스파르타코딩클럽
내일배움캠프AI 웹개발자양성과정 2회차
실전 머신러닝 적용 - 1주차 개발일지
1. 머신러닝 (machine learning)
: 주어진 문제를 해결하기 위하여 현재 가지고 있는 데이터로 학습시켜 새로운 데이터에 대한 결과를 스스로 도출할 수 있도록하는 인공지능의 한 분야
1) 분류 (classification)
: 입력값에 따른 결과값을 범주(class)별로 나타낼 수 있는 문제
ex)
동물 사진을 입력받아 어떤 동물인지 판단
input : 고양이사진 -> output : 고양이
input : 강아지사진 -> output : 강아지
2) 회귀 (regression)
: 결과값이 범주로 나눠져있지 않고 연속적인 문제
ex)
얼굴 사진을 입력받아 나이 예측
input : 사진 1 -> output : 19.4세
input : 사진 2 -> output : 64.3세
2. 선형 회귀 (linear regression)
: 결과값을 선형적인 함수로 예측하는 방법
: weight, 기울기
: bias
3. 경사하강법 (gradient descent method)
: 손실 함수 (loss function)을 최소화으로 시키기위한 방법
- 확률적 경사하강법 (SGD : stochastric gradient descent)
: 손실 함수를 계산할 때 데이터의 일부분(mini-batch)만 취급하여 빠르게 학습하는 방법
BGD (batch gradient descent) : 모든 데이터를 이용하여 손실함수 계산하는 방법
- SGD의 장점
- 계산이 빠르기 때문에 빨리 학습할 수 있음
- local minimum에 빠질 확률이 적다.
4. 학습률 (learning rate)
: 한번 학습할 때 손실 값이 가장 작은 상태 (global cost minimum)로 가기위한 step의 크기
learning rate가 클 때
- 장점 : 한번 학습할 때 최소점으로 가까이 갈 수 있기 때문에 최소 학습할 때 좋음
- 단점 : 한번에 많은 양을 학습하기 때문에 일정 최소값에 도달하면 더이상 손실함수값이 줄어 들지 않는다.
learning rate가 작을 때
- 장점 : 최소점을 찾는데 보다 세밀하게 학습하며 접근할 수 있다.
- 단점 : 최초 학습할 때 처럼 손실함수값이 클 때는 학습양이 적어서 시간이 오래걸림
5. 데이터셋 분할
: 학습/검증/테스트 데이터셋
학습 데이터셋 (Training set)
: 머신러닝을 학습시키는 용도 - 전체의 80%
검증 데이터셋 (Validation set)
: 학습시킨 모델을 검증하고 튜닝하는 목적 - 전체의 20%
테스트 데이터셋 (Test set)
: 실제 환경에서 평가하는 데이터 셋
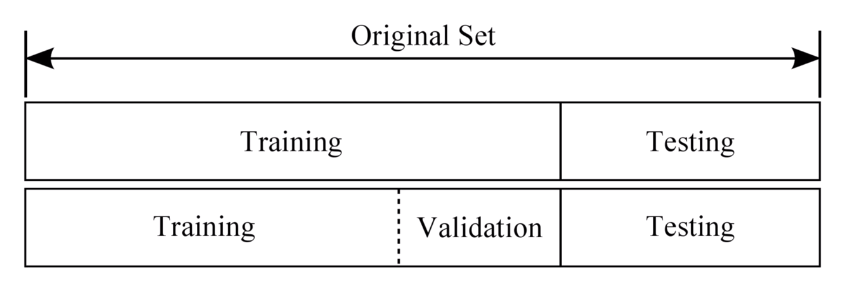
출처: https://3months.tistory.com/118
6. 실습
숙제 - 선형 회귀
- 연차-연봉 데이터셋으로 선형회귀 구현하기
https://colab.research.google.com/drive/1_9HdPkyP-O89UaNi58VMdkQVKGcetJ9t
