그 외의 CF 정확도 개선 방법
신뢰도 가중
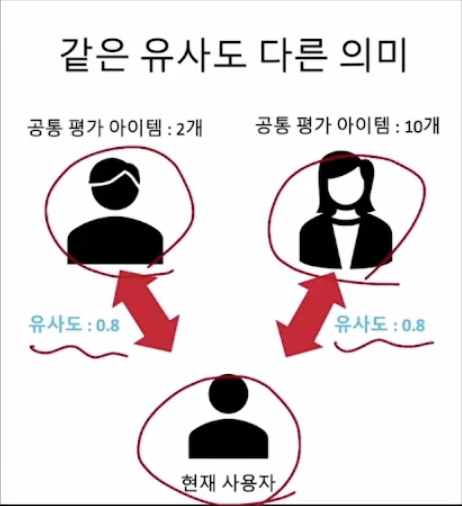
추천 받을 사용자와 유사도가 같은 사용자 2명이 있다고 가정할 때, 각각의 공통 평가 아이템의 개수에 따라서 신뢰도의 차이가 있다.
-> 따라서 사용자 간 유사도를 측정할 때 신뢰도를 가중하자!
하지만, 예측값은 매우 민감하기 때문에 약간의 계산식을 바꿔도가 RMSE값이 크게 변동하기 때문에 fluctuation이 발생하기 때문에 해당하는 공통의 아이템 수를 직접적으로 사용하게 되면 성능저하를 불러일으킬 수 있다.
그러므로 신뢰도가 일정 기준 이상인 사용자만 이용해 계산하기로 한다.
# 사용자 평가 경향을 고려한 함수 / 신뢰도 가중
rating_mean = rating_matrix.mean(axis = 1)
rating_bias = (rating_matrix.T - rating_mean).T
###################################################
# 신뢰도가중
rating_binary_1 = np.array(rating_matrix>0).astype(float) #평점을 true 1.0 false 0.0으로 값을 바꿔준다.
rating_binary_2 = rating_binary_1.T
counts = np.dot(rating_binary_1, rating_binary_2)
counts = pd.DataFrame(counts, index = rating_matrix.index,
columns = rating_matrix.index).fillna(0)
# 모델
def CF_knn_bias_sig(user_id, movie_id, neighbor_size = 0):
if movie_id in rating_bias.columns:
sim_scores = user_similarity[user_id].copy()
movie_ratings = rating_bias[movie_id].copy()
no_rating = movie_ratings.isnull() #movie_ratings에서 null값이면 True, null이 아니면 False
common_counts = counts[user_id] # 해당 사용자와 공통으로 평가한 영화개수
low_significance = common_counts < SIG_LEVEL
none_rating_idx = movie_ratings[no_rating | low_significance].index
movie_ratings = movie_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
if neighbor_size == 0:
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
prediction = prediction + rating_mean[user_id]
else:
if len(sim_scores) > MIN_RATINGS:
neighbor_size = min(neighbor_size, len(sim_scores))
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
user_idx = np.argsort(sim_scores)
sim_scores = sim_scores[user_idx][-neighbor_size:]
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
prediction = prediction + rating_mean[user_id]
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
return prediction
SIG_LEVEL = 5 #신뢰도를 위한 공통 아이템 5개 이상
MIN_RATINGS = 5 #최소 사용자수도 5으로 지정
for neighbor_size in [31,32,33,34]:
print(f'Neighbor size = {neighbor_size} : RMSE = {score(CF_knn_bias_sig, neighbor_size)}')
->
Neighbor size = 31 : RMSE = 0.9465876916505485
Neighbor size = 32 : RMSE = 0.9466371040144399
Neighbor size = 33 : RMSE = 0.9465826437670708
Neighbor size = 34 : RMSE = 0.9466392395592287최적의 이웃크기 32, SIG_LEVEL 5, MIN_RATINGS 5로 지정했을 때 이전 신뢰도 가중하기 전보다 성능이 조금 떨어졌지만, SIG_LEVEL과 MIN_RATINGS를 좀 더 조절해 나가면서 최적의 값을 찾는다면 정확도를 개선시킬 수 있다.
RMSE 개선 방법
prediction에서 예측값이 1에서 5까지인데 1보다 작은 값으로 예측할 수도 있고, 5보다 큰 값으로 예측할 경우
기준범위(1점~5점)에서 벗어나게 되면 정확도가 더 떨어지게 되므로 범위를 맞춰준다.
# 모델
def CF_knn_bias_sig(user_id, movie_id, neighbor_size = 0):
if movie_id in rating_bias.columns:
sim_scores = user_similarity[user_id].copy()
movie_ratings = rating_bias[movie_id].copy()
...
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
##################################
# 추가적으로 RMSE를 조금 개선하는 방법
if prediction <= 1:
prediction = 1
elif prediction >= 5:
prediction = 5
return prediction
for neighbor_size in [31,32,33,34]:
print(f'Neighbor size = {neighbor_size} : RMSE = {score(CF_knn_bias_sig, neighbor_size)}')
->
Neighbor size = 31 : RMSE = 0.9457511887203413
Neighbor size = 32 : RMSE = 0.9458077748408296
Neighbor size = 33 : RMSE = 0.9457630145147692
Neighbor size = 34 : RMSE = 0.9458145352835522prediciton값의 범위를 맞춰준 결과, 정확도가 개선되었다! (0.946 -> -0.945)

data analysis, data science