사용자 집단별 추천
best-seller 방식은 전체 사용자의 평점평균을 사용하기 때문에
집단간의 평가 경향이 있다고 가정한다면, 예측값에 대해서 노이즈값이 많이 낀다고 볼 수 있다.
따라서 성별, 나이, 직업 등으로 집단을 나누어 best-seller 방식을 적용해본다.
Gender 기준 추천
기존에는 movie_id로 groupby 했었지만, 성별 컬럼을 추가해서 groupby 한 후 영화의 평점 평균을 구한다.
성별 기준으로 나누어 평균 평점을 구하고, 해당 성별의 평균 평점이 없다면(즉, 남성이 해당 영화를 보고 평가를 남기지 않았다면) 1~5점 중 중간인 3점으로 대체한다.
# 성별에 따른 예측값 계산
merged_ratings = pd.merge(x_train, users) # 공통의 user_id로 merge. 성별 정보를 가져오기 위해
users = users.set_index('user_id')
# 성별에 따른 영화 평균
g_mean = merged_ratings[['movie_id', 'sex', 'rating']].groupby(['movie_id', 'sex'])['rating'].mean()train set의 full matrix를 구한다.
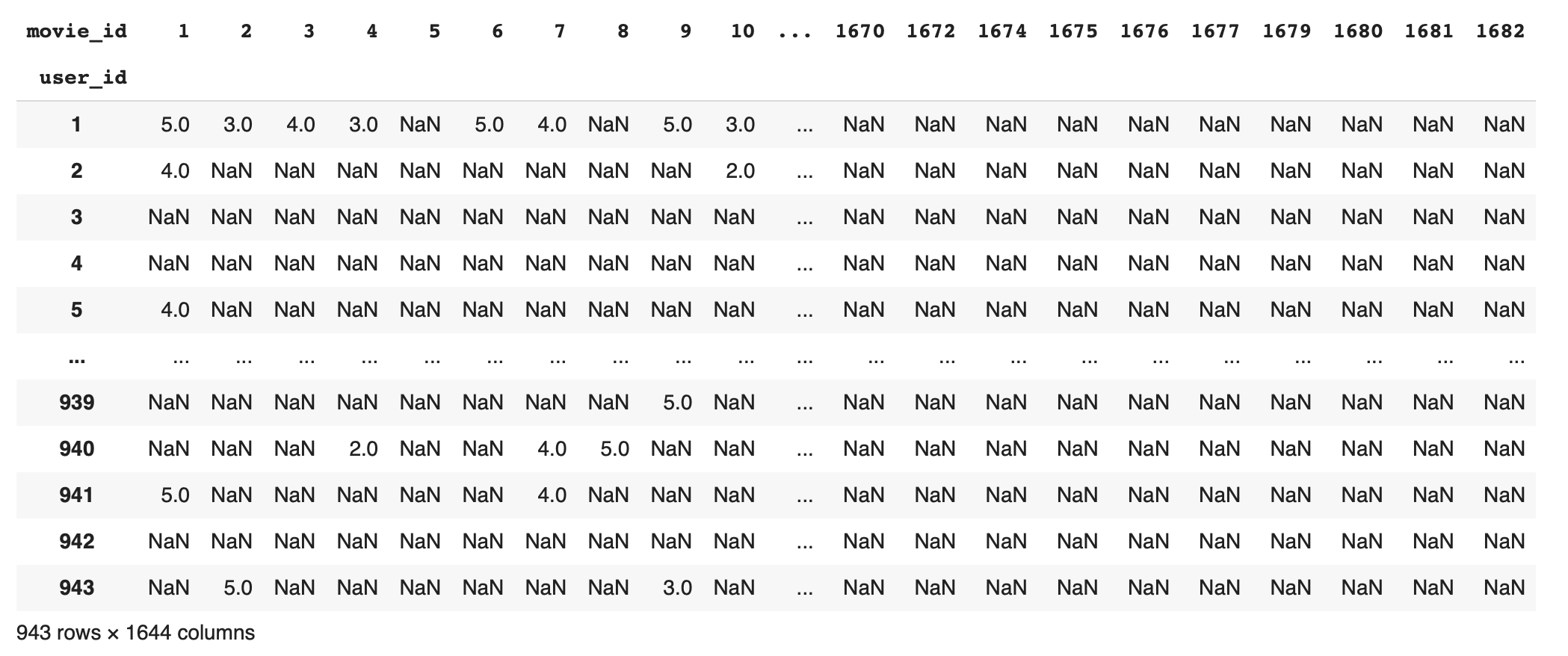
rating_matrix = x_train.pivot(index = 'user_id',
columns = 'movie_id',
values = 'rating')여기서 rating_matrix는 943명의 user와 1640 편의 영화 정보가 있는 train 데이터로 만든 피벗 테이블이다.
결과 : 1.035255636002038
성별로 집단을 나눠서 추천하는 것이 성능적으로 더 좋지는 않다.
성별뿐만 아니라 연령별로 평가의 경향성이 생길 수도 있는 것이므로, 성별 외의 여러 가지 요인이 될 수 있는 것에 대해서 실험을 해보려 한다.
Age 기준 추천
결과 : 1.2416118556135005
성능이 확 나빠졌다. 아무래도 연령을 너무 단순한 방식으로 범주를 나누었기 때문에 연령으로 집단을 나누고 추천하는 방식은 적절하지 않다.
Occupation 기준 추천
결과 : 1.1237151020696534
연령보다는 직업별로 사용자 집단을 나누었을 때 추천 알고리즘의 성능이 더 오르지만, 사용자 집단 별로 나누지 않았을 경우가 더 loss가 적다.
혹시 특성들을 묶어 pair를 만들면 어떨까 하는 생각에
이번에는 성별과 직업으로 pair 만들어서 score를 계산해본다.
Age-Occupation 기준 추천
결과 : 1.158044759987755
아무래도 연령별로 사용자집단을 나누었을 때보다는 성능이 좋지만, 직업별로 사용자집단을 나누었을 때보다는 성능이 나쁘다.
사람들의 연령에 따라 좋아하는 영화가 달라지지 않고, 연령은 개인의 취향에 크게 영향을 미치지 않는다고 볼 수도 있고,
제한된 유저데이터를 통해 추천하기 때문에 집단을 나누지 않았을 때보다 연령별로 사용자집단을 나누었을 때 성능이 나빠지는 것이라고 볼 수도 있는 것 같다.
