추천시스템 Recommendation System
1.기본적인 추천 시스템(best-seller 방식)

인기제품 방식 (Best-Seller) > 개별 사용자 정보가 없고, 간단한 추천을 제공해야할 때, 모든 사용자에게 가장 인기 있는 동일한 상품에 대해서 추천을 한다. 사용자 정보가 없을 때 추천해줄 수 있는 방법이다. = 각 제품에 대한 평가의 평균을 구해서 1등
2.사용자 집단별 추천

사용자 집단별 추천 > best-seller 방식은 전체 사용자의 평점평균을 사용하기 때문에 집단간의 평가 경향이 있다고 가정한다면, 예측값에 대해서 노이즈값이 많이 낀다고 볼 수 있다. 따라서ㅋㅋ Gender 기준 추천 기존에는 movie_id로 groupby 했
3.협업필터링 Collaborative Filtering CF
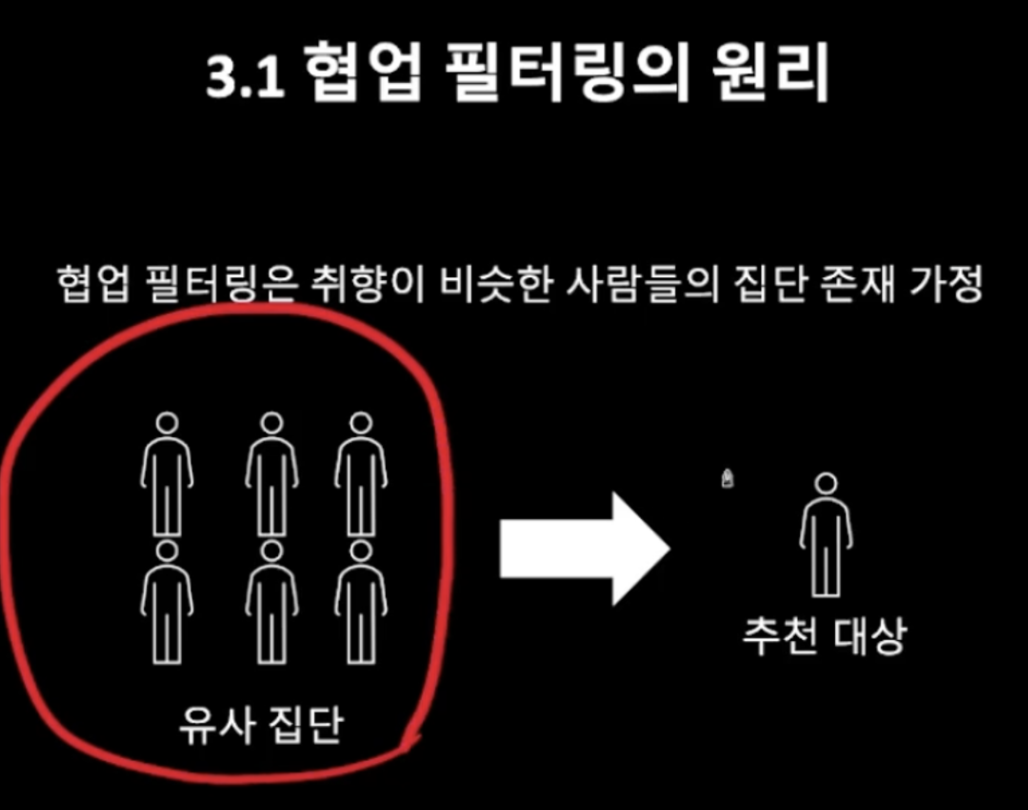
어떤 아이템에 대해 비슷한 취향을 가진 사람들은 다른 아이템 또한 비슷한 취향을 가질 것이다.사용자 집단별 추천과 같이 인구통계학적 변수를 기준으로 나누는 것이 아니라 취향을 고려해서 추천하자!협업 필터링은 취향이 비슷한 사람들이 존재할 것이라고 가정하고,집단을 특정해
4.사용자의 평가 경향을 고려한 CF

최적의 이웃을 구한 후, 보다 더 CF를 개선시키기 위해 사용자의 평가 경향을 고려한 CF 알고리즘을 짜본다.각 사용자의 평점 평균을 구한다.각 평점에서 위에서 구한 각 사용자의 평균을 뺀다.(‘평점’ - ‘평점 평균’ = '평점편차' )평점 편차 임시 예측값 계산 실
5.그 외의 CF 정확도 개선 방법
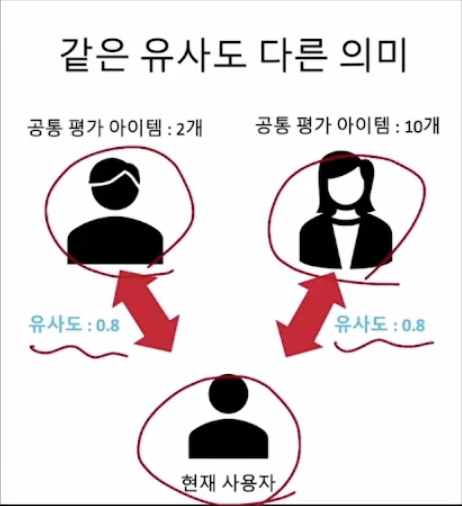
추천 받을 사용자와 유사도가 같은 사용자 2명이 있다고 가정할 때, 각각의 공통 평가 아이템의 개수에 따라서 신뢰도의 차이가 있다. \-> 따라서 사용자 간 유사도를 측정할 때 신뢰도를 가중하자!하지만, 예측값은 매우 민감하기 때문에 약간의 계산식을 바꿔도가 RMSE값
6.사용자 기반 CF와 아이템 기반 CF
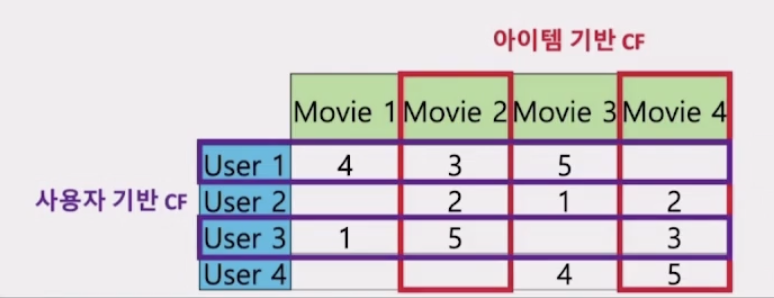
사용자 기반 CF > 사용자 A와 취향이 비슷한 다른 사용자를 찾고, 두 사용자의 차이점을 서로에게 추천한다. 사용자 A와 유사도 측정을 한 후, 유사한 사용자를 찾지 못한다면 추천해줄 수 없는 단점이 있다. 아이템 기반 CF 기준이 되는 아이템을 제외한 다른 아이템
7.추천 시스템의 성과측정지표
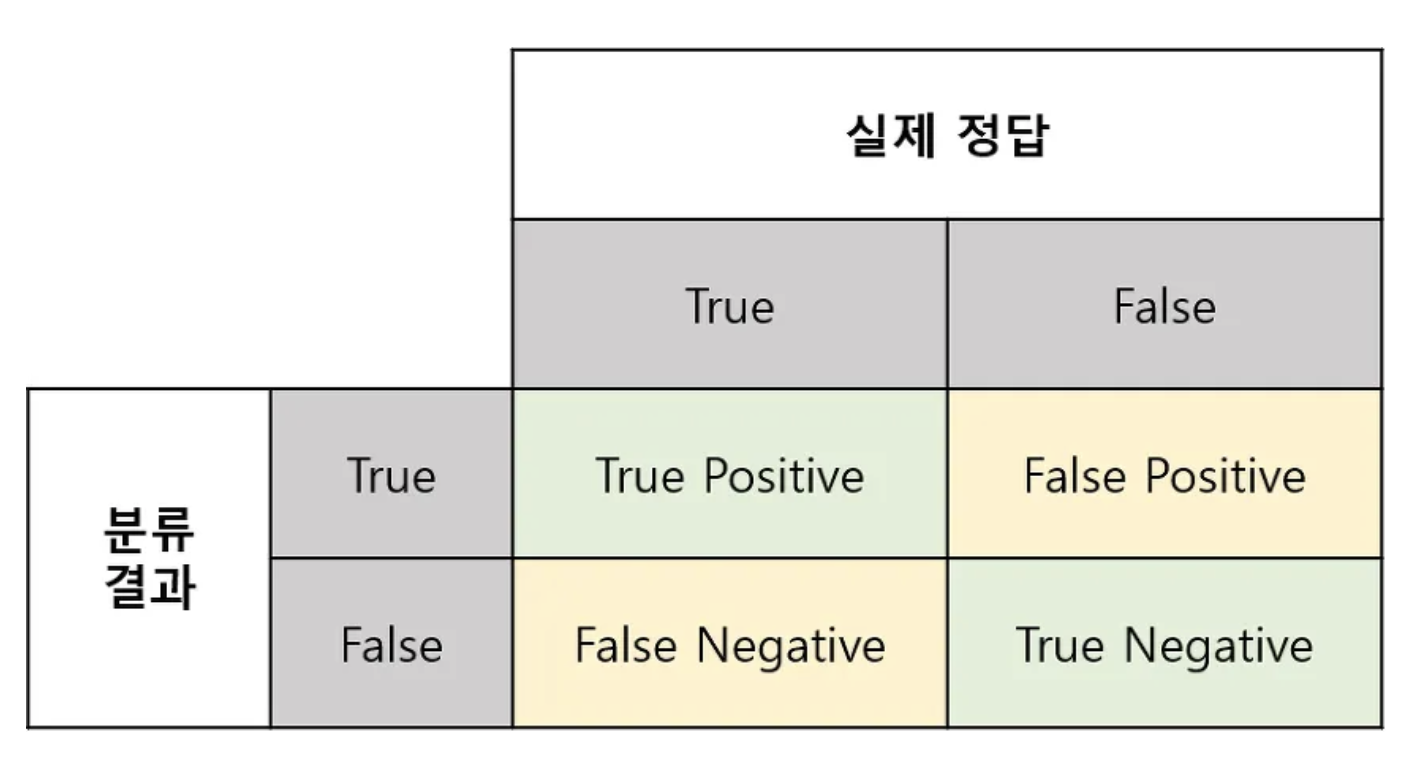
추천 시스템의 성과 측정 지표 > 데이터를 train set과 test set으로 분리 train set을 사용해서 학습하고, test set으로 평가 예상 평점과 실제 평점 차이를 계산 후 정확도 측정 그렇지만, 정확도라는 것이 train set과 test set에
8.MF Matrix Factorization 기반 추천
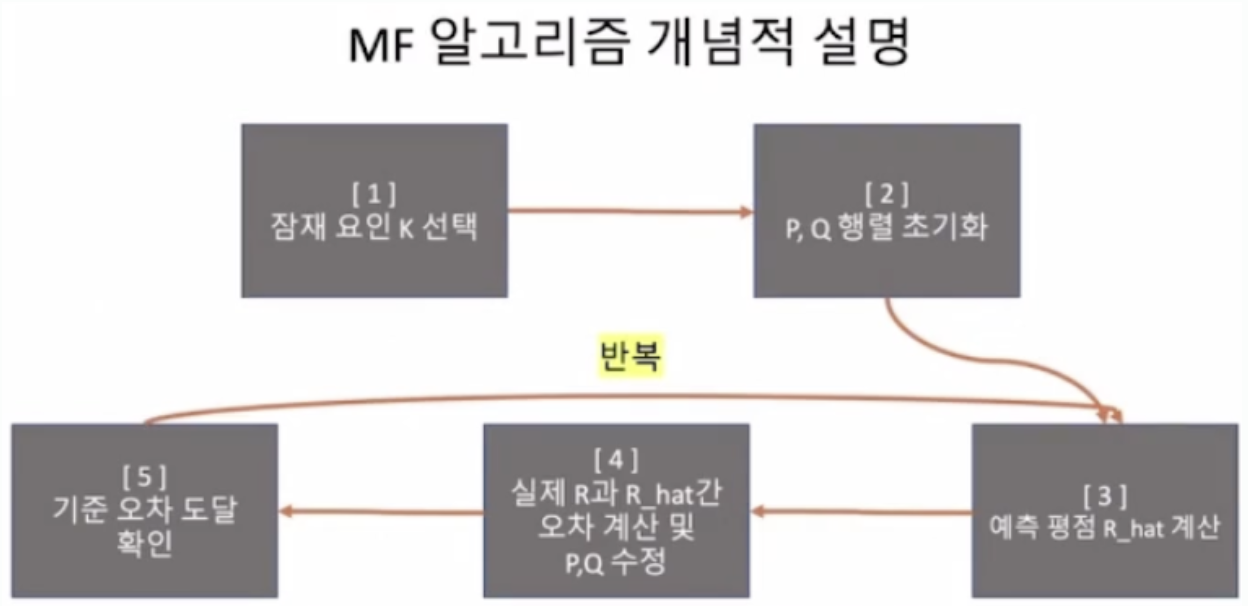
추천을 위한 다양한 알고리즘 종류 메모리 기반 알고리즘 > 추천을 위한 데이터를 모두 메모리에 가지고 있으면서 추천이 필요할 때마다 데이터를 사용하고 계산해서 추천하는 방식 장점: 모든 데이터를 메모리에 저장하고 있기 때문에 원래 데이터에 충실하게 사용한다. 단점:
9.SGD(Stochastic Gradient Descent)를 사용한 MF 알고리즘-1
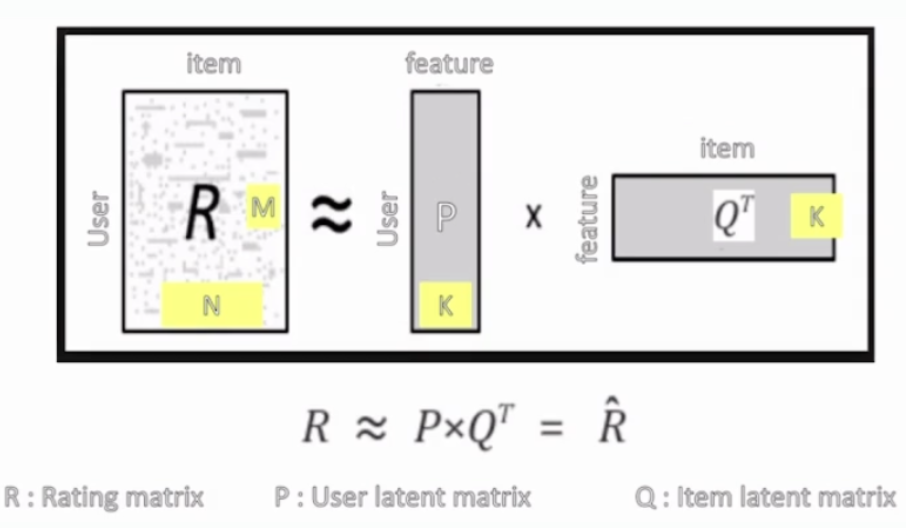
MF 원리 복습 어떤 도메인에 대해서 사용자와 아이템을 잘 설명할 수 있는 k개의 잠재요인이 있고, 각 사용자와 아이템의 P, Q 행렬을 알아낼 수 있다면, 모든 사용자의 모든 아이템에 대한 예측 평점(R hat)을 구할 수 있다. > 핵심: 주어진 사용자와 아이템
10.SGD(Stochastic Gradient Descent)를 사용한 MF 알고리즘-2
이번에는 sklearn의 traintestsplit을 사용하지 않고, shuffle을 사용한다. traintestsplit() > traintestsplit의 경우에는 층화추출법을 사용하여 분리했는데, 이 경우 train set의 정답값이 불균형하게 들어가있어도 비율
11.MF_최적의 파라미터 찾기
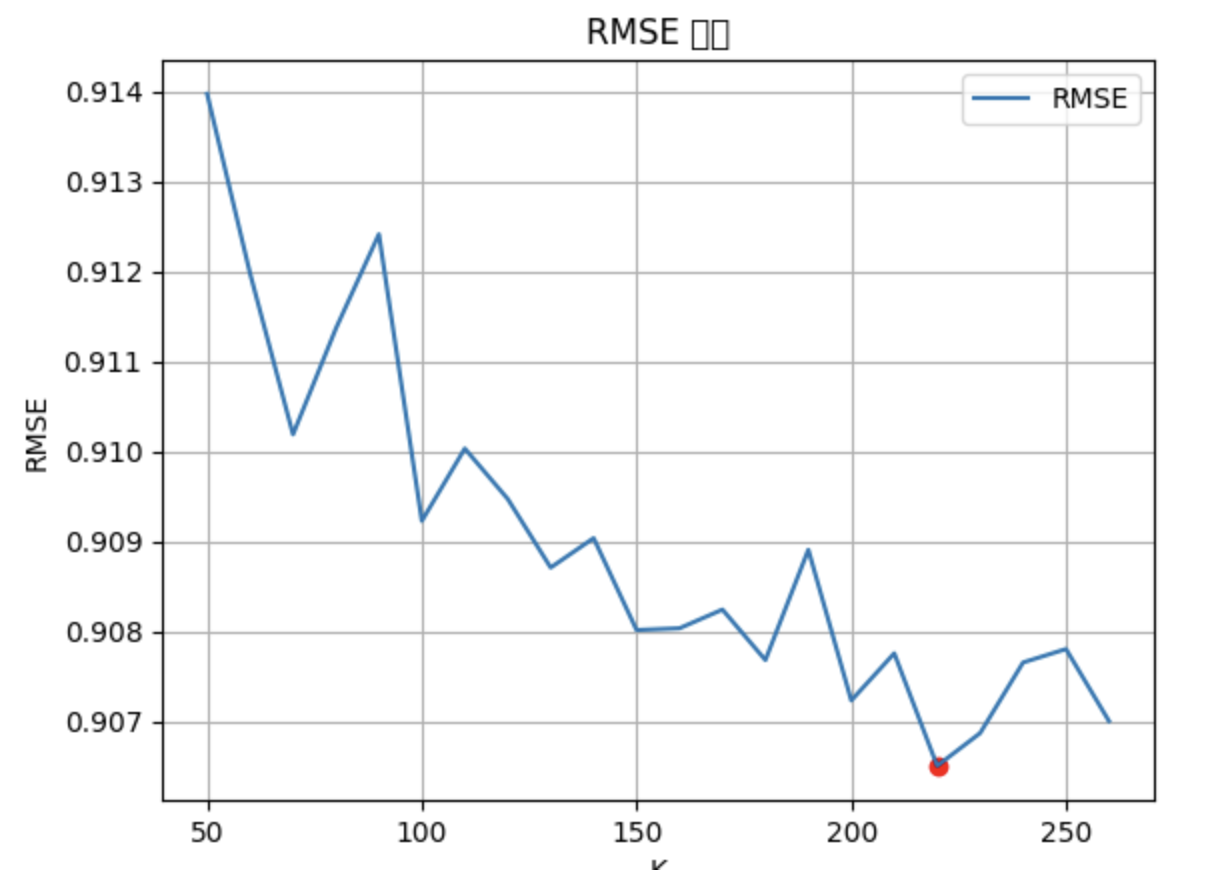
MF 최적의 파라미터 찾기 최적의 k와 iteration 값을 찾아 과적합을 방지한다. > 10씩 k값을 조정해나가면서 RMSE값을 계산해 대략적인 최적의 k값을 찾은 후, 대략적인 최적의 k값에서 전후로 1씩 조정해나가며 최적의 k값을 찾는다. 최적의 k값을 고정
12.MF와 SVD
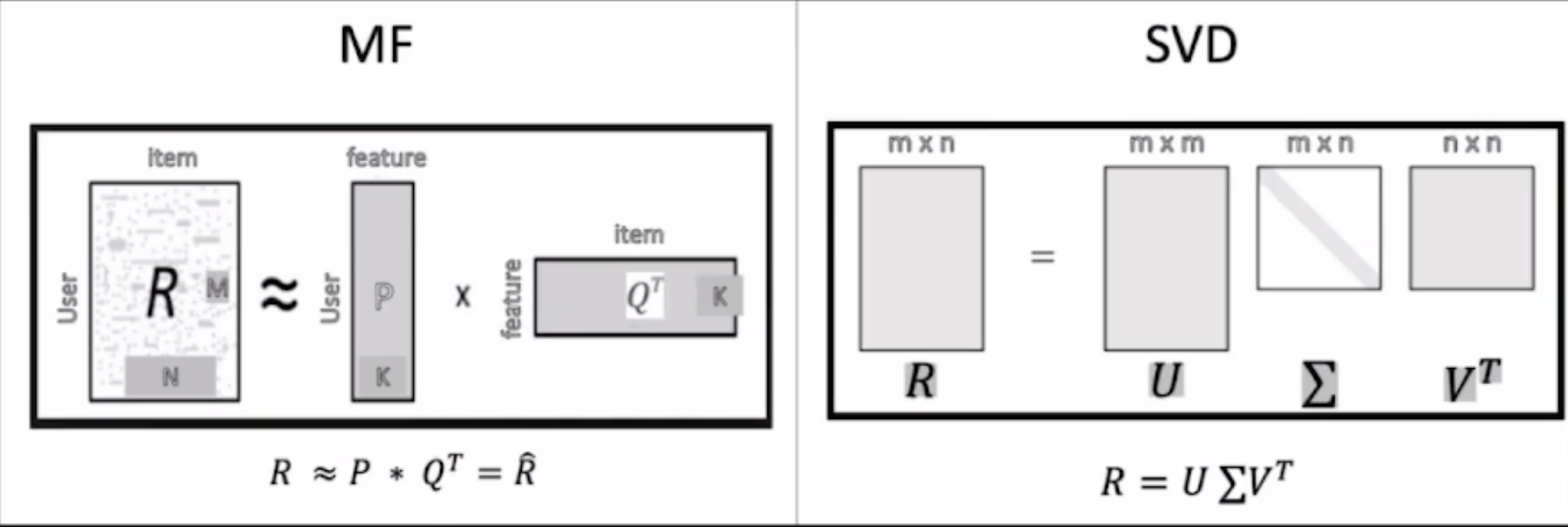
데이터 분석과 기계학습에서 많이 사용되는 MF와 SVD 개념을 헷갈려하는 사람들이 많다고 한다. 그렇지만 명백히 다른 기법이라고 한다.반면, MF의 경우 2개의 행렬로 분해하고, k개의 잠재요인을 사용해서 표현된다.null값을 0의 값으로 표현했고, P 행렬과 Q 행렬
13.Surprise 패키지 사용
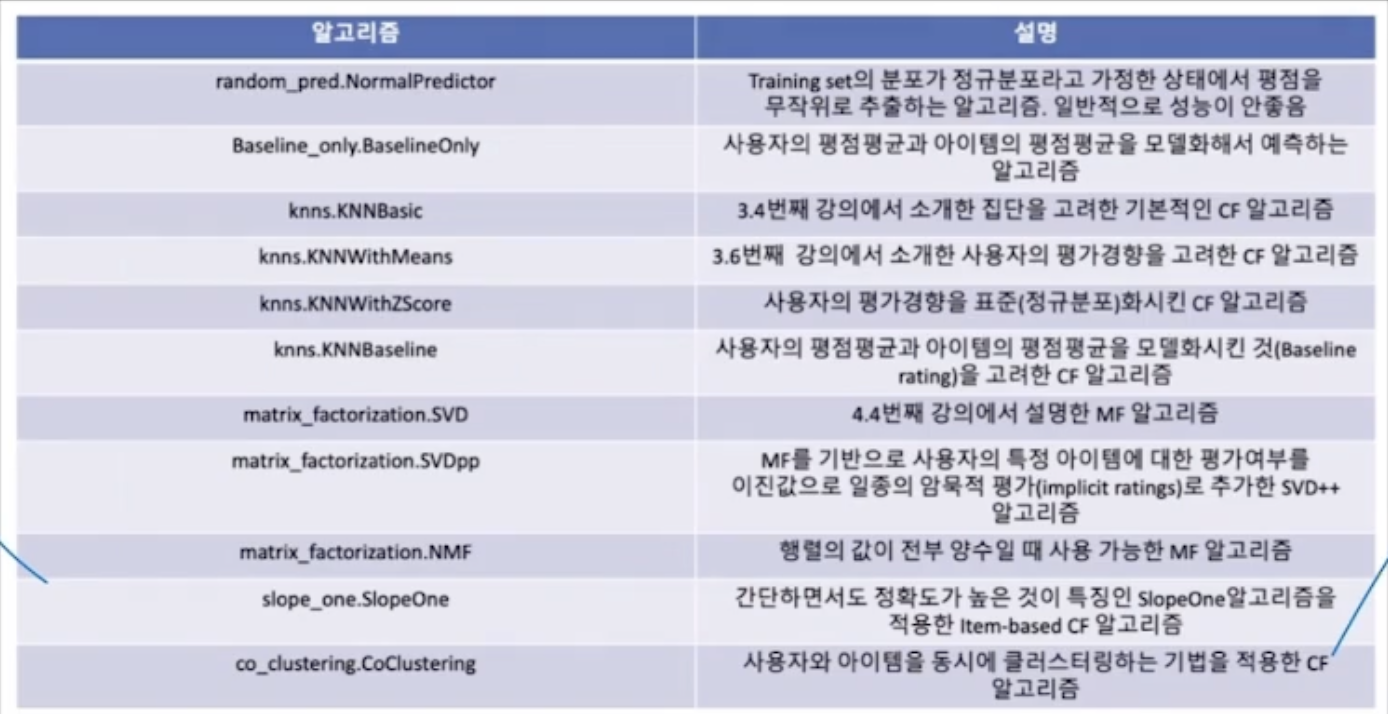
Surprise 라이브러리란, Python에 기반하며 Scikit-learn API와 비슷한 형태로 제공을 하여 추천 시스템 구현을 도와주는 편리한 라이브러리이다.ml-100k : MovieLens 100K 데이터 (앞에서 계속 사용해온 데이터)ml-1m : Movie
14.keras로 MF 구현하기
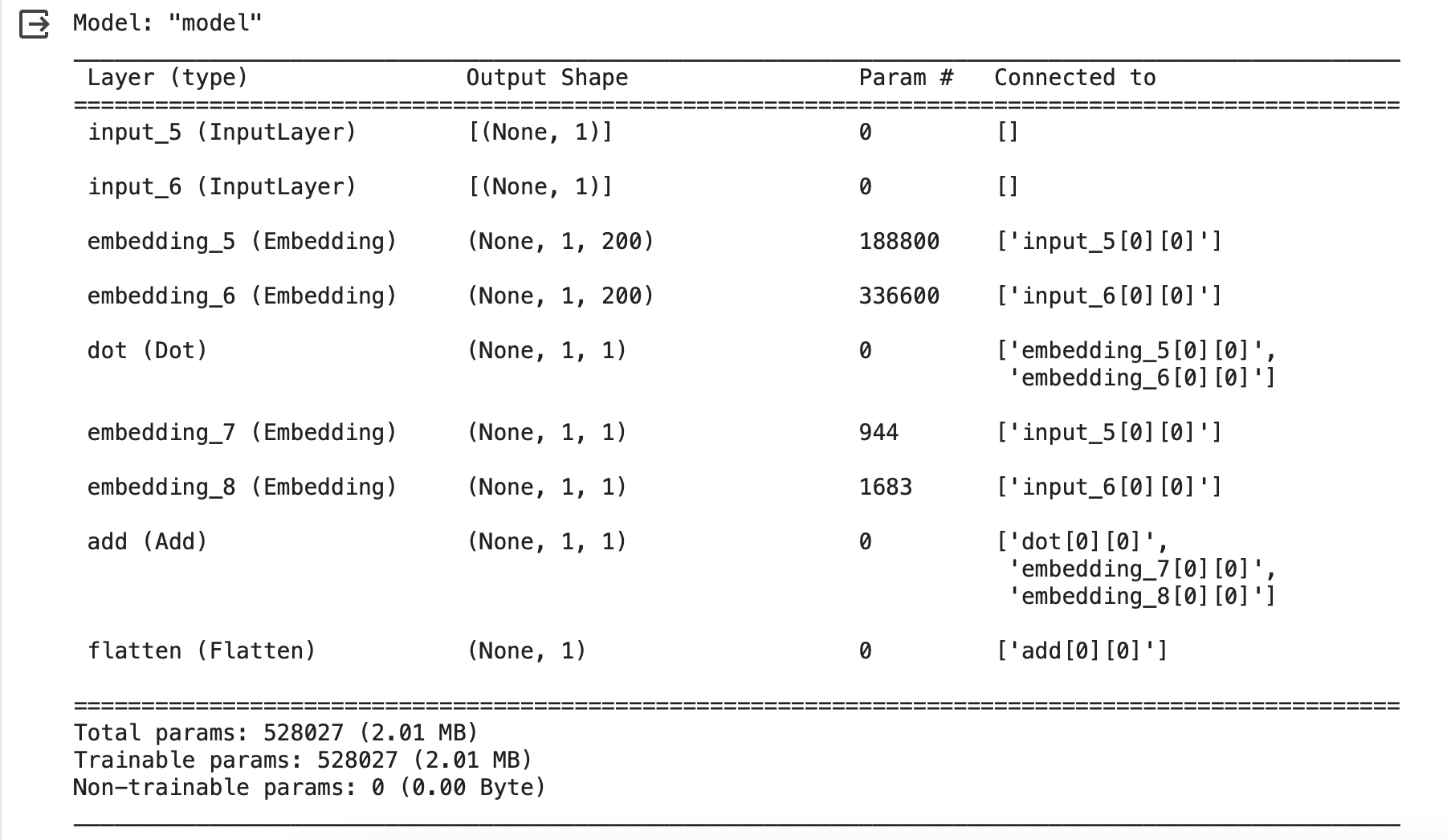
딥러닝(Deep Learning : DL) 다수의 은닉층(hidden layer)을 가진 인공 신경망을 적용한 기법 MF를 신경망으로 변환하기(개념) One-hot Representation > One-hot Representation은 One-hot encodin
15.딥러닝을 이용한 추천 시스템
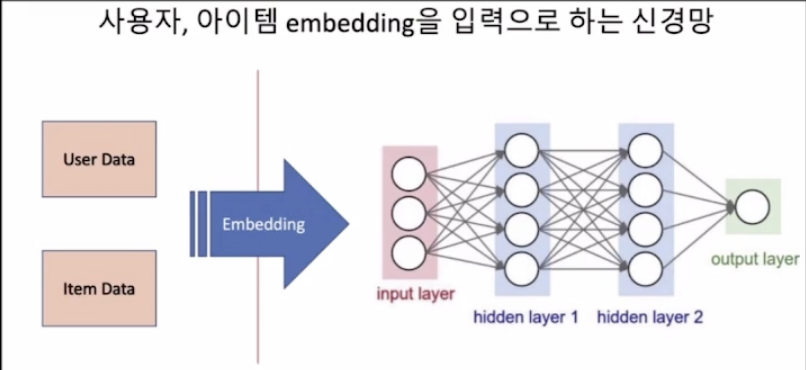
MF를 신경망으로 구성할 때, 사용자 데이터와 아이템 데이터를 embedding해서 입력으로 사용했다.그 점은 똑같게 적용시킬 것이지만, 이제는 MF를 신경망으로 구성한 것에서 hidden layer가 추가된다.hidden layer 은닉층을 사용해 만든 추천 시스템
16.딥러닝 모델에 다양한 변수 활용하기

지금까지 딥러닝 모델은 단순히 사용자가 부여한 아이템의 평점만을 이용하여 추천을 했지만, 현업에서는 userid와 movieid만 있는 상황이 아니다. 그 외에도 다양한 변수들이 있기 때문에 그 다양한 변수들을 활용해서 모델을 구성해보려 한다. 만약 직업에 따라서 영
17.하이브리드 추천 시스템
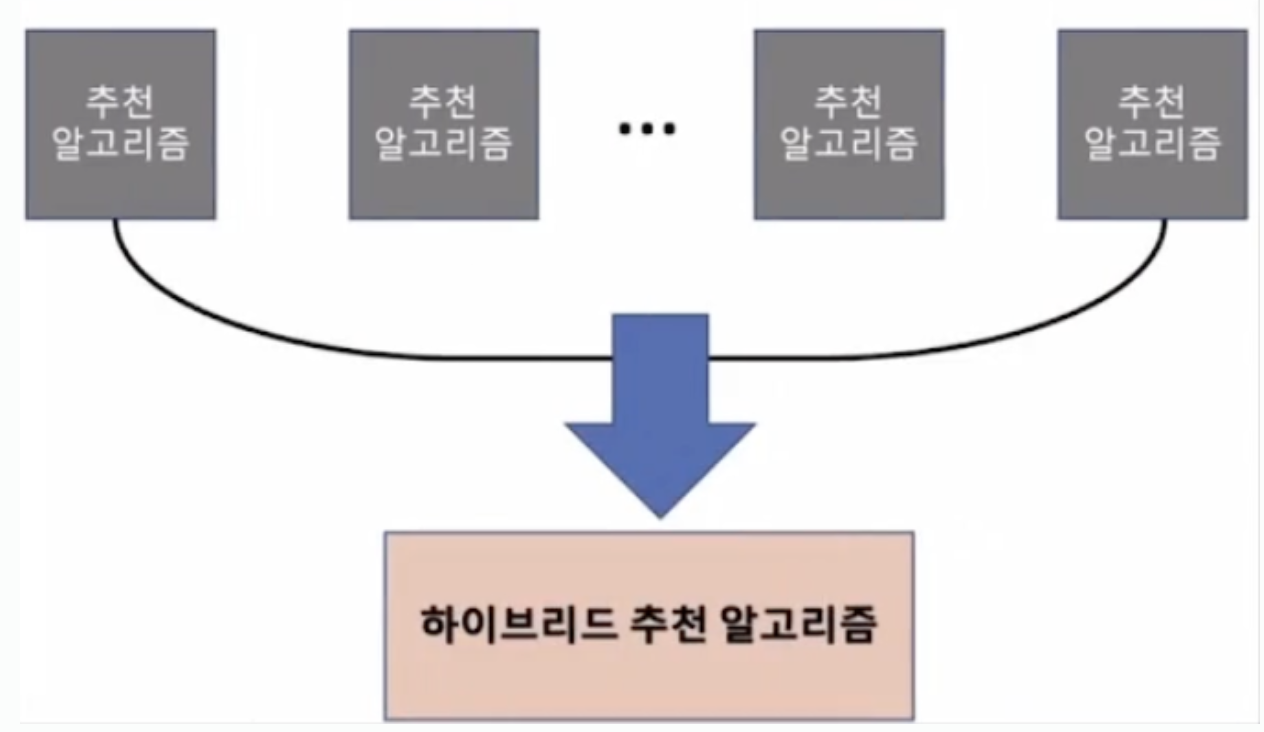
하이브리드 추천 시스템 이전까지는 단일 알고리즘을 사용해서 추천하는 방식이었지만, 이번 블로그는 하이브리드 추천 시스템으로 다수의 추천 알고리즘을 결합해 시스템을 구축하는 경우가 많다. 하이브리드 추천 시스템의 장점 다수의 알고리즘이 개별 사용자의 개별 아이템에 대
18.대규모 데이터 처리를 위한 Sparse Matrix 사용

Sparse Matrix 대규모 데이터의 처리를 위한 Sparse Matrix 희소 매트릭스에 대해서 정리한다. 지금까지 사용한 Movielens 100K 데이터는 약 900명의 사용자와 약 1600개의 영화에 대한 10만개의 평점을 포함하는 데이터이다. 하지만,
19.추천시스템 이슈 사항
신규 사용자와 아이템아이템에 대한 평가가 없는 신규 사용자나 처음 시장에 나온 신제품의 경우 어떻게 추천해줄 것인가?CF 협업 필터링은 기본적으로 신규 사용자와 신규 아이템에 대해서 추천을 하기 어렵다.대규모 사용자와 아이템을 대상으로 추천 알고리즘을 적용하기 위해서