Sparse Matrix
대규모 데이터의 처리를 위한 Sparse Matrix 희소 매트릭스에 대해서 정리한다.
지금까지 사용한 Movielens 100K 데이터는 약 900명의 사용자와 약 1600개의 영화에 대한 10만개의 평점을 포함하는 데이터이다.
하지만, 향후 다루어야 하는 데이터는 이보다 훨씬 더 클 것이다.
예를 들면, Movielens 2M 데이터만 봐도 사용자가 약 13만명, 13만개의 영화에 대한 2000만개의 평가 데이터를 포함하고 있다.
이렇게 되면, 가장 흔히 부딪히는 문제가 메모리의 한계이다.
Movielens 2M 데이터를 full-matrix로 변환하게 되면, 거의 한 180억개의 원소가 필요한 매트릭스를 구해야 한다. 대부분의 PC는 감당할 수 없을 것이고, 혹여나 그 정도의 메모리와 저장공간이 있다고 할지라도 대부분이 원소가 비어 있는 full 매트릭스를 저장해서 처리하는 것 자체가 비효율적이다.
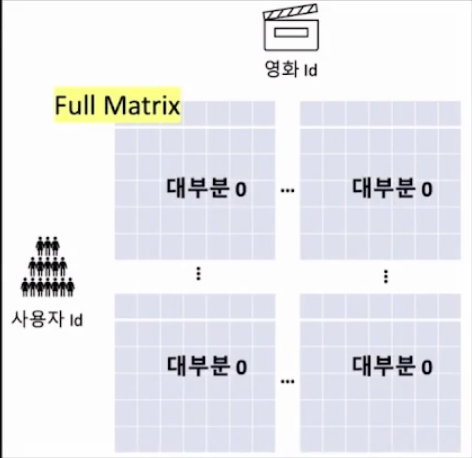
위와 같이 추천 시스템에서 사용되는 대부분의 데이터는 full-matrix로 변환하면 많은 원소가 비어 있는, 평가가 되지 않은 형태이다.
Movielens 100K의 데이터를 예시로 들면 full-matrix 변환했을 때, 원소를 갖는 비율이 0.6%밖에 되지 않는다.
Movielens 20M의 데이터의 경우, full-matrix가 원소를 갖는 비율은 0.1% 밖에 되지 않는다.
이러한 문제를 해결하기 위해 아래 그림과 같이 Sparse Matrix 변환해주는 방식을 사용한다.
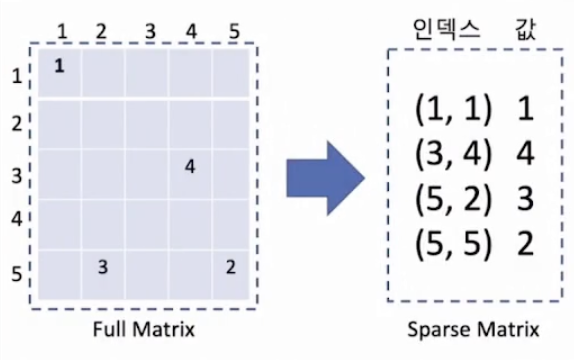
위의 방식으로 변환할 경우, 4개의 원소만 저장하면 된다. 인덱스를 포함하면 12개이다.
데이터가 sparse할수록 저장 공간의 효율성이 극대화된다.
하지만, 데이터를 저장하거나 읽어올 때마다 값이 존재하는지 확인해서 그에 맞는 처리까지 다 해줘야 되기 때문에
데이터 처리에 대한 overhead cost가 커지게 된다.
overhead cost
간접비, 데이터가 크게 sparse하지 않은 경우에는 오히려 효율적이지 않다.
파이썬에서는 SciPy 라이브러리를 제공하여 sparse matrix를 활용할 수 있도록 한다.
Sparse Matrix로의 변환 방법 2가지
-
COO(Coordinate 좌표) 형식
0이 아닌 데이터만 별도의 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열에 저장하는 방식이다.

-
CSR(Comressed Sparse Row) 형식
행 값에 연속적으로 반복되는 값들을 줄이기 위해 COO 형식을 더 보완하는 방식이다.
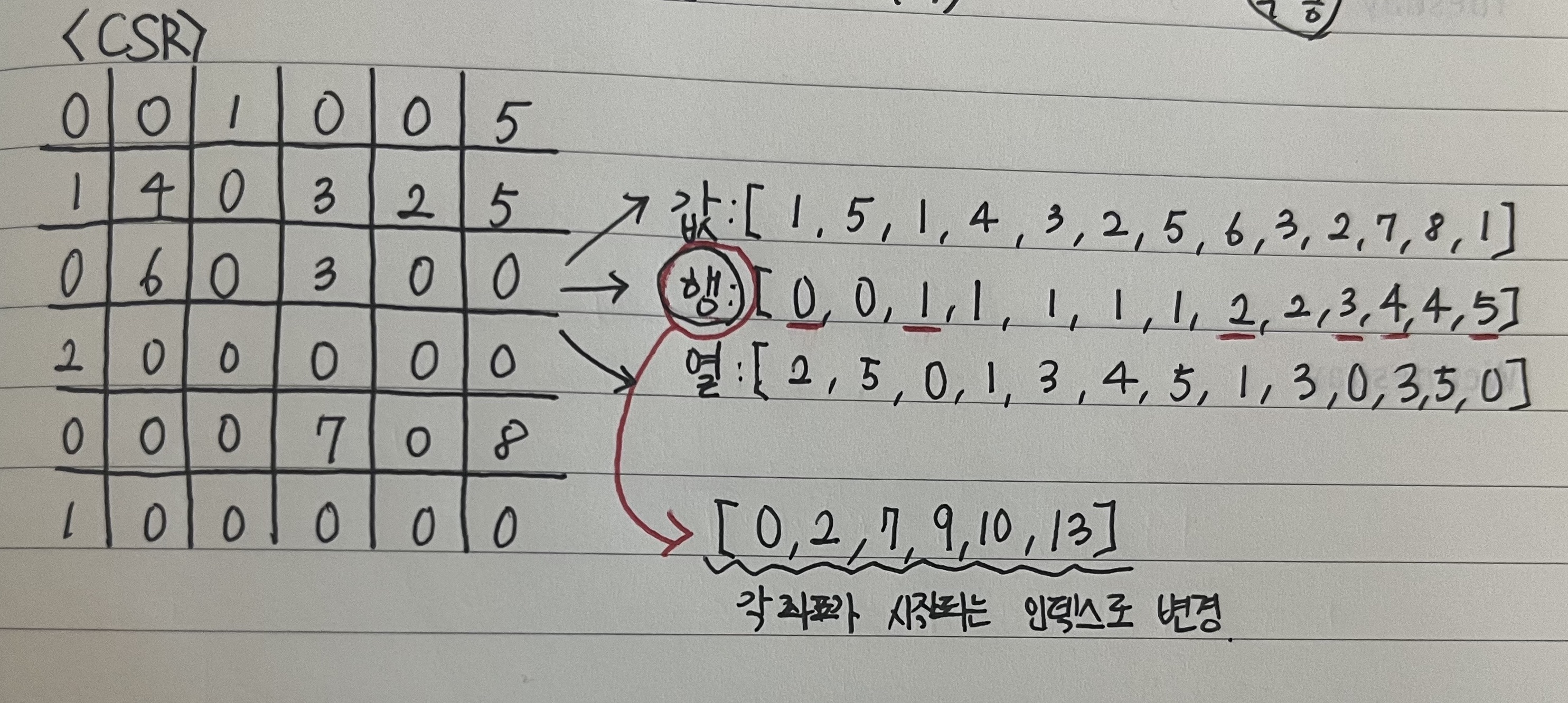
이전에 진행했던 100K 데이터 그대로 sparse matrix로 바꾸어 진행해보았는데
test RMSE 0.9356으로 성능이 많이 개선된 것을 볼 수 있었다.
