이번에는 sklearn의 train_test_split을 사용하지 않고, shuffle을 사용한다.
train_test_split()
train_test_split의 경우에는 층화추출법을 사용하여 분리했는데, 이 경우 train set의 정답값이 불균형하게 들어가있어도 비율을 맞추어 train set과 test set에 나누어줄 수 있다.
따라서 sample에서 집단간의 이질성이 클(정답값이 매우 불균형할 때) 경우에 층화추출법을 이용해 기존의 모집단 sample의 데이터 분포를 맞춰주어야 한다.
그러나 sample에서 집단간의 이질성이 크지 않은(정답값이 균형적일 때) 경우에 층화추출법을 사용하면 오히려 표본의 대표성을 저해할 수 있다.
shuffle()
shuffle 방식은 랜덤 추출 방식이다.
극단적인 경우, 특정 정답값이 모두 train set에만 몰려있거나 모두 test set에만 몰려있을 수 있다.
# 데이터 준비와 train set, test set 분리
import os
import pandas as pd
import numpy as np
base_src = 'drive/MyDrive/RecoSys/data'
u_data_src = os.path.join(base_src, 'u.data')
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(u_data_src,
sep = '\t',
names = r_cols,
encoding = 'latin-1')
# timestamp 제거
ratings = ratings[['user_id', 'movie_id', 'rating']].astype(int)
# train / test set 분리
from sklearn.utils import shuffle
TRAIN_SIZE = 0.75
# (사용자 - 영화 - 평점)
ratings = shuffle(ratings, random_state=2024)
cutoff = int(TRAIN_SIZE * len(ratings))
ratings_train = ratings.iloc[:cutoff]
ratings_test = ratings.iloc[cutoff:]MF 알고리즘
class NEW_MF():
def __init__(self, ratings, hyper_params):
self.R = np.array(ratings)
self.num_users, self.num_items = np.shape(self.R)
self.K = hyper_params['K']
self.alpha = hyper_params['alpha']
self.beta = hyper_params['beta']
self.iterations = hyper_params['iterations']
self.verbose = hyper_params['verbose']
#########################################
# user_id가 연속값이 아닌 경우가 있을 수 있다.
# id 맵핑 작업
item_id_index = []
index_item_id = []
for i, one_id in enumerate(ratings):
item_id_index.append([one_id,i]) #one_id는 ratings의 실제 movie_id
index_item_id.append([i, one_id])
self.item_id_index = dict(item_id_index)
self.index_item_id = dict(index_item_id)
user_id_index = []
index_user_id = []
for i, one_id in enumerate(ratings.T):
user_id_index.append([one_id, i]) #one_id는 ratings의 실제 user_id
index_user_id.append([i, one_id])
self.user_id_index = dict(user_id_index)
self.index_user_id = dict(index_user_id)
########################################
def rmse(self):
xs, ys = self.R.nonzero()
self.predictions = []
self.errors = []
for x, y in zip(xs, ys):
prediction = self.get_prediction(x, y)
self.predictions.append(prediction)
self.errors.append(self.R[x, y] - prediction)
self.predictions = np.array(self.predictions)
self.errors = np.array(self.errors)
return np.sqrt(np.mean(self.errors**2))
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_prediction(i, j)
e = (r - prediction)
self.b_u[i] += self.alpha * (e - (self.beta * self.b_u[i]))
self.b_d[j] += self.alpha * (e - (self.beta * self.b_d[j]))
self.P[i, :] += self.alpha * ((e * self.Q[j, :]) - (self.beta * self.P[i, :]))
self.Q[j, :] += self.alpha * ((e * self.P[i, :]) - (self.beta * self.Q[j, :]))
def get_prediction(self, i, j):
prediction = self.b + self.b_u[i] + self.b_d[j] + self.P[i, :].dot(self.Q[j, :].T)
return prediction
# test set 선정(분리한 test set을 적용)
def set_test(self, ratings_test):
test_set = []
for i in range(len(ratings_test)):
#평점표에서 0번째 user_id를 받아와 실제 user_id를 user_id_index 딕셔너리에 넣으면 맵핑된 인덱스가 나온다.
x = self.user_id_index[ratings_test.iloc[i, 0]]
y = self.item_id_index[ratings_test.iloc[i, 1]]
z = ratings_test.iloc[i, 2]
test_set.append([x, y, z])
self.R[x, y] = 0 #test set의 값들을 지운다.
self.test_set = test_set
return test_set
# test set RMSE계산
def test_rmse(self):
error = 0
for one_set in self.test_set:
predicted = self.get_prediction(one_set[0], one_set[1])
error += pow(one_set[2] - predicted, 2) #pow 차승
return np.sqrt(error/len(self.test_set))
def train_test(self):
self.P = np.random.normal(scale = 1./self.K,
size = (self.num_users, self.K))
self.Q = np.random.normal(scale = 1./self.K,
size = (self.num_items, self.K))
self.b_u = np.zeros(self.num_users)
self.b_d = np.zeros(self.num_items)
self.b = np.mean(self.R[self.R.nonzero()])
rows, columns = self.R.nonzero()
self.samples = [(i, j, self.R[i, j]) for i, j, in zip(rows, columns)]
training_process = []
for i in range(self.iterations):
np.random.shuffle(self.samples)
self.sgd()
rmse1 = self.rmse() #training
rmse2 = self.test_rmse() #test
training_process.append((i+1, rmse1, rmse2))
if self.verbose:
if (i+1) % 10 == 0:
print('Iteration : %d ; Train RMSE = %.4f ; Test RMSE = %.4f' % (i+1, rmse1, rmse2))
return training_process
def get_one_prediction(self, user_id, item_id):
return self.get_prediction(self.user_id_index[user_id],
self.item_id_index[item_id])
##########################
def full_predicton(self):
return self.b + self.b_u[:, np.newaxis] + self.b_d[np.newaxis, :] + self.P.dot(self.Q.T)
##########################
R_temp = ratings.pivot(index ='user_id',
columns = 'movie_id',
values = 'rating').fillna(0)
hyper_params = {
'K' : 30,
'alpha' : 0.001,
'beta' : 0.02,
'iterations' : 100,
'verbose' : True
}
mf = NEW_MF(R_temp, hyper_params)
test_set = mf.set_test(ratings_test)
result = mf.train_test()
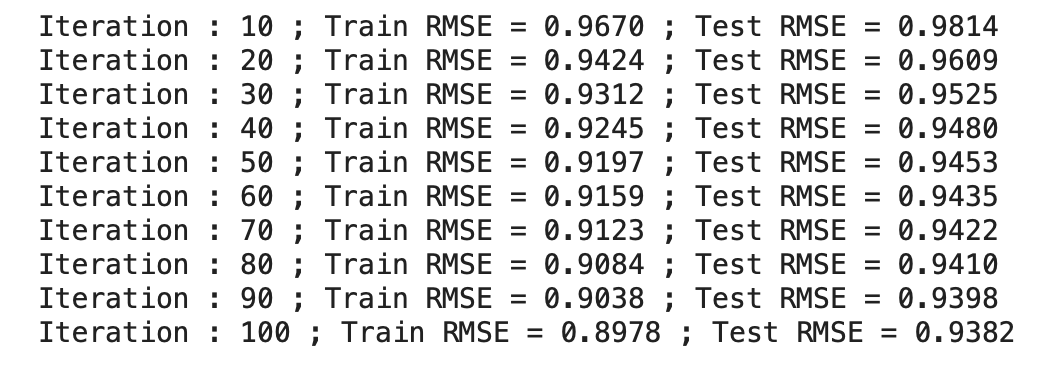
train rmse보다는 당연히 test rmse가 더 높게 나올 수 밖에 없다. 그러나 이전까지 진행해보았던 CF 알고리즘보다 좋은 성능을 보이고 있다.
전체 평점 예측
def full_predicton(self):
> return self.b + self.b_u[:, np.newaxis] + self.b_d[**np.newaxis**, :] + self.P.dot(self.Q.T)full_prediction() 메서드에서 np.newaxis를 사용하는데, 이는 차원을 늘려 브로드캐스팅(Broadcasting)을 가능하게 해준다.
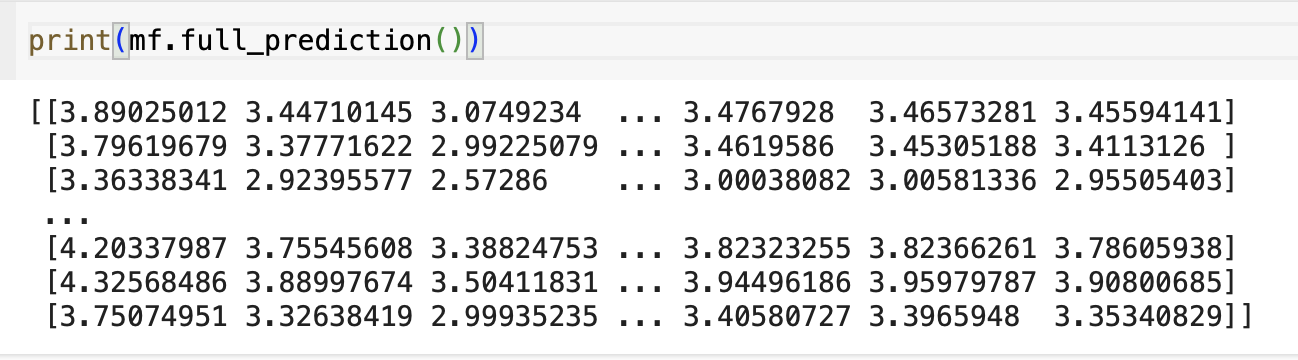
사용자의 평가경향 행렬과 아이템의 평가경향 행렬을 브로드캐스팅 해주어야
P 행렬과 Q의 전치행렬을 내적한 행렬(Matrix Multiplication) 크기와 맞출 수 있다.
하나의 샘플 평점 예측


data analysis, data science