협업 필터링 추천 시스템
협업 필터링의 원리
어떤 아이템에 대해 비슷한 취향을 가진 사람들은 다른 아이템 또한 비슷한 취향을 가질 것이다.
사용자 집단별 추천과 같이 인구통계학적 변수를 기준으로 나누는 것이 아니라 취향을 고려해서 추천하자!
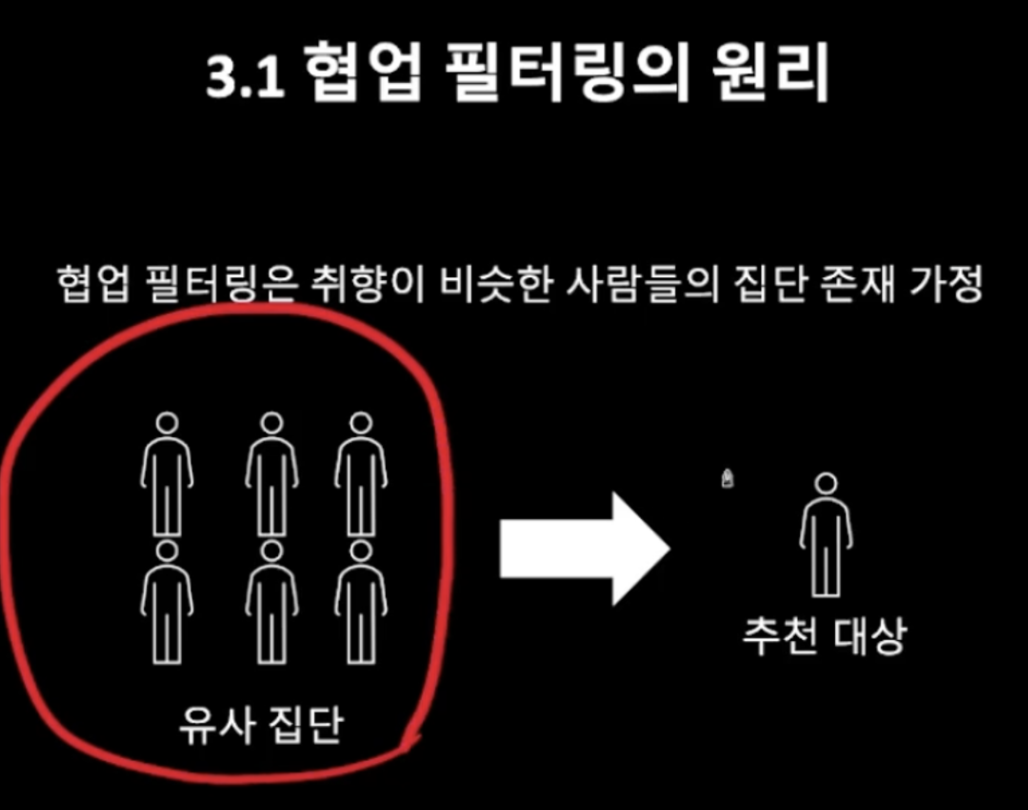
협업 필터링은 취향이 비슷한 사람들이 존재할 것이라고 가정하고,
집단을 특정해 그 집단의 구성원들이 좋아하는 아이템을 추천해준다.
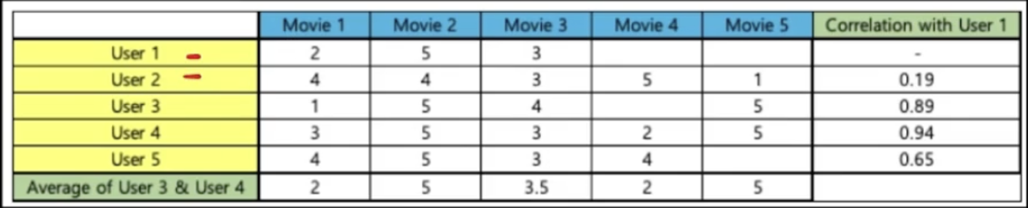
5개의 영화와 5명의 사람으로 이루어져 있는 데이터
만약 user1에게 협업 필터링을 적용한다고 가정하면, 우선 user1과 가장 유사한 사용자를 찾기 위해서 각 사용자 평가에 대해서 유사도를 계산한다.
user1과 유사도가 높은 사용자 → user3, user4
user3, user4가 높게 평가한 영화를 찾아서 user1이 보지 않은 것을 추천.
유사도 지표
CF에서는 사용자 간 유사도를 구하는 것이 핵심이다.
유사도를 구하는 여러가지 방법들 : 상관계수, 코사인 유사도 등
1. 상관계수
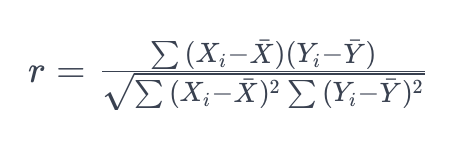
하지만, 협업 필터링에서 상관계수는 잘 쓰이지 않는다.
2.코사인유사도
- 코사인 유사도는 -1에서 1까지의 값으로 나타낼 수 있는데 -1은 완전히 반대인 경우, 1은 완전히 같은 경우를 나타낸다.
- 코사인 유사도가 0이라면 서로 독립적으로 존재하는 경우이다.

왼쪽의 그래프에서 x축은 1번 영화에 대한 평점축이고,
y축은 2번 영화에 대한 평점 축이어서
A사용자와 B사용자의의 1번영화, 2번 영화에 대한 평점을 좌표상에 표시한 그래프이다.
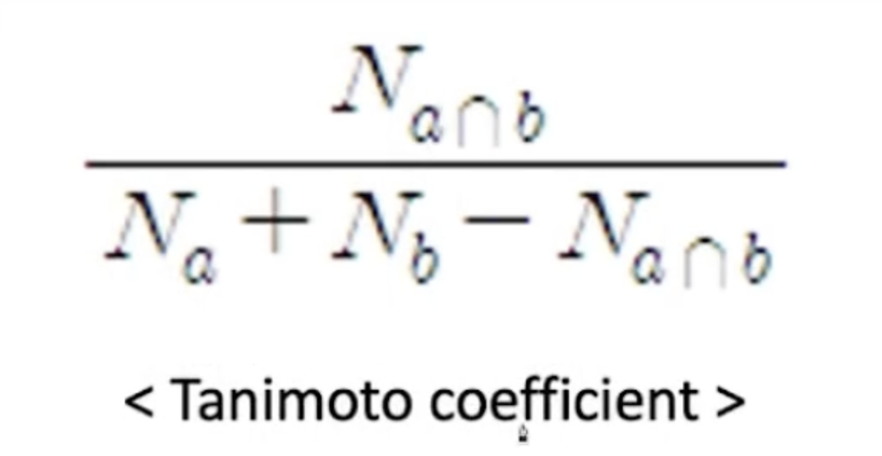
- 영화를 봤다, 보지 않았다와 같은 이진값에 대해서는 타니모토 계수를 사용한다.
- 타니모토 계수는 0에서 1까지의 값을 가지며, 0은 두 집합이 공통 원소가 없음을 나타내고, 1은 두 집합이 완전히 동일함을 나타냅니다. 이 계수는 주로 분자와 분모의 크기가 다르면서도 두 집합 간의 공통성을 측정하는 데 사용됩니다.
기본 CF 알고리즘 (코사인 유사도 활용)
- 모든 사용자 간 평가의 유사도 계산
- 추천 대상과 다른 사용자 간 유사도 추출
- 추천 대상이 평가하지 않은 아이템에 대한 예상 평가값 계산
- 아이템 중에서 예상 평가값 중 가장 높은 n개 추천
데이터 준비
import os
import pandas as pd
import numpy as np
base_src = 'drive/MyDrive/RecoSys/data'
u_user_src = os.path.join(base_src, 'u.user')
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv(u_user_src, sep = '|', names = u_cols, encoding = 'latin-1')
u_item_src = os.path.join(base_src, 'u.item')
i_cols = ['movie_id', 'title', 'release date', 'video release date', 'IMDB URL',
'unknown', 'Action', 'Adventure', 'Animation', 'Children\'s', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv(u_item_src, sep = '|', names = i_cols, encoding = 'latin-1')
u_data_src = os.path.join(base_src, 'u.data')
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(u_data_src, sep = '\t', names = r_cols, encoding = 'latin-1')
# 정확도(RMSE) 를 계산하는 함수
def RMSE(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true)-np.array(y_pred))**2))
# 모델별 RMSE를 계산하는 함수 / 재사용성 좋음
def score(model): # 테스트 데이터 성능을 계산하는 함수
id_pairs = zip(x_test['user_id'], x_test['movie_id'])
y_pred = np.array([model(user, movie) for (user, movie) in id_pairs])
y_true = np.array(x_test['rating'])
return RMSE(y_true, y_pred)
from sklearn.model_selection import train_test_split
x = ratings.copy()
y = ratings['user_id'] # 비슷한 사용자를 예측하는 것이 목표
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size = 0.25,
stratify = y)
rating_matrix = x_train.pivot(index = 'user_id',
columns = 'movie_id',
values = 'rating')코사인 유사도 계산
## 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity,
index = rating_matrix.index,
columns = rating_matrix.index)user_similarity를 데이터프레임으로 나타내면,
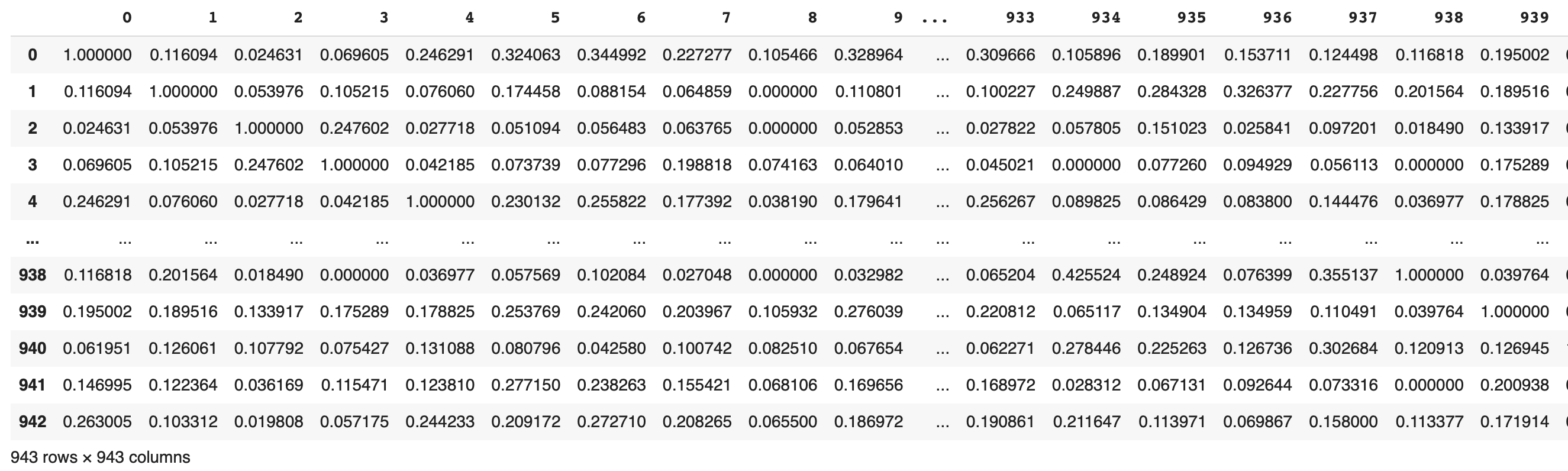
user간 유사도가 나온다.
user간 유사도를 가중해서 평균 구하기
## 주어진 영화의(movie_id) 가중평균 rating을 계산하는 함수
def CF_simple(user_id, movie_id):
if movie_id in rating_matrix.columns:
sim_scores = user_similarity[user_id].copy() #주어진 user_id와의 유사성을 뽑고
movie_ratings = rating_matrix[movie_id].copy() #주어진 movie에 대한 다른 사용자들의 평가도 추출
none_rating_idx = movie_ratings[movie_ratings.isnull()].index #주어진 영화에 대해 평가하지 않은 사용자를 가중평균에서 제외할 때 null값인 사용자 인덱스를 뽑는다.
movie_ratings = movie_ratings.dropna()
sim_scores = sim_scores.drop(none_rating_idx)
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
return mean_rating
score(CF_simple)
→ 1.0173993028282589유사도가 더 높은 사용자에게 가중치를 더 두어서 추천하는 것이 더 좋은 성능을 내는 것을 볼 수 있다.

data analysis, data science