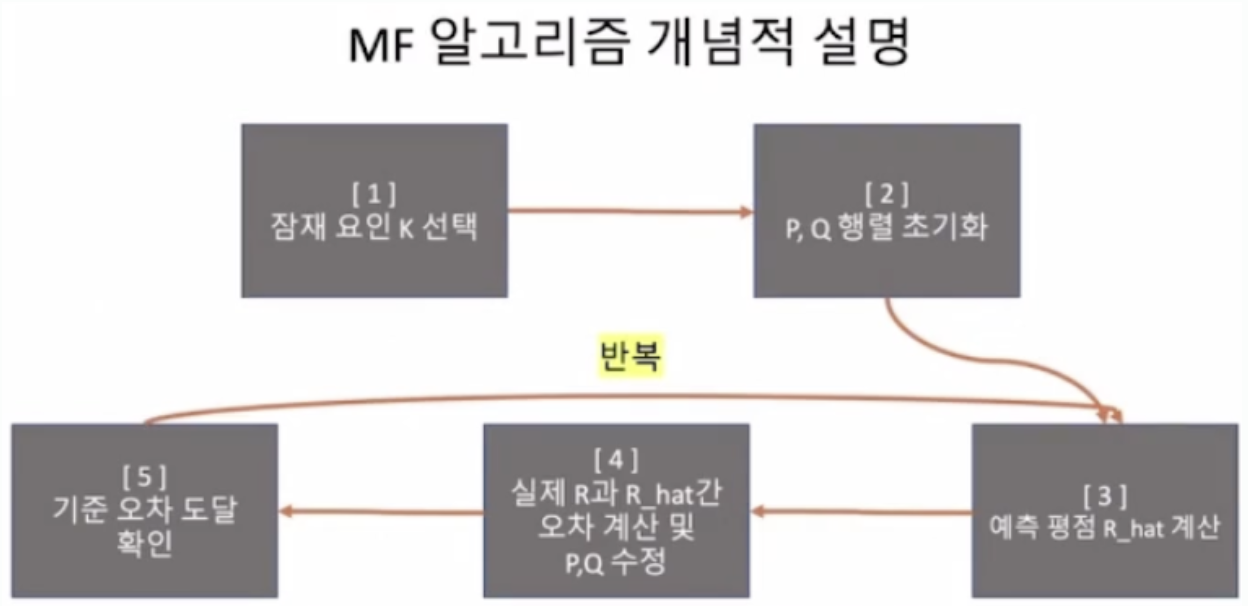
MF 원리 복습
어떤 도메인에 대해서 사용자와 아이템을 잘 설명할 수 있는 k개의 잠재요인이 있고, 각 사용자와 아이템의 P, Q 행렬을 알아낼 수 있다면, 모든 사용자의 모든 아이템에 대한 예측 평점(R hat)을 구할 수 있다.
핵심: 주어진 사용자와 아이템의 관계를 잘 설명하는 행렬로 잘 분해 하는 것.
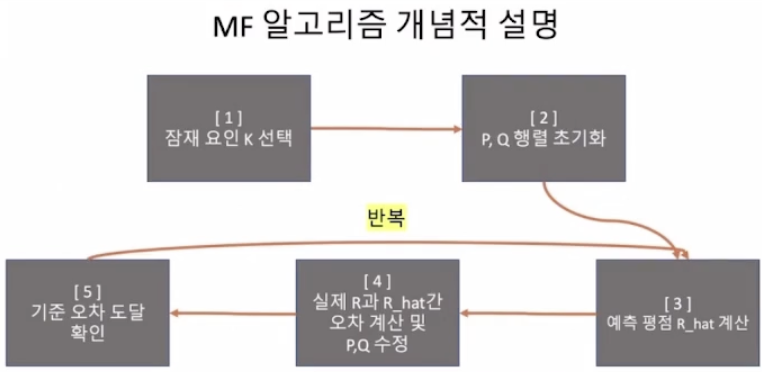
- 최적의 k를 잘 선택해야 한다.
- P, Q 행렬을 만들어 놓고 초기화(틀 만들기)한다.
- 예측 평점 R hat을 구한다.
- 실제 R과 예측 R 오차계산 및 P, Q 행렬 수정한다.
- 전체 오차가 미리 정해놓은 기준값에 도달하거나 기준 iteration 횟수에 도달할 때까지 3번에서 5번 반복.
SGD 수식 표현
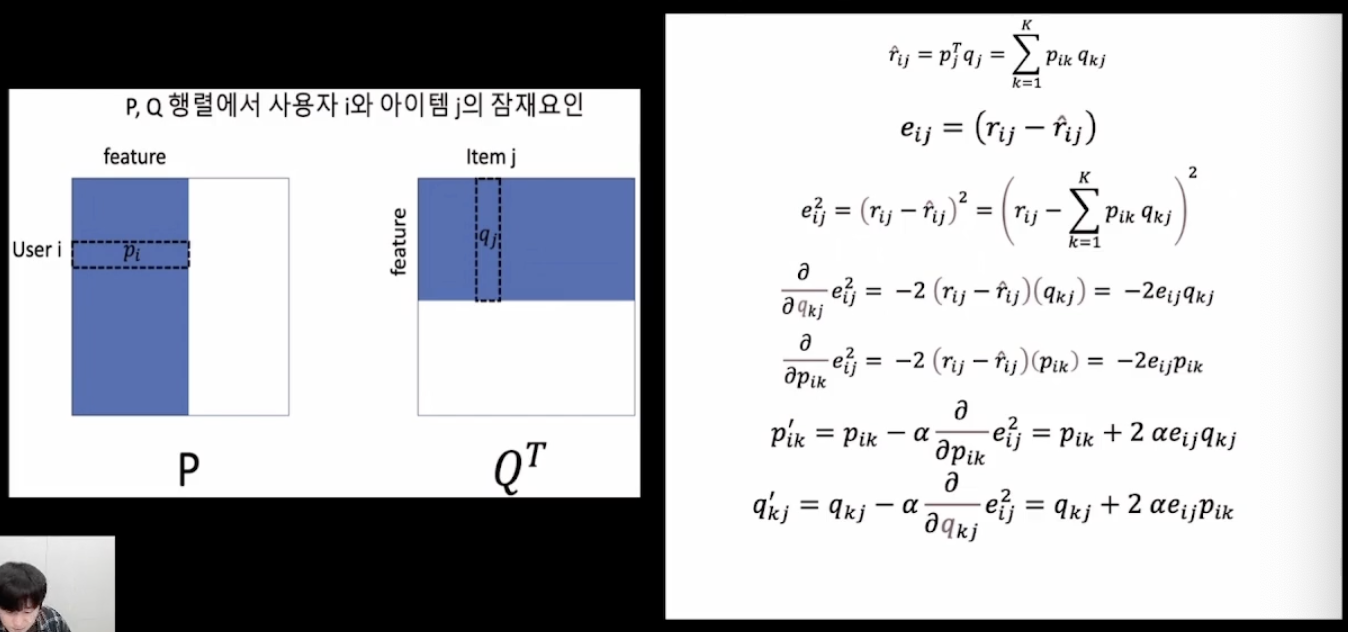
사용자 i의 아이템 j에 대한 예측값 r을 구하고, 실제값 r과 예측값 r hat의 오차를 구해서
오차를 제곱한다.
오차를 제곱하는 이유
- 미분의 편리함
- 오차의 상대적 가중치 - 큰 오차에 대한 페널티가 더 커지게 된다.
- 가우시안 가정 - 오차가 정규분포를 따른다고 가정하면, 제곱 오차를 사용하는 것은 최대 우도 추정(Maximum Likelihood Estimation, MLE) 측면에서 합리적이다.
- MSE의 경우 오차를 제곱한 후 평균을 내기 때문에 음수가 나오지 않아 오차 크기에 대한 정보를 보존할 수 있다.
그 후, 오차를 p와 q에 대해서 편미분을 하면 global minimum을 찾아가게 된다.
편미분한 값을 활용해서 새롭게 p와 q값을 업데이트 한다. (a 알파 = 학습률)
정규화항과 평가경향 고려한 수식
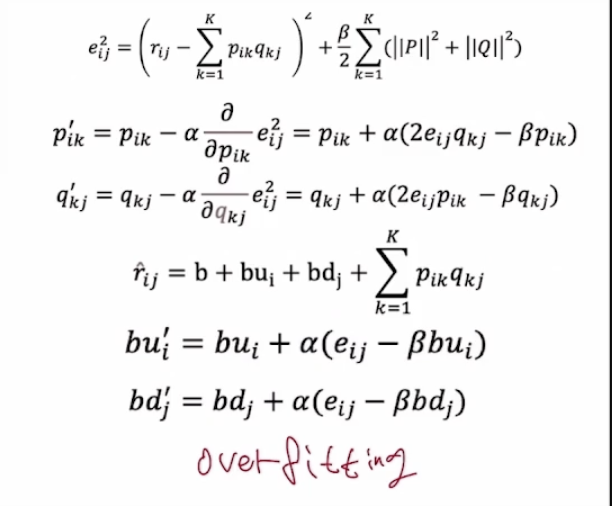
overffiting 과적합을 방지하기 위해 정규화항을 추가한다. (정규화 Regularization)
정규화항이 빠지면 train set이 너무 잘 학습하기 때문에 과적합이 잘 된다.
따라서 정규화항을 추가해주는데, 이는 파라미터의 개수를 많이 늘리면 오차가 더 늘어나도록 페널티를 주는 방식이다. (B 베타 = 정규화 계수)
각 사용자와 각 아이템의 경향성을 제외하고 경향성이 없는 나머지 데이터만을 분석하기 위해 예측값 r 공식에 다음과 같은 3개의 항을 추가한다.
b : 전체 평균 (초기화하는 개념)
bui : 전체 평균을 제거한 후, 사용자 i의 평가 경향 (사용자 i와 전체 평균의 차이)
bdi : 전체 평균을 제거한 후, 아이템 j의 평가 경향 (아이템 j와 전체 평균의 차이)
CF에서는 사용자와 아이템 별로 평가 경향이 한 번에 계산이 되었지만,
MF에서는 계속해서 오차가 수정될 때마다 bui, bdj가 새롭게 업데이트 되어야 한다.
코드
# 데이터 준비
import os
import pandas as pd
import numpy as np
base_src = 'drive/MyDrive/RecoSys/data'
u_data_src = os.path.join(base_src, 'u.data')
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(u_data_src,
sep = '\t',
names = r_cols,
encoding = 'latin-1')
# timestamp 제거
ratings = ratings[['user_id', 'movie_id', 'rating']].astype(int)데이터로는 rating 데이터만 사용한다.
#SGD를 사용한 MF 기본 알고리즘
class MF():
def __init__(self, ratings, hyper_params): #hyper_params 딕셔너리 형태
self.R = np.array(ratings)
self.num_users, self.num_items = np.shape(self.R)
self.K = hyper_params['K'] #잠재요인의 개수
self.alpha = hyper_params['alpha'] #학습률
self.beta = hyper_params['beta'] #정규화 계수
self.iterations = hyper_params['iterations'] #반복횟수
self.verbose = hyper_params['verbose'] #학습과정을 중간중간 출력할 것인지에 대한 정보를 알려주는 플래그 변수
def rmse(self):
#rmse함수 내부에서만 계산하고 쓰이지 않으므로 xs, ys는 지역 변수로 선언
xs, ys = self.R.nonzero() #ratings 테이블에서 0이 아닌 값의 인덱스를 가져온다.
self.predictions = []
self.errors = []
for x, y in zip(xs, ys):
prediction = self.get_prediction(x, y)
self.predictions.append(prediction)
self.errors.append(self.R[x, y] - prediction) #오차
self.predictions = np.array(self.predictions) #예측값과 오차 리스트 넘파이 배열로 변환
self.errors = np.array(self.errors)
return np.sqrt(np.mean(self.errors**2))
def train(self):
self.P = np.random.normal(scale = 1./self.K , #난수값으로 초기화, scale(표준편차)
size = (self.num_users, self.K)) #i x k shape
self.Q = np.random.normal(scale = 1./self.K,
size = (self.num_items, self.K))
#사용자 평가경향과 아이템 평가경향
self.b_u = np.zeros(self.num_users) #zeros 0으로 시작
self.b_d = np.zeros(self.num_items)
#전체 평균
self.b = np.mean(self.R[self.R.nonzero()]) #0이 아닌 값들만 추려서 평균내기
rows, columns = self.R.nonzero()
self.samples = [(i, j, self.R[i, j]) for i, j in zip(rows, columns)]
#SGD가 한 번 실행될때마다 RMSE가 얼마나 개선되는지 기록
training_process = []
for i in range(self.iterations):
np.random.shuffle(self.samples) #매반복마다 다양한 시작점에서 시작?
self.sgd()
rmse = self.rmse()
training_process.append((i+1, rmse))
if self.verbose:
if (i+1) %10 == 0:
print('Iteration : %d ; train RMSE = %.4f' %(i+1, rmse))
return training_process
def get_prediction(self, i, j):
prediction = self.b + self.b_u[i] + self.b_d[j] + self.P[i, :].dot(self.Q[j,].T)
return prediction
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_prediction(i, j)
e = (r - prediction)
self.b_u[i] += self.alpha * (e - (self.beta * self.b_u[i]))
self.b_d[j] += self.alpha * (e - (self.beta * self.b_d[j]))
self.P[i, :] += self.alpha * ((e * self.Q[j, :]) - (self.beta * self.P[i, :]))
self.Q[j, :] += self.alpha * ((e * self.P[i, :]) - (self.beta * self.Q[j, :]))
R_temp = ratings.pivot(index = 'user_id',
columns = 'movie_id',
values = 'rating').fillna(0)
hyper_params = {
'K' : 30,
'alpha' : 0.001,
'beta' : 0.02,
'iterations' : 100,
'verbose' : True
}
mf = MF(R_temp, hyper_params)
train_process = mf.train()
->
Iteration : 10 ; train RMSE = 0.9585
Iteration : 20 ; train RMSE = 0.9373
Iteration : 30 ; train RMSE = 0.9280
Iteration : 40 ; train RMSE = 0.9225
Iteration : 50 ; train RMSE = 0.9184
Iteration : 60 ; train RMSE = 0.9146
Iteration : 70 ; train RMSE = 0.9102
Iteration : 80 ; train RMSE = 0.9042
Iteration : 90 ; train RMSE = 0.8957
Iteration : 100 ; train RMSE = 0.8839train set과 test set으로 나누지 않았기 때문에 좋은 결과가 나오고 있다.
