본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
4주차까지의 내용이 컴퓨터구조의 절반정도되는걸보니 이제 왔던 만큼만 더가면 비전공자였던 제가 느끼기에 가장 큰 벽이었던 CS의 첫번째 챕터를 마무리하게되네요
사실 이 포스팅은 저를 위한 정리이기도 하지만 혹여나 저와 같은 상황에 있는 누군가가 읽더라도 제가 이해한만큼은 이해하면 좋겠다는 마음에서 정리하는것이기도 합니다
컴퓨터구조를 공부한다고 하면 거의 열에 여덟정도는
그 재미없는걸 한다고...?
라고 이야기를 하더라고요

이렇게 이야기하는 사람의 대부분이 전공자라는게 웃기긴했습니다ㅋㅋㅋㅋ
근데 저는 정말 재미있게 하고 있는데 아마 제가 학교에서 전공수업을 들었었다면 저도 그런사람들중에 한명이지 않았을까라는 생각이 들더라고요
지금 저는 개발자가 되기 위해서 필요한 CS라는거에대해서 전공수준의 지식을 배울 수 있는 기회가 없었고 그 기회가 없다는게 늘 마음이 짐이었던 사람이어서 이렇게 제대로 공부를 할 수 있다는 사실자체에 만족을 하는것같기도 합니다
중간고사 기말고사 과제가 있었다면 저도 다르지 않았을거같긴하네요...ㅎㅎ
서두가 너무 길었네요 본격적으로 5주차 내용인 pipline에 대해 이야기해보겟습니다!
Pipeline Basic
Pipeline Analogy
저번 포스팅 마지막에 우리가 Pipeline기법을 사용하게 된 배경에 대해서 설명을 했었는데요
한가지 예시를 들어보겠습니다
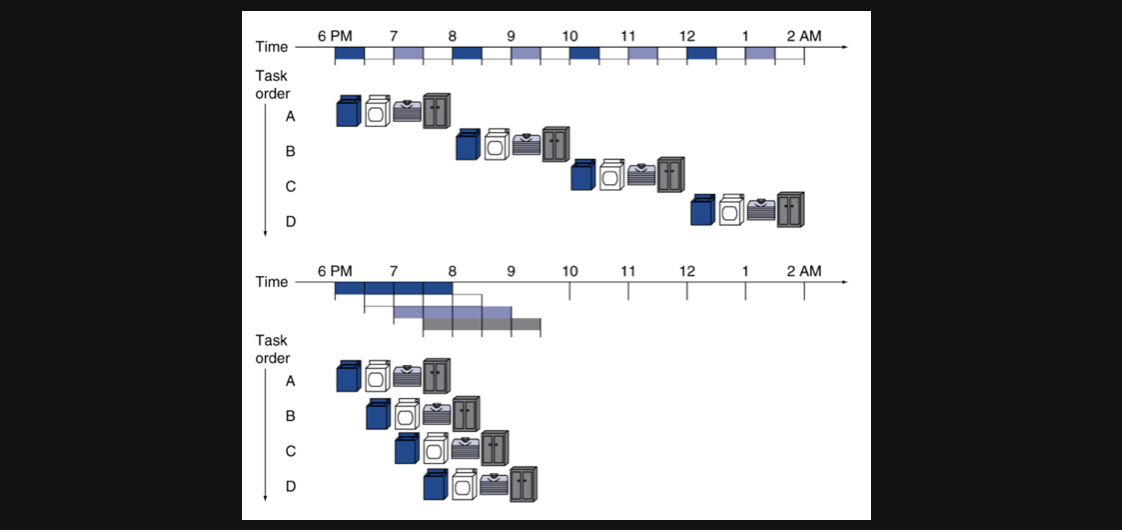
우리가 빨래를 하려하는데 진짜 너무 빨래가 밀려있어서 4번을 돌려야한다고 생각해보겠습니다
빨래(1)하고 건조(2)하고 접고(3) 다시 장롱에 넣는(4) 일련의 과정을 4번을 반복할때 어떻게 하시나요?
빨래가 끝나면 건조를하고 그동안 기다렸다가 건조가 끝나면 기다렸다가 접고 넣고 다시 다음 빨래를 하고 이렇게 하는사람은 아마 많이 없을겁니다
만약에 모든 과정이 30분씩 걸린다 가정하면 방금 말했던 방식으로 집안일을하면 8시간이 걸리게됩니다. 이 방식을 1번방식이라고 하겠습니다
보통은 이렇게 하죠 빨래가 끝나면 건조하는 동시에 다음빨래를 넣고 건조가 끝나면 개는동안 다음빨래를 넣고...
그렇게 하면 위의그림의 아래부분처럼 3시간반이면 4번의 빨래를 끝낼 수 있게됩니다. 이 방식을 2번방식이라고 하겠습니다
1번방식이 저희가 지금까지 공부했던 single cycle방식입니다. 하나의 instruction이 끝난후에 다음 instruction을 수행하는 방식이죠
그리고 2번방식이 pipeline방식입니다
좋아지는건 알겠는데
얼마나좋아지는건데?
좋은 질문입니다 애매하게 좋아집니다는 그렇게 좋은 답변이 아니죠
위에 빨래예시로 보면 8시간걸릴 일이 3시간반이 걸렸으니 2.3배 빨라진거죠
자, 만약에 우리가 저 빨래의 cycle을 무한대(n)로 돌린다고 가정해보겠습니다
1번방식으로는 4n만큼의 일을 수행하게될겁니다 2번방식은 어떨까요 총 n+3번의 일을 하게될겁니다
(그림을 몇번 그려보시면 왜 n+3인지 이해가 되더라고요ㅎㅎ...)
그럼 1번 방식에 비해서 2번방식이 아래수식에 의해서 4배가 빨라지게 됩니다
lim(4n/(3+n)), n->무한대
결론적으로 이상적인경우(task가 무한히 늘어날 경우) task가 n개로 나어지면 2번방식이 20배 빠르게 일을 수행할수 있다는 결론을 얻을 수 있습니다
MIPS Pipeline
pipelining을 하려면 우선 우리가 하려는 task를 여러개로 쪼개야합니다
위에서 말씀드렸던것처럼 task를 쪼개는만큼 성능이 향상되니까요
clock cycle과 연관지어서 말해보면 우리가 single cycle같은 경우엔 하나의 전체적인 task가 하나의 clock cycle안에 수행이 완료되어야했죠
결국 single cycle의 경우엔 명령어 1개가 하나의 clock cycle에 수행됩니다
하지만 pipelining의 경우엔 하나의 task를 여러개의 sub-task로 나눠야하고 각 sub-task가 하나의 clock cycle에 수행되어야합니다
결국 pipelining의 경우엔 명령어 1개가 여러개의 clock cycle에 수행됩니다
자 그러면 MIPS에서는 하나의 instruction을 어떤 기준으로 sub-task로 나눌까요

이렇게 다섯가지로 나눈다고 합니다
1. instruction을 fetch하는 sub-task
2. instruction을 decode하고 instruction으로 부터 얻은 register에서의 값을 read하는 sub-task
3. 실제로 operation을 수행하고 주소값을 계산하는 sub-task
4. 메모리 operand에 접근하는 sub-task
5. 마지막으로 결과를 write하는 sub-task
그림으로 보면 아래와 같습니다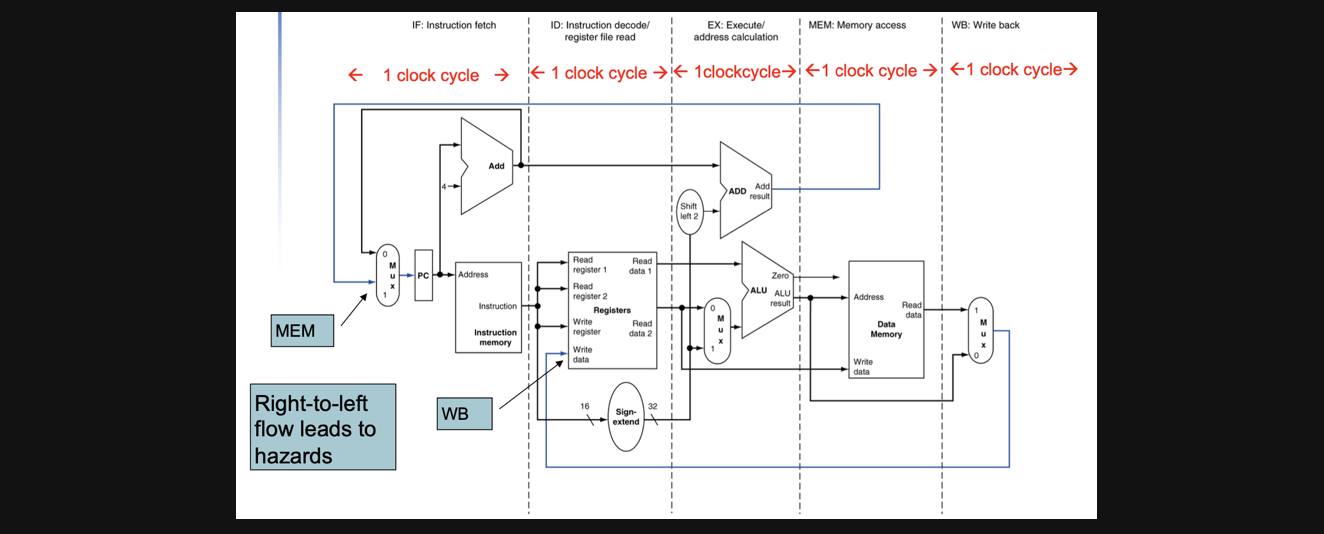
지번시간까지 봤던 논리회로와 똑같죠?
대신 우리가 보던 논리회로가 앞에서부터 5부분의 sub-task로 나누어져있습니다
각각의 sub-task가 하나의 clock cycle을 가지고 있습니다
결국 하나의 instruction을 수행하기 위해선 여러번의 clock cycle을 거쳐야하니,
결국 pipelining의 경우엔 명령어 1개가 여러개의 clock cycle에 수행됩니다
라는 말의 뜻을 그림을 보고 이해하시면 될거같습니다
그림을 보고 알고 넘어가야할 부분을 짚고 다음 주제로 넘어가보겠습니다
우선 첫번째는 파란색 선인데요
data path를 공부할때 data의 흐름이 거의 대부분 왼쪽에서 오른쪽으로 넘어가는데요 특정경우엔 data path의 흐름과 반대로 될경우가 있습니다 이런경우엔 hazard라는 방식으로 해결을 해야하는데 추후에 배울 내용입니다
여기다가 추후 포스팅이 끝나면 링크를 달아놓겠습니다
그리고 두번째는 ID와 WD의 경우에 사실 WB의 결과가 ID에서 write data로 input되는거잖아요? 결국 같은 register를 사용하는데 회로의 그림상 아얘 다른 sub-task위치에 있지만 register를 공유한다로 이해해주시면 됩니다
세번째는 가장 중요한 부분인데요
바로 각각의 cycle이 끝나면 다음 cycle로 결과를 넘겨줘야하기 때문에 cycle이 끝나면 결과를 저장해줘야한다는겁니다
아주 익숙한 그림이죠?
우리가 어떤 state element를 combinational logic에 넣어주면 output이 다시 state element에 저장되어서 다시 그게 combinational logic의 input이 되는 그런 순환이 계속 반복되는거고 logic에 대한 결과는 하나의 cycle이 끝날때 기록된다라고 배웠죠
결국은 그 cycle이 끝나고 연산한 결과가 state element에 저장이 되어야한다는 뜻이됩니다
마찬가지로 pipelining에서도 각 cycle이 끝날때의 결과가 저장되어야 다음 cycle이 정상적으로 작동될수있다는 말이기도 해서 cycle마다 저장할수있는 수단과 방법이 필요하다는걸 알 수가있습니다
Pipeline register
그래서 각각의 cycle사이에 pipline register라는걸 두는 설계를 통해서 각 cycle의 결과를 저장하게됩니다
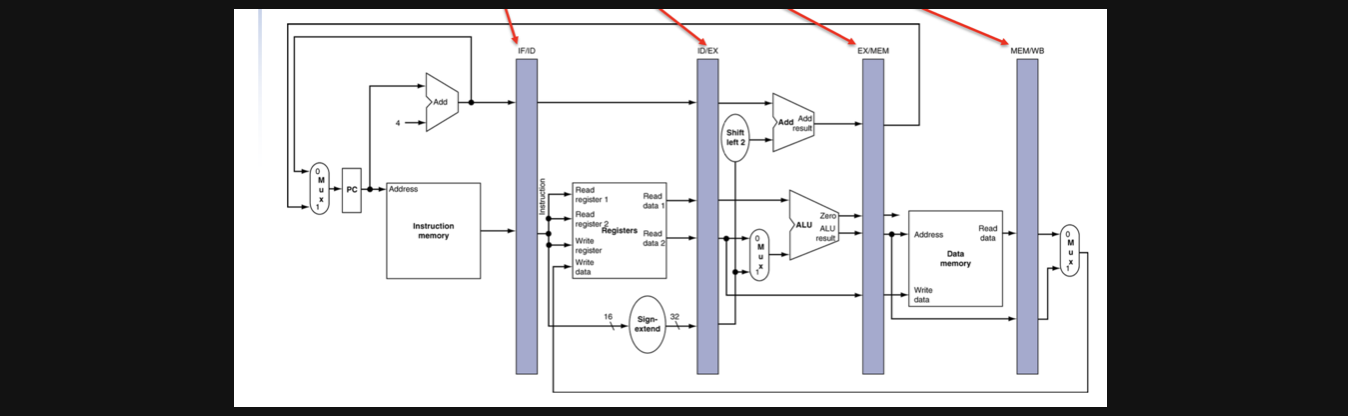
그림에 화살표로 지정된 부분이 pipline register입니다
보면 이름이 IF/ID 혹은 ID/EX이런식으로 되어있는데 IF와 ID사이에있는 pipline register라는 뜻입니다
그리고 결국 pipeline register의 목적은 cycle의 결과를 저장하는것이기때문에 write signal은 항상 1이겠죠
Multi-Cycle Pipline Diagram
본격적으로 pipeline을 적용한 회로가 어떻게 작동하는지 step by step으로 알아봅시다
우선 아래그림이 실제로 pipelining을 적용한 회로가 동작하는 그림을 나타낸건데요
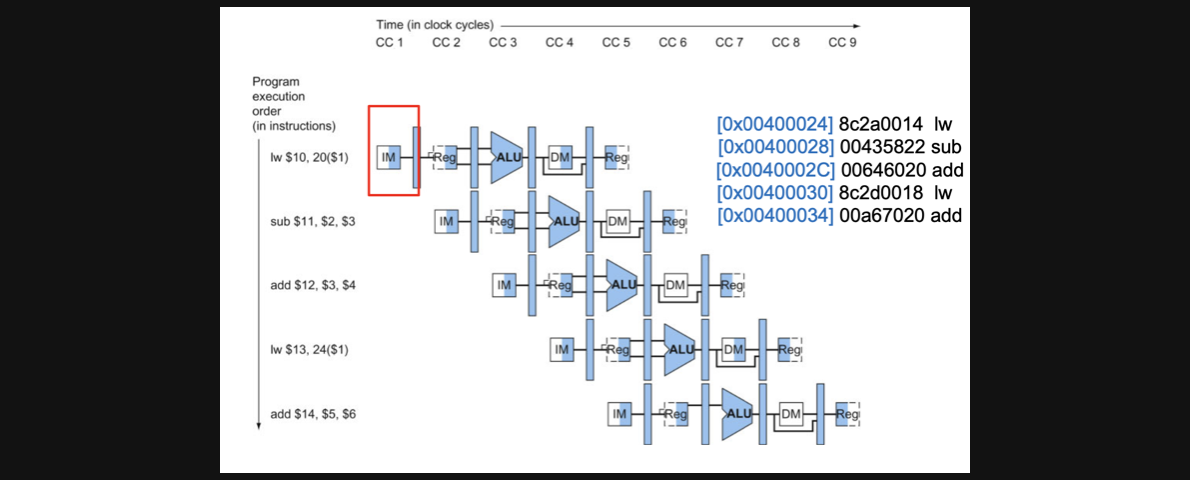
왼쪽에 있는 5개의 instruction을 수행하는 회로를 나타내고 있습니다
위에있는 CC라는건 clock cycle의 약자입니다
주의해서 봐야할점은 실제 회로는 1개라는점입니다
회로가 5개 그려져있는건 여러시간대의 회로를 보여주기 위해서 이렇게 표현을 했습니다
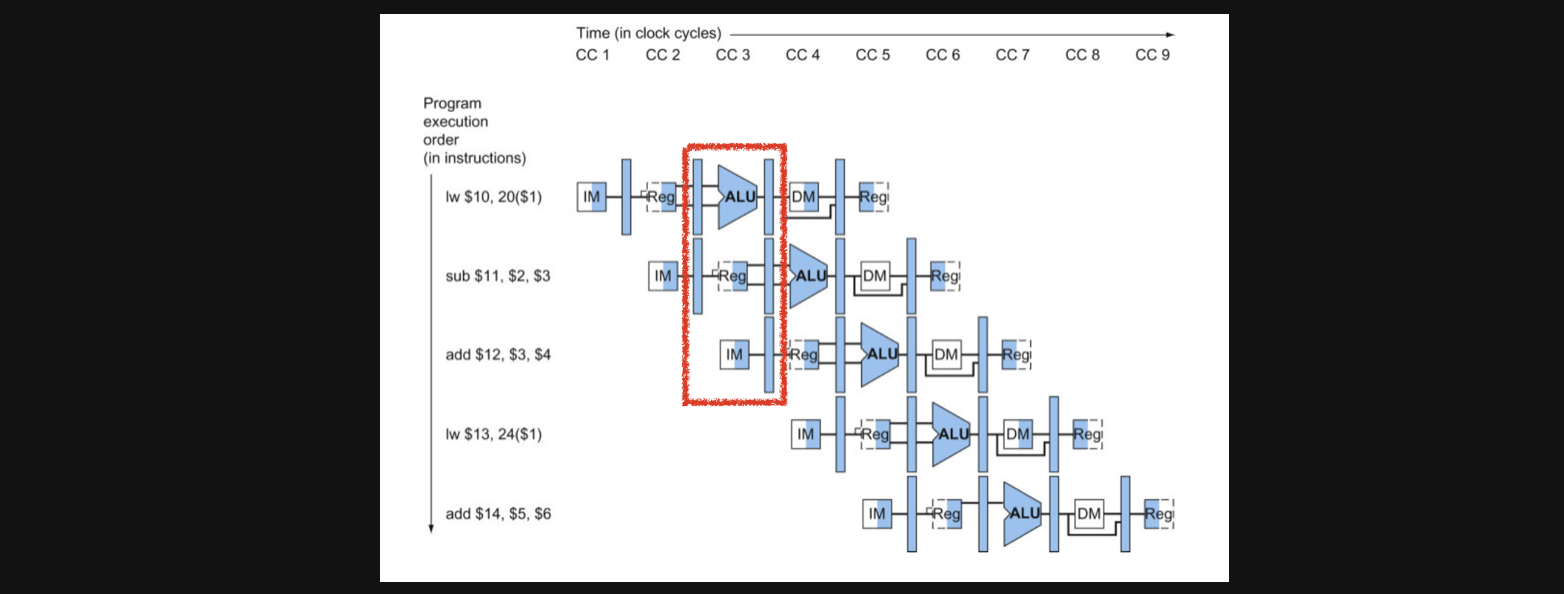
조금 이해가 안되실수도 있어서 빨간색 네모를 가지고 부연설명을 해보자면
CC3에서 lw의 EX sub-task와 sub의 ID sub-task와 add의 IF sub-task가 하나의 회로에서 동시에 실행되고 있다는 뜻입니다
조금더 자세히 보겠습니다
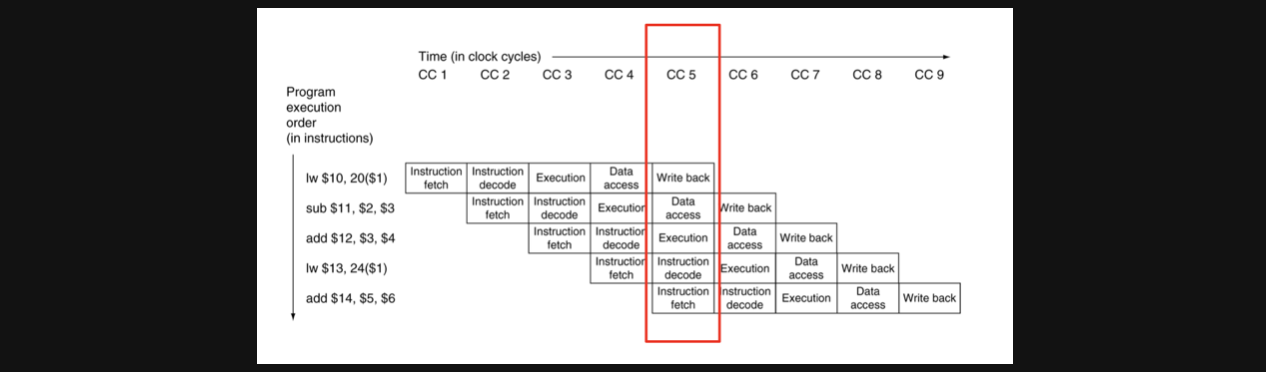
CC5 의 경우엔 lw는 최종 data를 return해주는 WB을 수행하고 sub는 MEM을 수행하고 add는 EX를 수행하고 두번째 lw는 ID를 수행하고 add는 IF를 수행합니다
CC5를 수행할때의 회로의 전체적인 그림도 한번 보고 가겠습니다
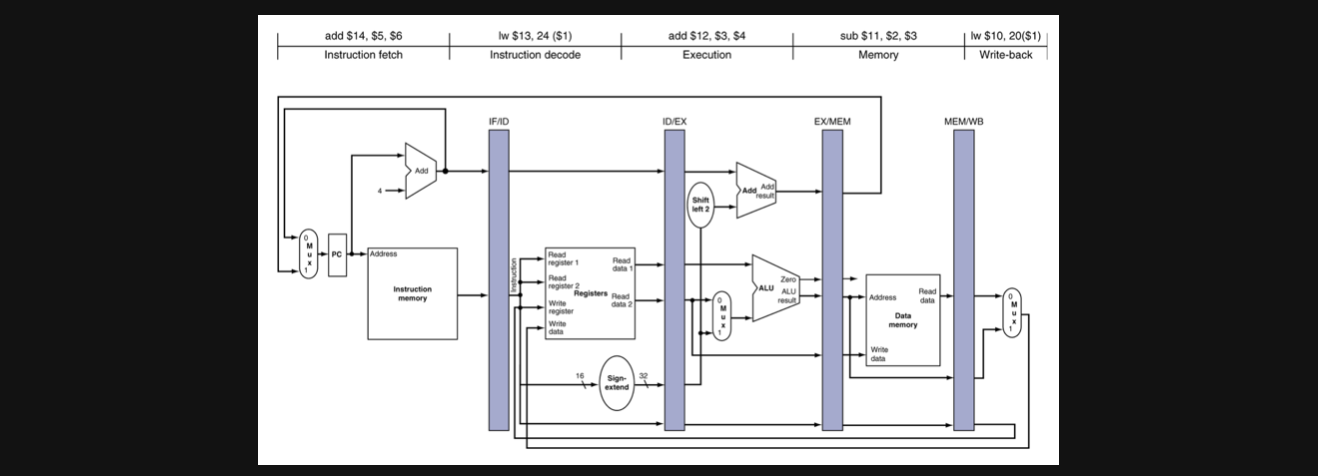
각 연산이 어떤 sub-task에 실행되는지 확인해보면 좋을거같습니다
Cycle Time of Pipeline Processor
실제로 우리가 CC의 길이를 정했을때 기존 single cycle과 pipeline방식이 어떤 차이가 생기는지를 한번 보고 넘어가면 좋을거같습니다

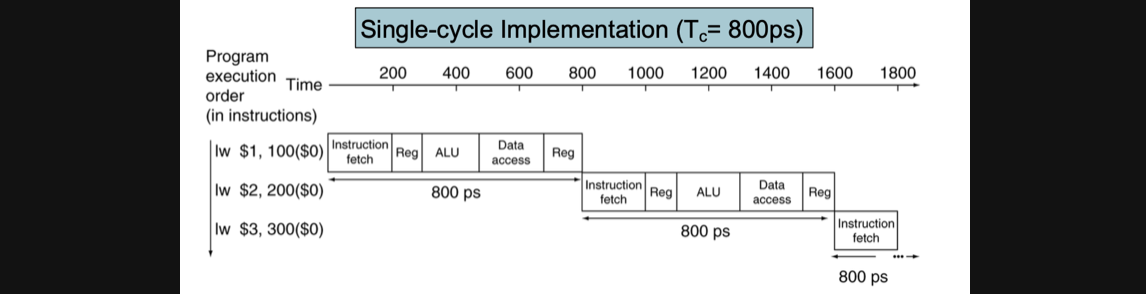
우리는 이중에서 lw instruction을 총 3번 수행한다고 해보겠습니다
CC의 길이는 하나로 고정해야하니 lw의 경우 800ps가 걸리고 lw연산만 수행하면 되니까 3번수행하면 아래와같은 time table로 표현이 가능해집니다
만약에 pipelining을 하게되면 어떨까요 한 cycle의 길이는 최소 200으로 해야할겁니다 lw연산을 수행하기 위해서는 6번의 cycle이 필요한데 그중에서 가장 긴 sub-task가 200이 걸리니까요
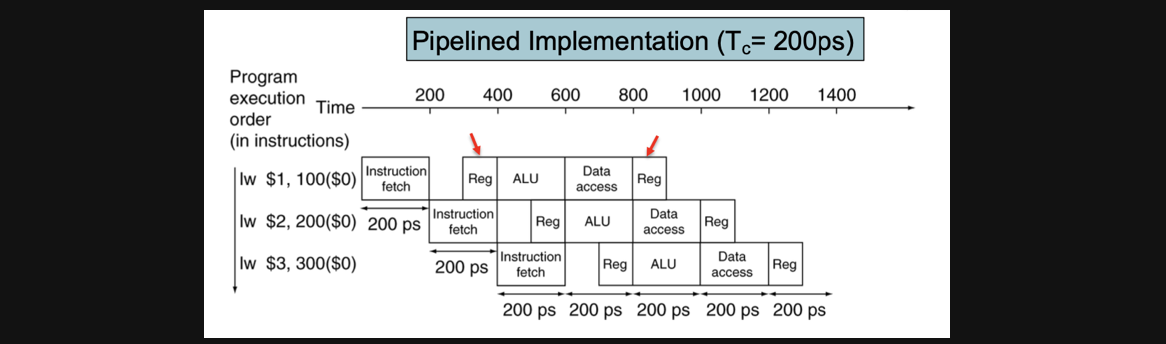
여기서 주의해서 봐야할부분이 CC의 길이가 200인데 100길이의 task는 어떻게 처리를 했는지인데 100만큼 걸리는 task는 register를 read하거나 write하는 부분입니다
그래서 read하는건 오른쪽으로 붙이고 write하는건 왼쪽으로 붙인다고 합니다
Pipeline Diagram분석하기
아래와같은 Diagram이 있다고 가정해봅시다
이제부턴 이전에 배웠던 processor개념을 가지고 쭉 분석해보겠습니다
Instruction Fetch in lw instruction at CC1
우선 CC1에서는 lw연산의 instruction fetch가 수행됩니다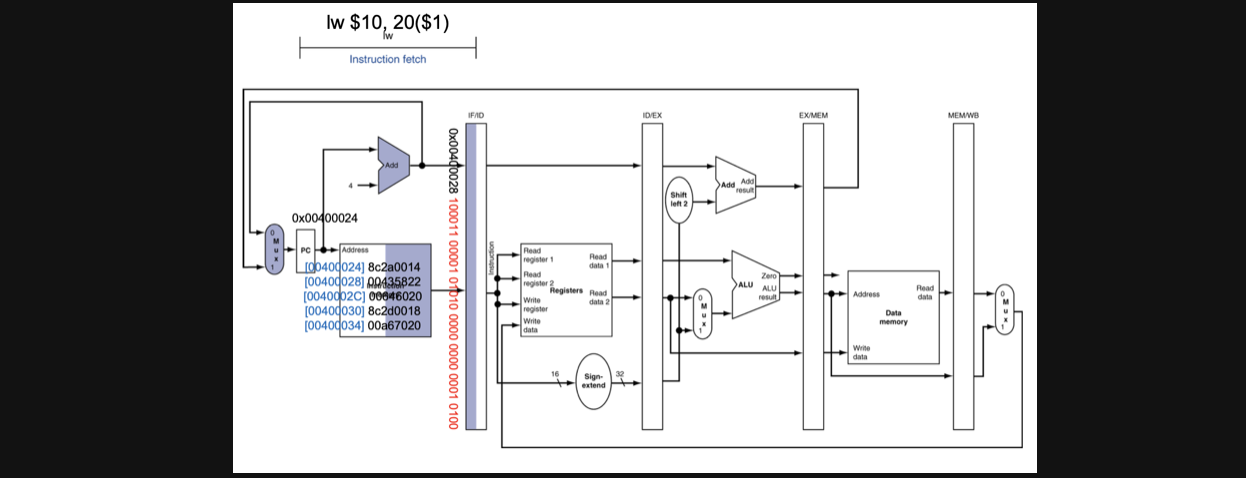
그렇게 되면 연산의 결과인 instruction이 IF/ID register에 저장되게 됩니다 또한 다음 pc주소도 저장되게 됩니다
쓰일지 안쓰일지 모르겠지만 연산은 전부다합니다 연산을 쓸지말지는 control이 결정하는거지 회로가 결정하는게 아니기 때문입니다
만약에 쓰인다면 pc주소를 가지고 어떤 연산을할떄(BTA를 구할때) 쓰이겠죠?
이렇게 되면 CC1이 끝나게됩니다
CC2
CC2에서는 아래 그림과같은 연산이 수행되게됩니다
lw연산의 ID연산과 sub연산의 IF연산이 동시에 수행됩니다
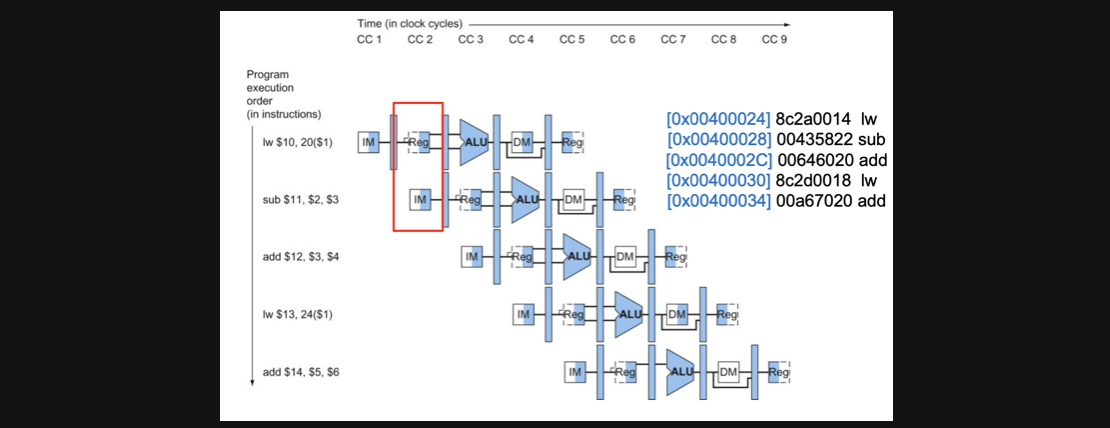
다음 CC부터는 회로에 관한 사진으로만 설명하겠습니다 각 CC별로 instruction마다 어떤 연산이 수행되는지는 스크롤을 조금 올려서 확인해주세요😉
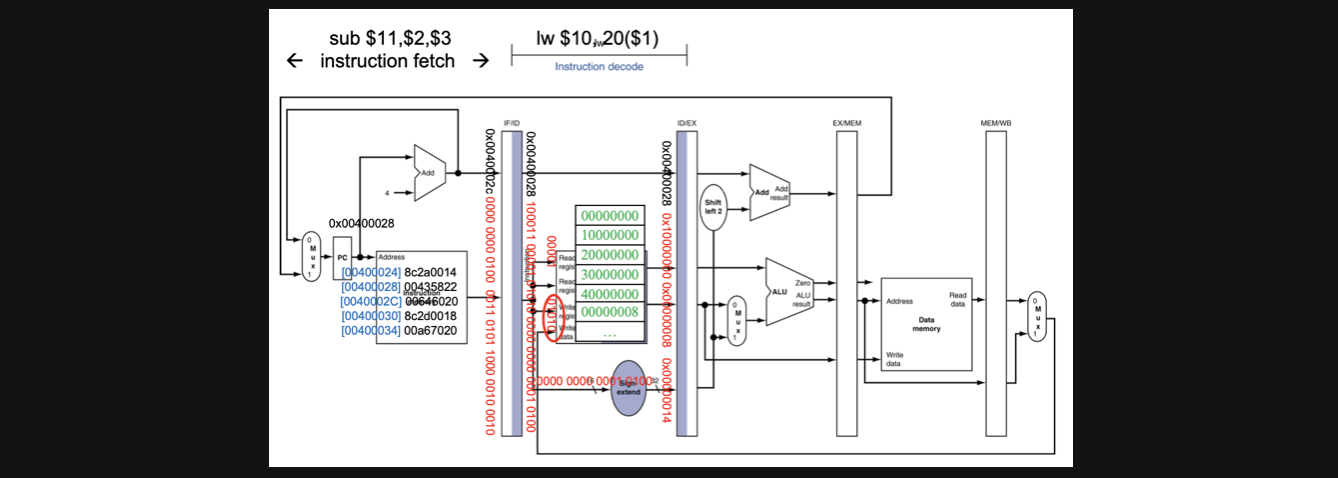
자 이렇게 CC2가 되면 수행과 동시에 IF/ID에 저장되어있던 lw의 IF결과가 load되어서 ID를 수행하게됩니다 그리고 sub의 IF가 수행되어서 IF/ID에 연산결과가 저장됩니다
여기서 알 수 있는건 다음 cycle이 되는순간 이전 cycle의 결과가 사라진다는 점입니다
(이부분은 나중에 문제가 발생하고 새로운 해결방법이 필요하게 되는 포인트이기때문에 주의깊게 봐주세요)
이게 무슨 말인지를 한번 설명드리고 가자면 우리가 lw연산의 경우엔 10번 register에 값을 저장하라고 명령을 하죠? 그래서 register에 destination register로 10을 write하지만 실제 lw연산의 결과는 CC5에 결정되는데 그러면 CC5때는 다른 연산의 IF의 결과에 따라서 destination register의 갚으로 덮어씌워지게 됩니다
막상 lw의 결과를 가지고 register에 넣어줬는데 destination register의 값이 다른 연산에 의해 엉뚱한곳에 저장될 가능성이 생기게 되는거죠
해결방법은 추후에 알아보기로 하고 우선 이런 문제가 생길수도 있다 정도로 알고 넘어갑시다😀
CC3
CC3입니다 이번에는 lw연산의 EX와 sub의 ID 그리고 add의 IF가 동시에 일어나게됩니다
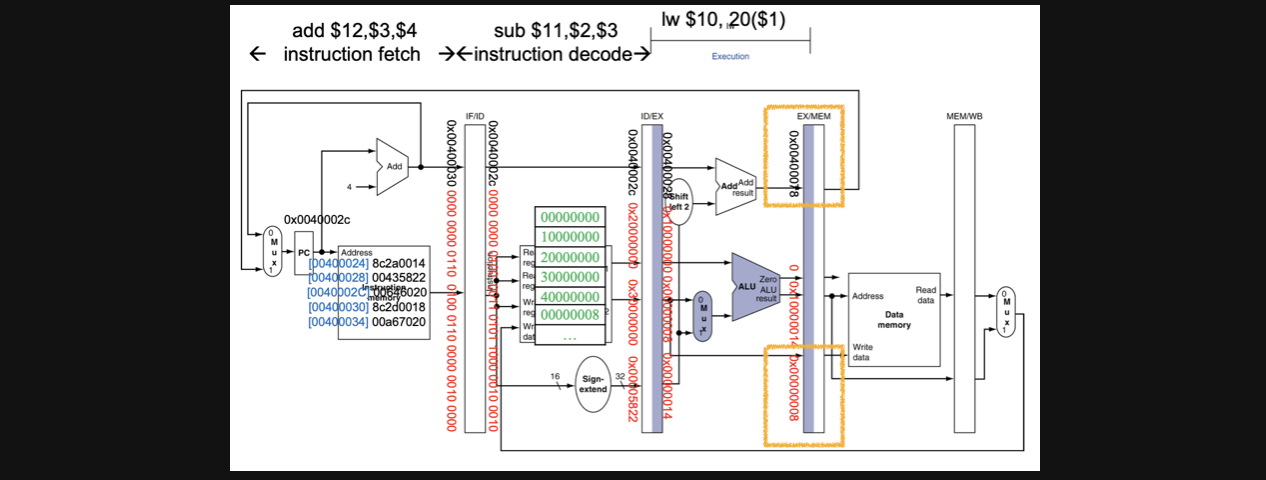
CC2에서 말했던걸 보면 우리는 lw연산의 결과를 $10에 저장하고 싶은데 이미 sub instruction에 의해서 destination register가 바뀌어버린걸 확인하실수있습니다
그리고 주황색 박스를 한번 봅시다
위의 주황색박스에는 0x00400078이라는 data가 저장되는데 사실 lw에서 메모리주소를 계산할때 pc주소의 값을 필요가 없죠 하지만 쓸지말지는 control이 정하는것이기때문에 data path는 모든 연산을 다해준다고 이해하시면 됩니다
아래 주황색박스에는 0x0000008이라는 값이 있는데 이건 read data2로부터 온 값입니다 lw에서는 필요없지만 어떤 instruction에서 이값이 필요할까요????
바로 sw에서는 이 값이 필요합니다 이값을 store해줘야하니까요
CC5
CC4는 똑같아서 넘어갔습니다
전체적인 CC5를 보기전에 lw관점에서 먼저 보고 넘어가보겠습니다
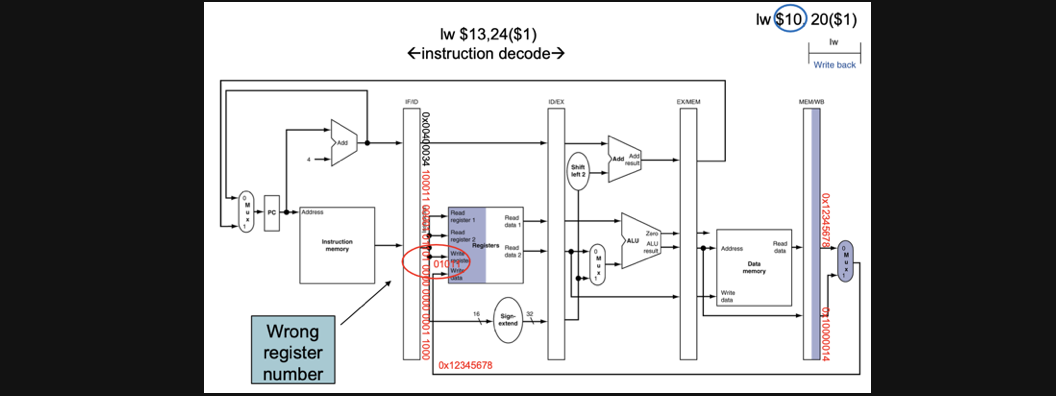
보면 분명히 최종 연산의 결과인 0x12345678이라는 값을 $10에 넣고 싶고 10은 이진수로는 1010인데 data를 write하려고 보니까 지금 register에는 01011이라는 register가 destination register로 설정이 되어있습니다
아무런 조치를 취하지 않으면 $10이아니라 $11에 lw instruction의 결과가 저장되게 됩니다
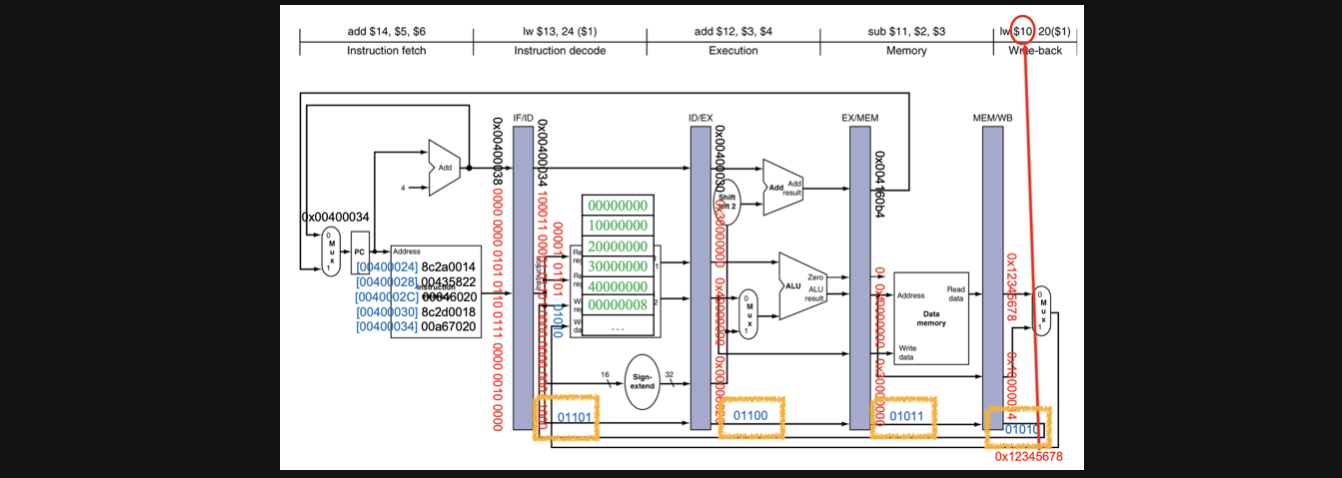
그래서 나온 방식이 pipeline register에 destination register의 번호를 매번 저장하고 load하는겁니다 그렇게 되면 각 cycle이 끝나더라고 각 task의 destination register를 기억하고 사용할 수 있게됩니다
adding RegDst MUX
저번포스팅에서 이런이야기를 한적이 있습니다
destination register는 rt가 될수도 rd가 될수도있다
어떤 연산은 rd가 instruction에 있지만 어떤 연산은 rt가 그 역할을 대신할때가 있습니다
그래서 multipler를 넣어주면서 전체적인 회로를 완성시켰었는데요
해당 정보도 pipeline register에 넣어줘야합니다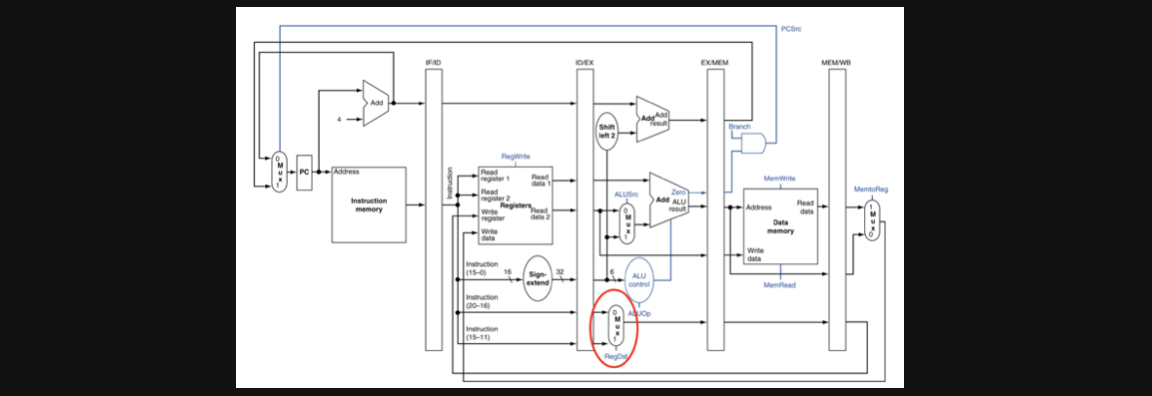
muptipler의 control input에 따라서 rt와 rd 둘중 하나가 destination register가 되는 방식이 추가됩니다
이렇게 해서 여러개의 instruction을 수행할때 Pipeline 방식으로 어떻게 수행되는지 수행하는 도중에 발생하는 문제는 어떤방식으로 해결하는지를 알아봤습니다
Pipelined Control
저번포스팅에서처럼 회로에서 Control이 결정해주는 부분을 전체적으로 보고 넘어가겠습니다
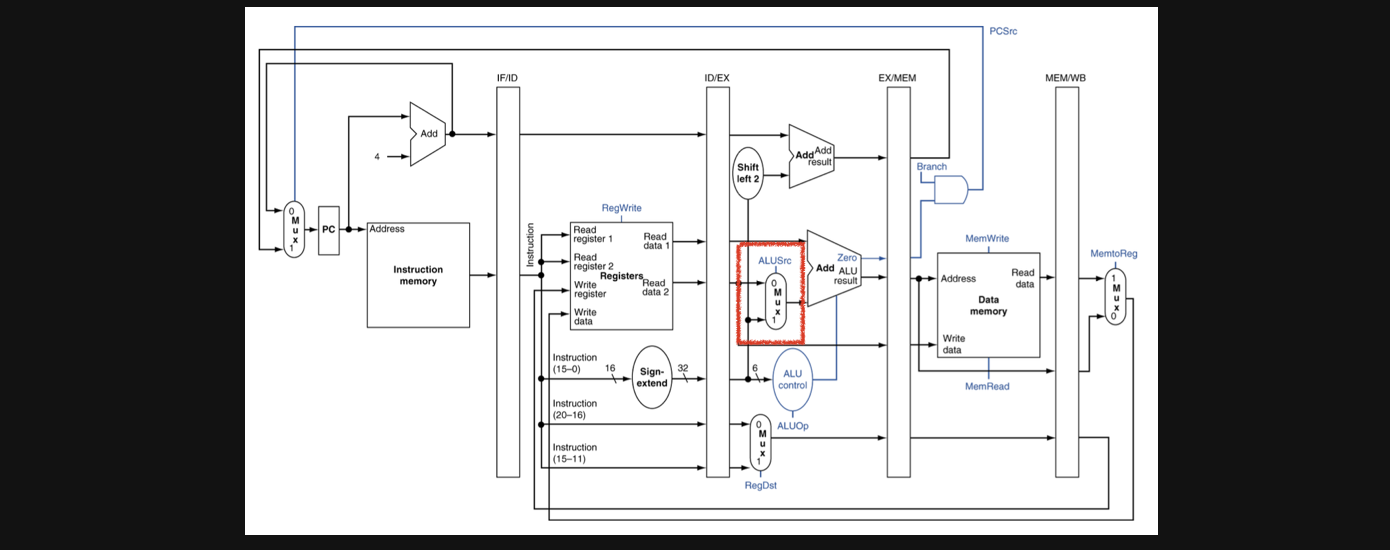
여기서 봐야할 부분이 ALU에서 두번째 operand로 들어갈 input이 offset인지 register의 data인지를 정해주는 Multipler의 control input입니다. 사진에선 빨간색 네모부분입니다
자 한번 여기서 고민을 해봐야할 부분이 있습니다
우리가 저 multipler의 control input은 어디서 결정될까요???
아마도 op field의 값을 가지고 control input을 결정하는 ID부분일겁니다 만약 지금이 CC3이라면 CC2에서 결정된 값을 CC3에서 사용해야합니다
앞으로 이전 op field의 값을 가지고 쭉 control input이 결정되어야하는데 pipeline을 사용하면 CC가 넘어가면 이전 값들을 다른 instruction이 덮는다는 문제점이 발생했었죠(destination register문제)
여기서도 마찬가지입니다 그래서 pipeline register가 control input도 저장해야할 필요성이 생기게됩니다
중요한 포인트는 각 sub-task마다 사용하는 control input이 정해져있다는겁니다
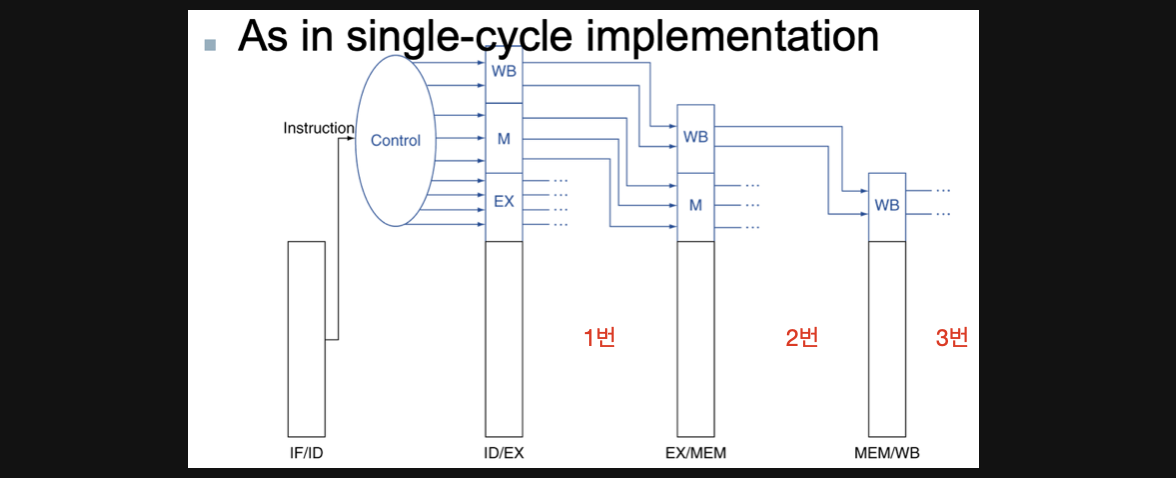
예를들어서 우리가 control에 input을 넣으면 output으로 WB에서 사용할 control input과 M에서 사용할 Controle input 그리고 EX에서 사용할 control input이 결정됩니다
그래서 1번영역에서 EX control input이 사용되면 M과 WB만 저장하면되기때문에 다음 pipeline register에는 WB와 M의 control input만 저장하면됩니다
2번영역을 지나면 M관련한 control input을 사용했으니 WB관련한 control input만 저장하는겁니다
CC2 에서의 control input
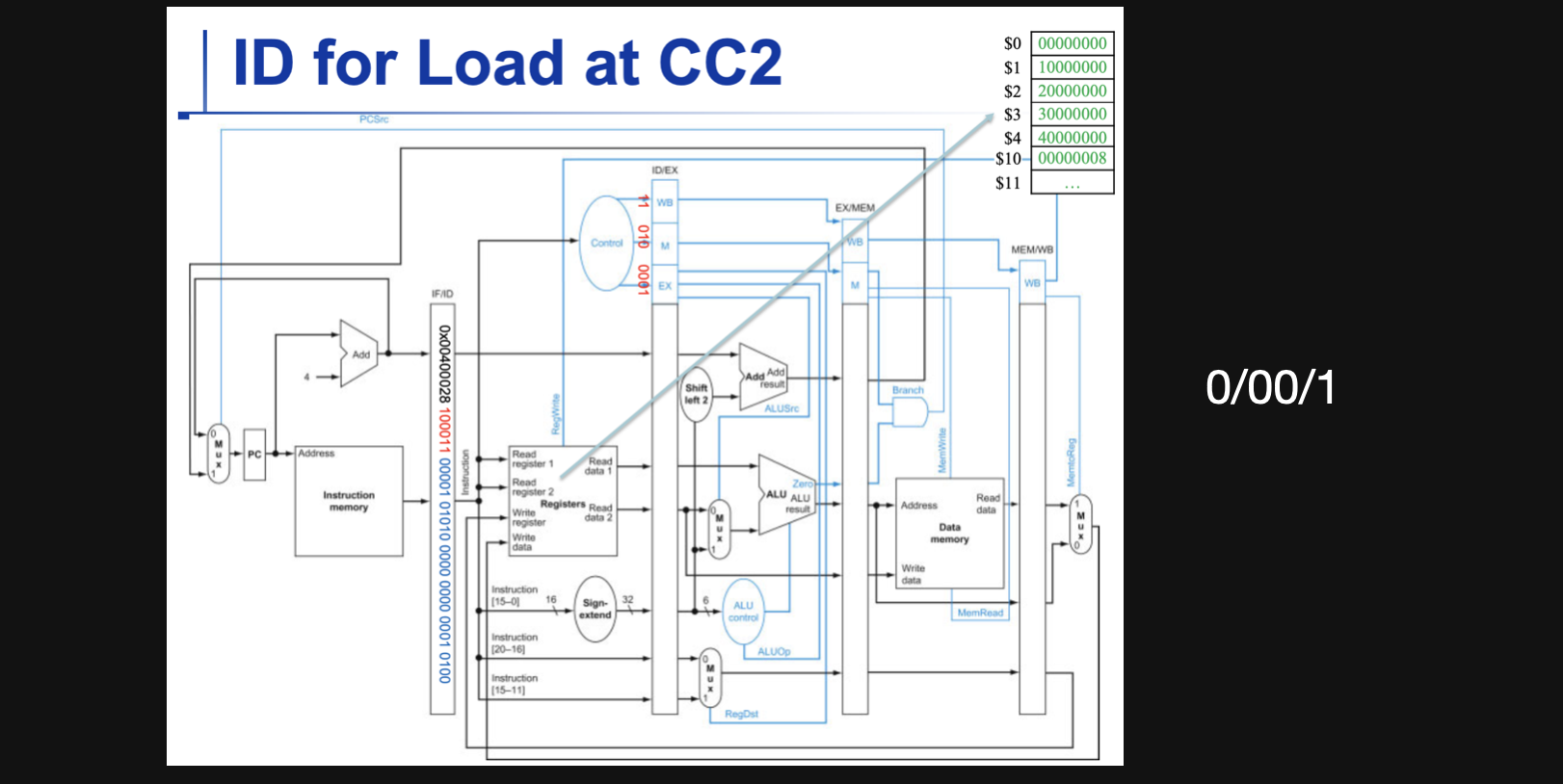
CC2에서의 control input이 쓰이는 곳은 총 세군데입니다
- ALU의 두번째 operand를 결정해주는 control input
- destination register를 결정해주는 control input
- ALU의 operation을 결정해주는 control input
위의 그림에서 Control을 보면 EX영역에 0001이라는 데이터가 들어가있는데
맨앞에 0은 화살표를 따라가보면 destination register를 결정해주는 control input에 들어가고 그 뒤에 00은 ALU의 operation을 결정해주는 control input에 들어가서 add연산이 결정되고 마지막 1은 ALU의 두번째 operand를 결정해주는 control input로 들어가서 두번째 operand로 offset값이 들어오게됩니다
아마도 다른 CC에서의 control input을 따라가 보시면 control이 pipeline의 register에 어떻게 저장되고 불리는지 인과관계를 쉽게 확인하실수있을거같습니다!
이번에는 포스팅이 그렇게 길지 않았을거같았는데 막상 적어보니 기네요... 스압주의...
사실 이전 포스팅의 내용을 잘 따라오셨다면 여기서는 화살표 따라가기와 몇개의 edge case를 어떻게 해결하는지에 대한 방법론을 몇가지 배울수있는 섹션이었다고 생각합니다
다음 포스팅에서는 언급했었던 데이터의 흐름이 반대일경우 문제가발생하는데 이 문제를 해결할 수 있다던 Hazards에 대한 내용을 정리해보도록하겠습니다
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!

학부생인데 컴구수업 들으면서 이해안되는 부분들이 많았는데 쉽게 설명해주셔서 이해가 잘 되네요 좋은 글 써주셔서 감사합니다!!