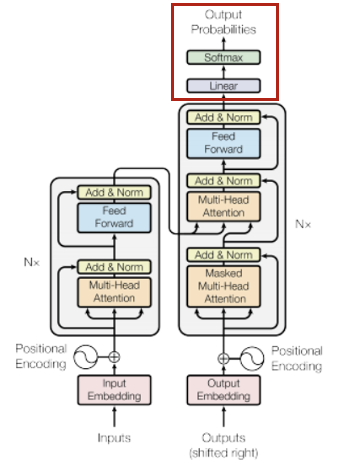
Decoder의 Output은 Linear layer와 Softmax를 거쳐 최종 예측값으로 출력되며 실제 레이블과의 cross entropy를 계산하여 학습을 하게 된다.
