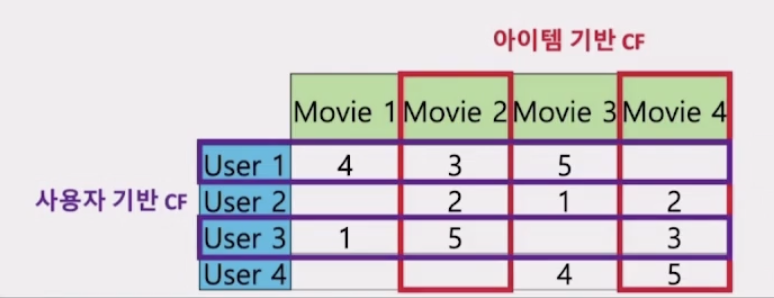
사용자 기반 CF (UBCF)
- 사용자 A와 취향이 비슷한 다른 사용자 집단을 찾고, 이 집단에 속한 사용들이 공통적으로 좋게 평가한 아이템을 추천한다.
- 사용자 A와 유사도 측정을 한 후, 유사한 사용자를 찾지 못한다면 추천해줄 수 없다.
- 유사도 계산 기준이 사용자
장점: 데이터가 풍부한 경우 정확한 추천
단점: 결과에 대한 위험성 존재
아이템 기반 CF (IBCF)
- 사용자들의 평가 패턴을 바탕으로 아이템 간의 유사도를 계산해서 사용자의 특정 아이템에 대한 예측 평점을 계산해 추천한다.
- 기준이 되는 아이템을 제외한 다른 아이템 중에서, 가장 유사한 아이템을 추천한다.
- 유사도 계산 기준이 아이템
장점: 계산이 빠름
단점: 업데이트에 대한 결과 영향이 적음
사용자 기반 CF은 각 사용자별로 맞춤형 추천을 하기 때문에 데이터가 풍부한 경우에는 정확한 추천이 가능하다.
반대로 아이템 기반 CF의 경우 사용자 기반 CF보다 정확도는 떨어지지만, 사용자별로 따로따로 계산을 하지 않기 때문에 계산이 아주 빠르다는 장점이 있다.
사용자 기반 CF는 정확할 때는 아주 정확하지만, 가끔 터무니없는 추천을 하는 경우가 상당히 있지만, 아이템 기반 CF는 그러한 위험이 적다.
사용자 기반 CF에서는 데이터가 조금씩 바뀔 때마다 업데이트를 해야하지만, 아이템 기반 CF에서는 데이터가 조금 바뀌어도 추천 결과에는 영향이 크지 않다. (업데이트를 자주 하지 않아도 된다.)
데이터 크기가 적고, 사용자에 대한 정보가 있는 경우 사용자 기반 CF 적절
데이터 크기가 크고, 충분한 정보가 없는 경우 아이템 기반 CF 적절.
계산이 빠른 장점을 이용해 대용량 데이터를 사용하는 경우에는 아이템 기반 CF를 활용하는 것이 좋다.
지금까지는 사용자 기반 CF를 다뤄왔고, 아래는 아이템 기반 CF 코드이다.
아이템 기반 CF 코드
## 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
#아이템 기준 유사도 측정
rating_matrix_t = np.transpose(rating_matrix) #아이템 간 유사도를 볼 것이기 때문에 전치시켜야 한다.
matrix_dummy = rating_matrix_t.copy().fillna(0)
item_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
item_similarity = pd.DataFrame(item_similarity,
index = rating_matrix_t.index,
columns = rating_matrix_t.index)
def CF_IBCF(user_id, movie_id):
if movie_id in item_similarity.columns:
sim_scores = item_similarity[movie_id] #해당 아이템의 유사도들을 받아오고
user_rating = rating_matrix_t[user_id] #해당 사용자의 평점들을 받아오고
none_rating_idx = user_rating[user_rating.isnull()].index
user_rating = user_rating.dropna()
sim_scores = sim_scores.drop(none_rating_idx)
mean_rating = np.dot(sim_scores, user_rating) / sim_scores.sum()
else:
mean_rating = 3.0
return mean_rating
score(CF_IBCF)
-> 1.0183823258573412아직까지는 사용자 기반 CF와 비슷한 정확도를 보이고 있다.

data analysis, data science