SentiGAN
Introduction
-
기계가 감정이 담긴 텍스트를 이해하고 생성한다는 것은 지능적이며, 사람들에게는 친화적이다. 하지만 감정 텍스트의 분류에는 큰 발전이 있었음에도 불구하고 생성모델에 대한 시도는 그동안 많이 이루어지지 않았다.
-
저자들은 GAN을 활용한 텍스트 생성을 시도하려 했으나 mode collasing과 미분을 할 수 없어 학습이 불가능하다는 문제를 맞이하였고 다중 생성자와 다중클래스 판별자를 가진 SentiGAN을 개발하였다.
SentiGAN의 contribution은 다음과 같다.
- 다양한 유형의 감정을 지닌 고퀄리티 텍스트 생성
- 특정 라벨에서 각각의 생성자가 다양한 텍스트를 생성하게 하는 new penalty based objective
- 다양한 실험을 통해 효율성과 우수성 입증
Framework
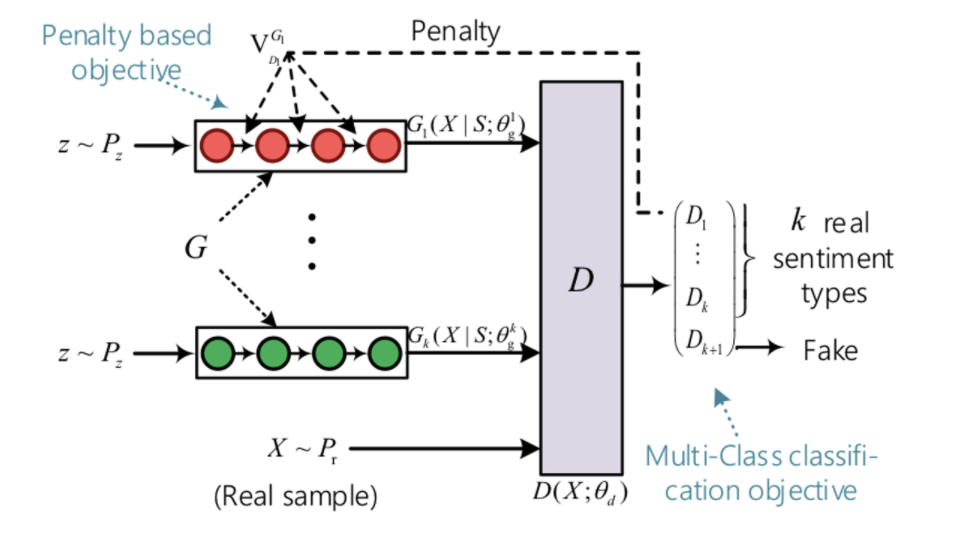
k종류의 감정 텍스트들을 생성한다 가정할 때 SentiGAN은 k개의 생성자와 하나의 판별자로 구성된다. 노이즈 벡터는 정규분포로부터 샘플링되며 GAN과 같이 는 번째 감정 텍스트를 생성하여 판별자를 속이는 방향으로 학습하고 판별자는 가짜와 진짜를 구별할 수 있도록 학습한다.
Generator Learning
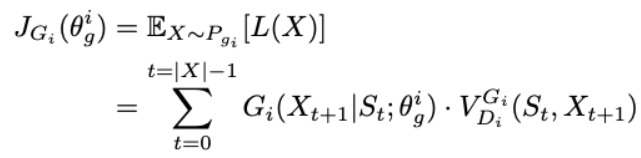
는 를 LSTM을 통해 생성하며 | ;는 (t+1)번째 단어가 선택될 확률을 의미한다. 함수는 판별자에 의해 계산되는 페널티를 의미하므로 생성자는 위 식을 최소화하는 방향으로 학습하게 된다.
판별자는 완전한 문장만을 판단할 수 있게 때문에 생성자는 마지막 ㅣㅣ-t 토큰들은 몬테카를로 탐색을 이용하여 샘플링 하고 penalty function은 다음과 같다.
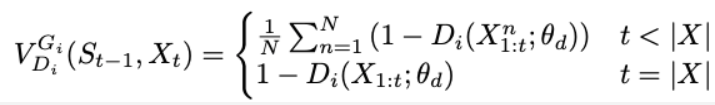
Discriminator Learning
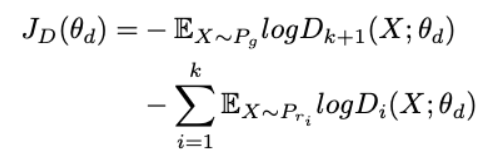
판별자는 k+1개의 클래스에 소프트맥스 확률 분포를 만들어낸다. 일 때 는 번째 텍스트 유형에 속할 확률을 나타내며 (k+1)번째 인덱스는 샘플이 fake일 확률을 나타낸다.
The Multi-Class Classification Objective
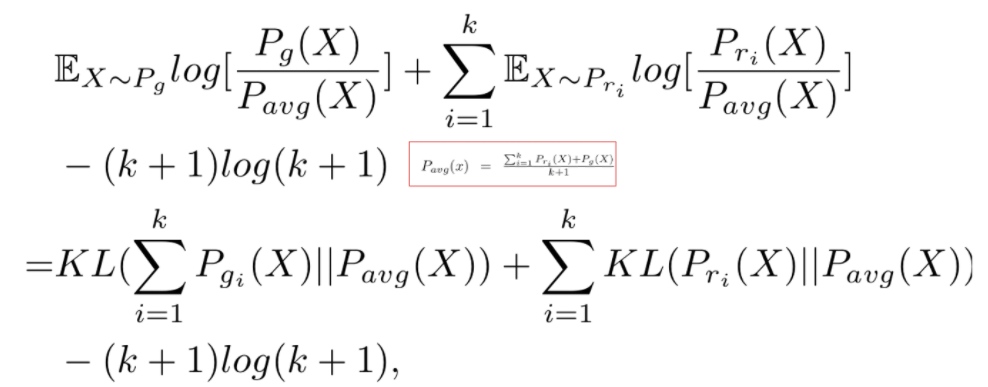
번째 생성자의 최적값은 번째 라벨의 텍스트의 분포를 학습하면서 구해진다. 생성자는 위 식에서 볼 수 있듯이 생성데이터의 분포와 실제 데이터의 분포를(KL) 최소화하는 방향으로 학습하게 되며 이 때 global minimum은 이다.
The Penalty-Based Objective
저자는 SentiGAN의 목적함수가 두가지 측면에서 개선을 보였다고 주장한다.
- SentiGAN의 목적함수는 wasserstein distance 방식이 사용된다. 이는 KL이나 JS와 달리 과 가 겹치지 않을 때도 의미있는 gradient를 제공해준다.
- reward 대신 를 사용한다. ㅣ는 reward-based loss function
ㅣ에 ㅣ가 더해진 것과 같으며 이 때 생성자는 작은
ㅣ 값을 가지는 것을 선호하여 다양한 샘플을 만들게 된다.
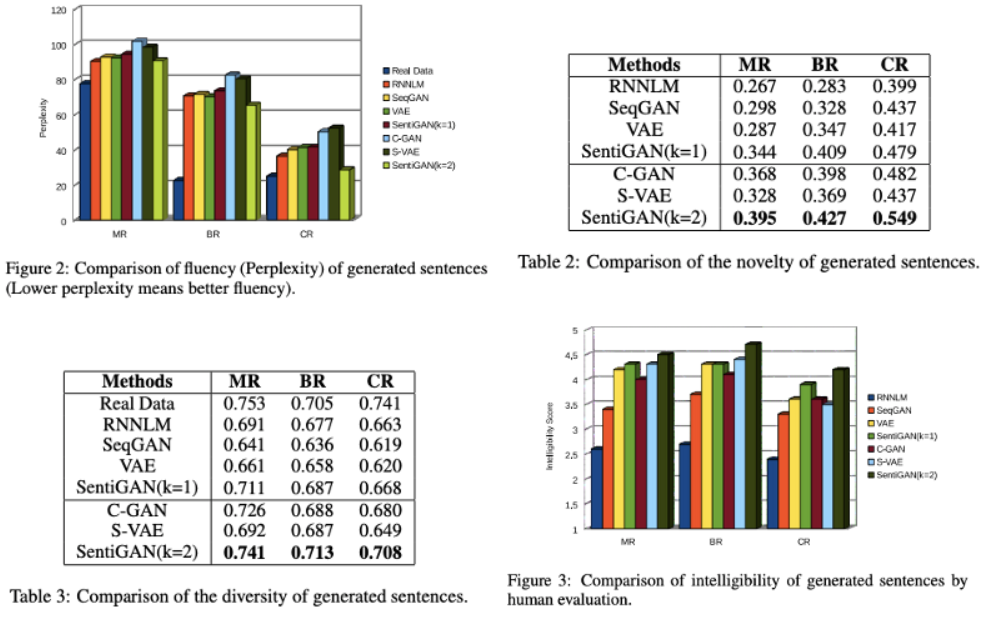
Results
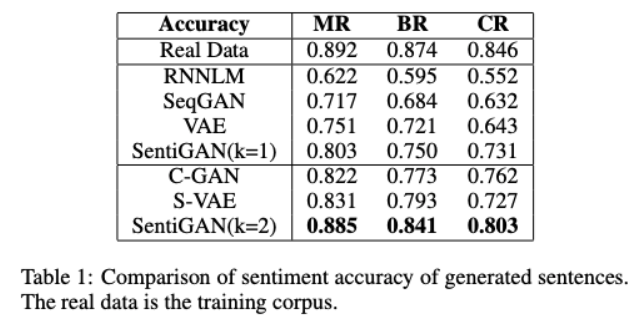
우선 정확도에서 기존의 모든 모델들을 뛰어넘는 성과를 보였다. 이를 통해 Multiple generators와 Multi-class one discriminator가 각 class의 감정 텍스트를 형성하는데 매우 효과적임을 알 수 있었다. 그 외에 Fluency, Novelty, Diversity, Intelligibility에 대해서도 측정하였으며 결과는 아래와 같다