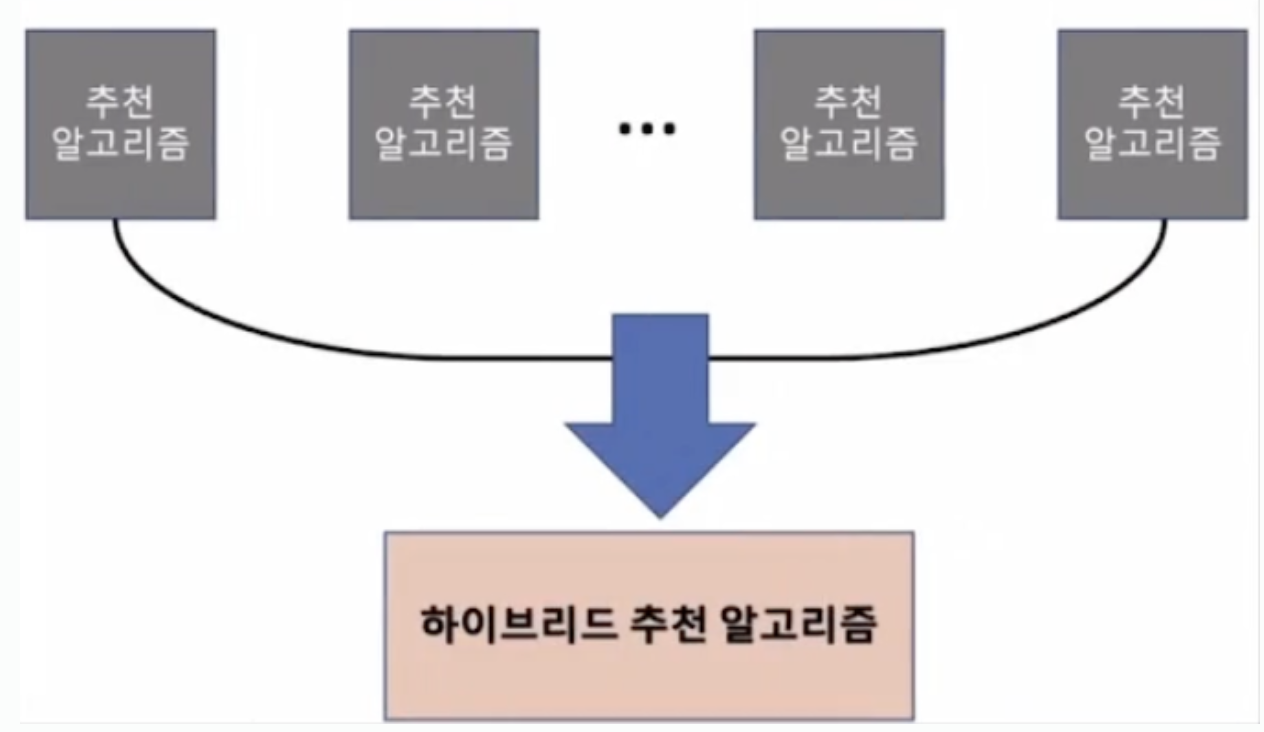
하이브리드 추천 시스템
이전까지는 단일 알고리즘을 사용해서 추천하는 방식이었지만, 이번 블로그는 하이브리드 추천 시스템으로 다수의 추천 알고리즘을 결합해 시스템을 구축하는 경우가 많다.
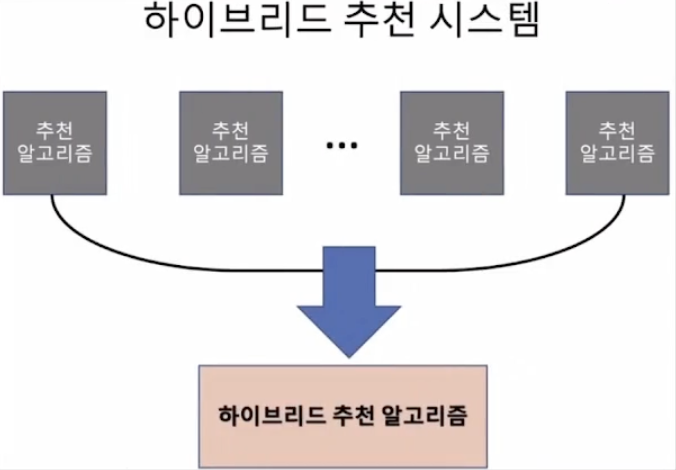
하이브리드 추천 시스템의 장점
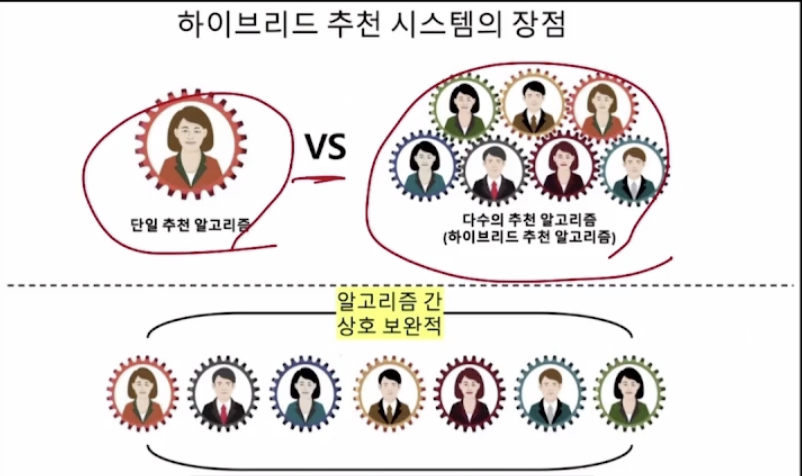
다수의 알고리즘이 개별 사용자의 개별 아이템에 대한 예측치 하나하나에 대해서 일정한 규칙으로 톱니바퀴처럼 일정한 규칙으로 결합된 것이다. 여러 다른 추천 알고리즘을 조합함으로써 개별 알고리즘이 가지는 강점과 약점을 상호보완하고, 보다 정확하고 다양한 추천을 제공할 수 있도록 하는 것을 목표로 한다.
단순히 각각의 추천 알고리즘의 산출된 값들을 가지고 평균을 내는 것과는 다르다.
그 이유는 다수의 추천 알고리즘이 결합되는 경우에는 각 알고리즘끼리 오류를 서로 보정하는 역할을 하기 때문이다.
여러가지 실험을 통해서 실제 결합이 더 좋은 효과를 가져오는지 확인하고 그 다음에 결정해야 한다.
다수의 추천 알고리즘을 어떻게 결합하는가에 따라서도 성능 차이가 많이 나기 때문에 최적의 결합 방법을 찾기 위한 다양한 분석이 선행되어야 한다.
하이브리드 추천 시스템의 원리
from sklearn.model_selection import train_test_split
import random
import numpy as np
import pandas as pd
# 데이터 준비
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('drive/MyDrive/RecoSys/data/u.data',
names = r_cols,
sep = '\t',
encoding = 'latin-1')
ratings_train, ratings_test = train_test_split(ratings,
test_size = 0.2,
shuffle = True,
random_state = 2024)
def RMSE2(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true)-np.array(y_pred))**2))
# 가상의 더미 추천 엔진을 2개 만들어 본다.
def recommender_1(recom_list):
recommendations = []
for pair in recom_list:
recommendations.append(random.random() * 4 + 1)
return np.array(recommendations)
def recommender_2(recom_list):
recommendations = []
for pair in recom_list:
recommendations.append(random.random() * 4 + 1)
return np.array(recommendations)
weight = [0.8, 0.2]
recom_list = np.array(ratings_test)
predictions_1 = recommender_1(recom_list)
predictions_2 = recommender_2(recom_list)
predictions = predictions_1 * weight[0] + predictions_2 * weight[1]
RMSE2(recom_list[:, 2], predictions)CF와 MF를 결합한 하이브리드 추천 시스템
### MF 코드
### CF 코드
### hybrid 추천 알고리즘
# MF의 예측값 받아오기
def recommender_1(recom_list, mf):
recommendations = np.array([
mf.get_one_prediction(user, movie) for (user, movie) in recom_list
])
return recommendations
# CF의 예측값 받아오기
def recommender_2(recom_list, neighbor_size = 0):
recommendations = np.array([CF_knn_bias(user, movie, neighbor_size) for (user, movie) in recom_list])
return recommendations
# 테스트셋을 numpy array 형식으로 추천 대상의 리스트를 만들어본다.
recom_list = np.array(ratings_test.iloc[:,[0, 1]])
predicitons_1 = recommender_1(recom_list, mf)
predicitons_2 = recommender_2(recom_list, 37)
print('reco 1: ', RMSE2(ratings_test.iloc[:, 2], predicitons_1))
print('reco 2: ', RMSE2(ratings_test.iloc[:, 2], predicitons_2))
weight = [0.8, 0.2]
predictions = predictions_1 * weight[0] + predictions_2 * weight[1]
print('reco 1+2 : ', RMSE2(ratings_test.iloc[:, 2], predictions))RMSE를 출력해보았을 때, MF와 CF 개별로 학습한 것보다 하이브리드 방식으로 학습시켰을 때의 RMSE가 미세하게 성능이 더 좋게 나온다.
MF: 0.9358841745724632
CF: 0.9436748030960225
Hybrid: 0.9337873022984509
이러한 하이브리드 모델 또한 가중치의 크기 및 각 개별 모델의 파라미터 조정을 통해 성능을 더욱 높일 수 있다.
가중치를 0~1 0.01 간격으로 하이드리드 모델 예측 진행
result = []
weight_rate = []
for i in np.arange(0, 1, 0.01):
weight = [i, 1.0-i]
predictions = predictions_1 * weight[0] + predictions_2 * weight[1]
print('weights - %.2f : %.2f RMSE = %.7f' %(weight[0], weight[1], RMSE2(ratings_test.iloc[:,2], predictions)))
result.append(RMSE2(ratings_test.iloc[:,2], predictions))
weight_rate.append(weight)
print(min(result))
index_min = result.index(min(result))
print(weight_rate[index_min])가중치를 0.65, 0.35로 설정하는 것이 가장 좋으 성능을 낸다.
