본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
5주차 컴구의 마지막 포스팅이 돌아왔습니다
이번주에 배울 내용은 Pipeline Hazard에 관한 내용입니다
요즘 매일 7시에 일어나서 하루에 7~8시간은 공부를 꾸준히하려고 하는데 이게 참 쉽지 않네요
벌써 오후 두시인데 몇개밖에 못했네요... 언능 해야겠습니다

얼른 포스팅하고 MVVM공부하러 가야합니다
Pipeline Hazards란?
저번에 우리가 봤던 전체적인 pipeline그림에서 데이터의 흐름이 left to right가 아닌 부분이 몇군데 있었죠?
그런 부분에서 발생하는 문제를 hazard라고 말씀드리고 넘어갔던거같아요
다시 정확하게 Hazard가 뭐냐를 먼저 정확하게 짚고 넘어가볼게요
pipeline processor에서 명령어의 수행이 끝나기 전에 다른 명령어의 수행이 시작되기 때문에 생기는 문제
이게 어떤 의미인지는 지금부터 자세하게 뜯어보겠습니다 씹고뜯고맛보고즐기고
Hazard의 종류
그전에! Hazard의 종류에 대해 알아둘 필요가 있습니다
우선 첫번째로 Structural Hazards인데요
한 cycle동안 여러개의 instruction이 수행되서 생기는 문제를 의미합니다
음... 이게 무슨 소리일까요
예를들어서 우리가 지금까지 봤던 그림에서 메모리가 총 두개가 있었죠
instruction memory와 data memory
만약, 동시에 instruction fetch와 data fetch가 하나의 메모리에서 동시에 일어나면 어떻게 될까요?
어떻게 될지는 모르겠지만 분명 우리가 알던 방식은 instruction을 가져온다음 그 명령을 가지고 data를 사용하기때문에 동시에 일어나는 process가 아니라는것 정도는 알고있고 결국 동시에일어나면 예상치못한 문제들이 발생할거라는 예상을 해볼수 있을겁니다
결국 서로다른 instruction이 같은 resource를 사용하려고하면 conflict가 발생하게 됩니다
그러면 어떻게 해결하나요?!
사실 우리는 항상 이런 문제에 대한 해결방안을 가지고 있는 회로의 모습을 봐왔습니다
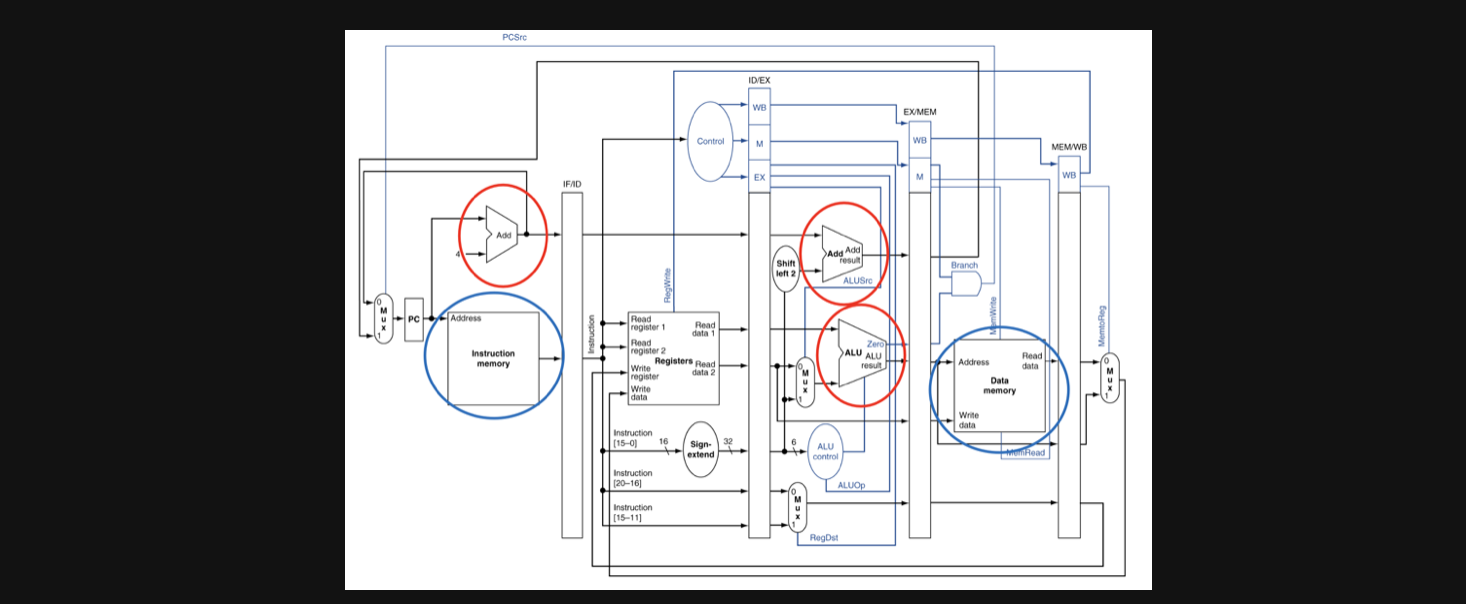
memory를 분리하고 ALU를 분리해서 서로다른 instruction이 같은 resource를 사용하지 않게 설계해온 회로에서 공부를 했습니다
그래서 Structural Hazards는 메모리를 분리하고 ALU회로를 분리함으로써 서로다른 instruction이 같은 resource를 공유하지 않도록 하는구나~ 라고 이해하고 넘어가시면됩니다
두번째는 Data Hazards입니다 이번주 마지막포스팅의 메인 테마이기도하죠
영어로는 이렇게 설명을 하고 있습니다
Need to wait for previous instruction to complete its data read/write
저는 영어를 잘못하지만 해석을 해보면 data를 read하고 write하는것을 완료하기 위해서 이전 instruction을 기다릴 필요가 있습니다라는 의미인데요
이제부터 본격적으로 data hazards에 대해서 알아보겠습니다
세번째인 branch hazard(혹은 control hazard)는 다음시간에 알아보겠습니다
Data Hazard
Dependencies
Data hazard와 한판 붙기 위해서는 알아야할 개념들이 몇 가지 있는데요 그중에서 dependencies라는 개념을 알고있어야합니다
거두절미하고 이게뭔지를 먼저 설명드리면
먼저 수행되는 instruction의 결과가 그보다 나중에 수행되는 instruction의 수행에 영향을 미치는 상황
이렇게 설명을 드릴 수 있습니다
당연히 이렇게만 설명을 들으면 이해가 안되실거기때문에 그림을 보면서 설명드리겠습니다
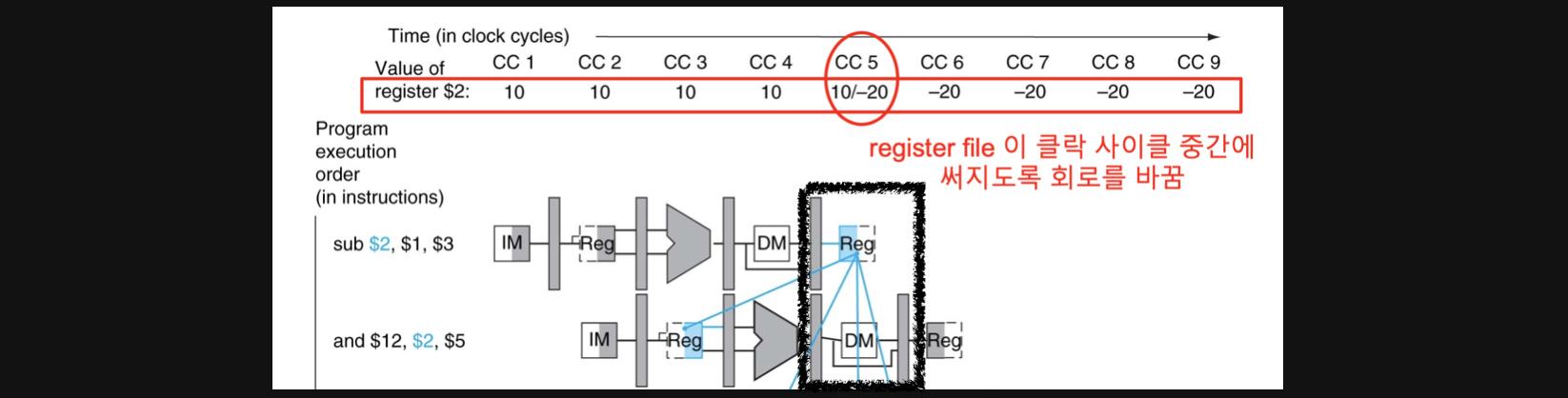
두가지 instruction이 있다고 가정해보겠습니다
sub $2, $1, $3
and $12, $2, $5pipelining으로 두 instruction을 수행하면 위의 그림과 같이 다섯 단계를 거쳐서 수행될거고 각각의 CC마다의 회로의 상황을 그림으로 나타냈습니다
코드에서 우리의 의도를 살펴보면 우선 sub연산을 통해 나온 결과를 $2에 저장하고 $5에 있는 값과 and연산을 하고 싶습니다. 애초에 $2에 sub연산의 결과가 write되어야 and연산이 우리가 원하는 값대로 잘 출력이 될겁니다
그런데 $2에 sub연산의 결과가 저장되는 시점은 그림에서 Reg시점입니다
그림에서 CC5가 sub연산의 결과가 $2에 write되는 시점인데 그때 and연산은 DM시점이죠 이미 register에서 값을 읽어서 and연산을 하고 데이터메모리에 저장할지를 결정하는 연산을 하고 있습니다
조금 헷갈리실수있는데 결론적으로
우리가 어떤 값을 연산해서 register에 넣기전에 이미 그 연산된값을 써야할때 문제가 발생하게됩니다
이 예시에서는 and연산의 경우 CC3에서 register 2번의 sub연산이 완료된 값을 읽어야하는데 이떄 sub연산은 아직 연산만 했을뿐 $2에 데이터를 넣어주지 않은 상황이라 register로부터 정확한 데이터를 얻어올 수가 없습니다
이런 상황을 Data Hazard라고 합니다
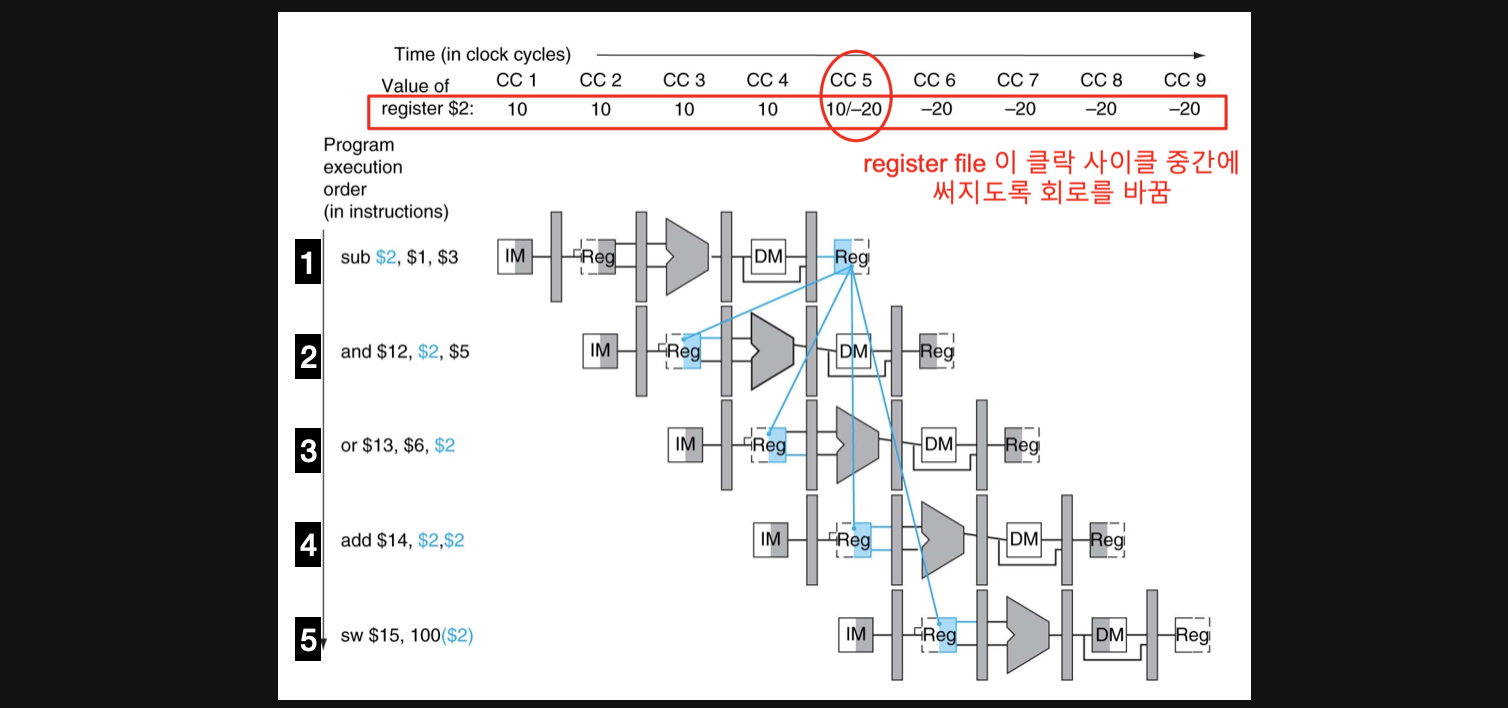
전체적인 그림으로 보겠습니다
1번 연산에서 우리는 연산의 결과를 $2에 넣어줍니다
그리고 2번부터 5번까지의 연산이 모두 이 결과를 가지고 연산을 해야합니다
그렇기때문에 먼저수행되는 instruction(1번)의 결과가 그보다 나중에 수행되는 instruction(2~5번)의 수행에 영향을 미치기 때문에
1과2, 1과3, 1과4, 1과5는 dependency라고 할 수 있습니다
자그러면 dependency상황에서 항상 data hazard가 발생할까요?
CC5에서 $2에 sub연산의 결과가 결정되니까 그 순간의 회로를 보시면
2번 연산은 DM이기때문에 이전의 상황에서 $2를 사용했어야했기때문에 Data hazard가 맞습니다
3번 연산은 ALU연산을 하고있기 때문에 이전의 상황에서 $2를 사용했어야했습니다. 따라서 3번도 Data hazard가 맞습니다
그렇다면 4번은 어떨까요
$2에 데이터가 써지고나서 데이터를 읽어오기때문에 문제가 없습니다
5번도 마찬가지로 $2에 데이터를 넣을때 아직 IM단계이기때문에 추후에 데이터를 읽어오면 되서 문제가 발생하지 않습니다
이렇게 dependency라도 data hazard가 무조건 발생하는것은 아닙니다
그럼 이런 data hazard를 어떻게 해결할까요?
Stall for Data Hazard
방금가져왔던 예시와 비슷한 예제를 가져왔습니다
sub $s0, $t0, $t1
and $t2, $s0, $t3sub연산의 $s0와 and연산의 $s0는 dependency이고 이전 section의 그림을 생각해보시면 data hazard가 발생한다는걸 어렵지않게 떠올리실수있을겁니다
이럴때 가장 먼저 떠오르는 방식은 and연산을 살짝 멈춰놓는거죠
and연산의 register를 읽어오는 시점이 sub연산이 $s0에 데이터를 입력하는 시점이 되도록
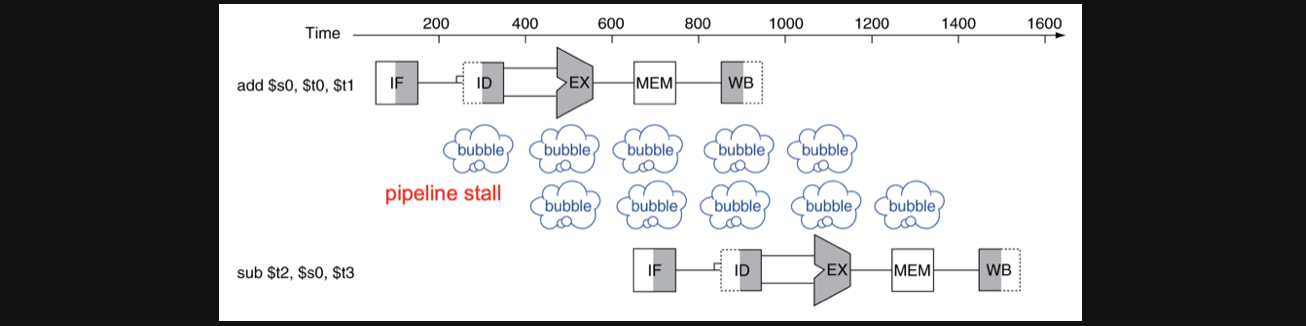
이런 방식을 우리는 Stall이라고 부릅니다
하지만 엄청나게 좋은 방식은 아닐수있다라는 직감이 빡 오실겁니다 저기 보이는 bubble이라는 빈 시간이 존재하게되니까 전체적인 처리속도가 느려지는 단점이 존재하겠죠
그래서 나온 새로운 해결방식이 Forwarding입니다
Forwarding(aka Bypassing)
Data hazard를 해결할수있는 방법으로 Stall을 알아봤습니다
가장 단순하고 직관적인 방법이지만 단점도 존재하는 방식이었습니다
이번엔 Forwarding이라는 방식에 대해 알아보겠습니다
Data hazard를 해결하는 가장 보편적인 방식이라는 소개로 시작해보겠습니다
어떤 아이디어로부터 온 방법인지를 들으시면 아마 바로 아~이런방식이겠구나 라고 느끼실수있을거예요
sub연산에서 실제로 데이터를 $2에 넣는 시점은 WB지만 실제 값이 결정되는 시점은 언제일까요?
바로 실제 연산을 하는 EX시점입니다 그러면 그 값을 그냥 사용하기만 하면 register에 있는 값을 사용하지 않아도 같은 결과를 얻을수있게 되는겁니다
이게 무슨소리냐
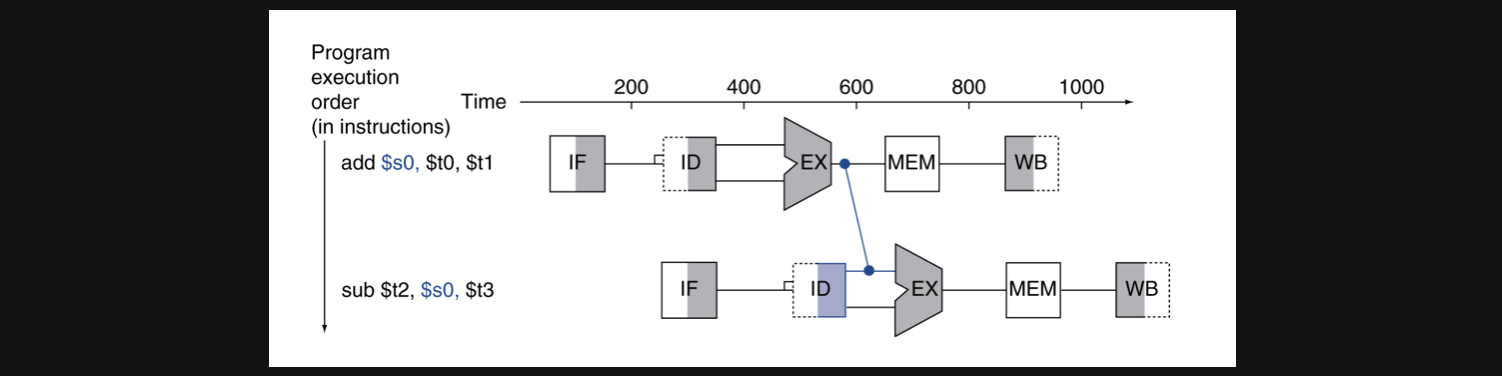
여기 그림에서는 add연산이 먼저나오네요
add연산의 결과를 WB에서 register에 저장하는 시점이 sub연산이 register에 있는 값을 쓰려는 시점보다 뒤에있어서 이런문제가 발생했는데 애초에 register에 들어가려는 값은 EX에서 결정이 되잖아요?
그러면 그 값을 쓰면 같은 CC에서 사용할 수 있으니까 이런 Data hazard문제를 해결할 수 있게되는겁니다
즉 add연산의 ALU연산의 output자체가 같은 CC에서 sub연산의 ALU연산의 operand이 되는거죠
ALU연산에서의 operand는 instruction으로부터의 register번호일수도있고 sign extension된값일수도있었는데 여기에 이전 instruction의 연산결과가 될수도있어진겁니다
물론 이 셋중에 어떤 data를 operand로 할지는 multipler가 결정을하면 되겠죠
Data Hazards in ALU Instructions
실제 예시를 보면서 forwarding에 대한 감을 잡아봅시다

연산이 5개나 있는데 sub연산의 결과에 나머지 모든 instruction이 dependency네요...
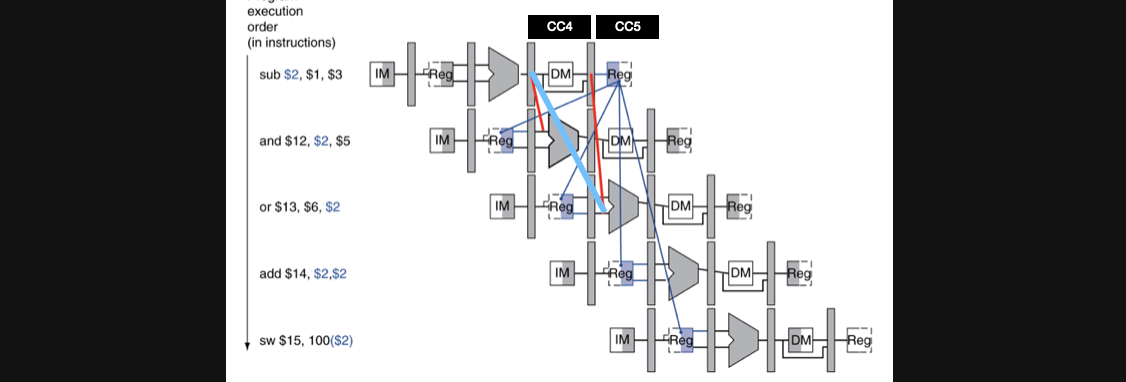
전체적인 CC별 회로의 모습입니다
방금 배웠던걸 토대로 보면 사실 add연산과 sw연산은 dependency긴하지만 data hazard가 발생하지 않기때문에 우리는 and와 or연산만 forwarding을 적용해주면됩니다
우선 CC4를 볼까요
CC4에서는 동시에 and연산의 ALU의 operand로 sub연산의 결과가 필요한 상황이고 이를 ALU연산의 결과를 저장하는 세번째 pipeline register에서 부터 input을 받아오고 있습니다 이게 가능한 이유는 sub연산의 결과를 pipeline에 저장하는 시점과 and 연산이 세번째 pipeline register를 읽어오는 시점이 같은 Cycle이기 때문입니다
CC5를 보겠습니다
CC5에서는 or연산의 ALU operand를 forwarding을 통해서 받아와야하는데요
파란색 선처럼 sub연산의 세번쨰 pipeline register에서 값을 읽어올 수 있을까요?
여기서 좀 헷갈리실수있을거같은데 CC5가 된 순간 이미 세번째 pipeline register에 들어있는 data는 and연산의 instruction decode data로 바뀌어져있습니다
그렇기 때문에 파란색처럼 데이터의 흐름을 가져갈 수 없습니다
대신 결국 pipeline register의 값은 매번 다음 pipeline register로 옮겨지기 때문에 CC5인 순간 sub연산 결과를 저장하고 있는 네번쨰 pipeline register에서 값을 가져오는 방식으로 forwarding을 진행해야합니다
즉, 데이터를 받아오는 pipeline register는 다르지만 같은 데이터를 읽어오는 과정입니다
forward은 ALU연산 결과를 직접 받아오거나 Data memory에서의 read된 결과를 직접 받아오는 두가지 방식중 하나로 결정되서 수행되게 됩니다
Detecting the Need to Forward
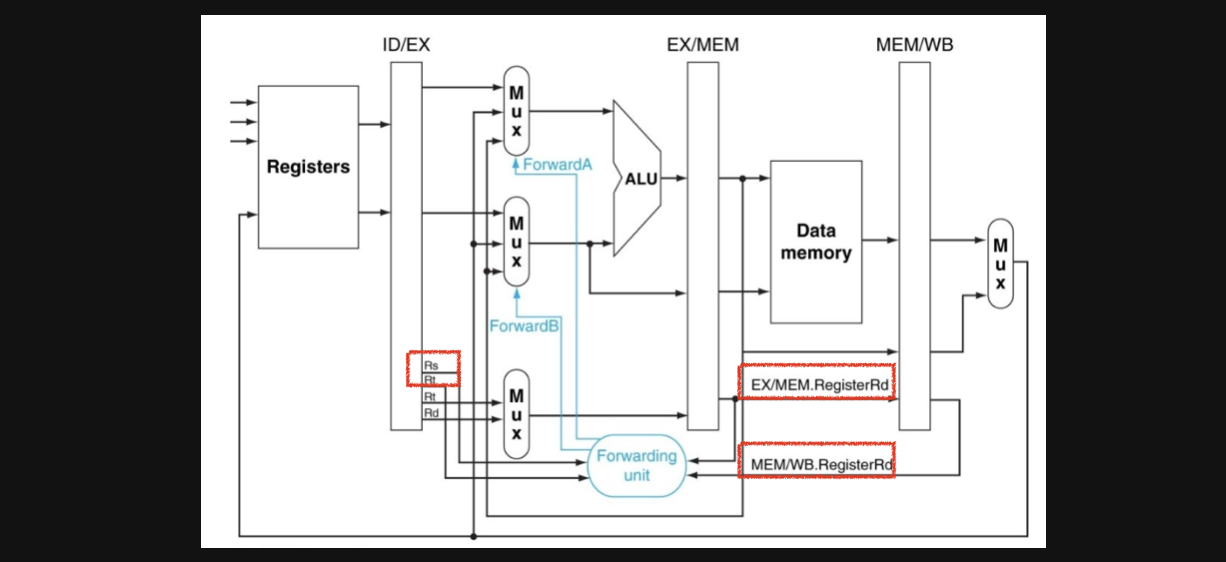
그래서 우리는 forwarding을 할지말지 한다면 첫번째 operand로 넘겨줄지 두번째 operand로 넘겨줄지를 판단하는 forwarding unit을 통해 forwarding을 control하게 됩니다
자 그러면 forwarding unit을 유심히 보겠습니다
output은 단순합니다 ALU의 input으로 forward된 결과를 첫번째 operand에 보낼지 두번째 operand로보낼지를 알려주는 control input을 내보냅니다
그러면 이 unit을 뭘 기준으로 forwardA와 forwardB의 control input을 결정할까요?
빨간색 네모로 표시해둔 부분이 forwarding unit에 input으로 들어가는 요소들입니다
오른쪽 네모들을 보면 EX/MEM이라는 pipeline register의 bit들 중에서 rd레지스터의 번호와 MEM/WB라는 pipeline register의 bit들 중에서 rd레지스터의 번호가 들어가고
왼쪽 네모를 보면 instruction에서 rt와 rs register번호가 들어갑니다 pipeline이름으로 따지면 ID/EX의 rs와 rt의 bit들이 들어가네요
이걸로 어떻게 판단하는지를 한번 생각을 해보면 이렇습니다
ALU에 operand를 결정해야하는데 instruction에서의 rs나 rt의 번호랑 EX/MEM혹은 MEM/WB에서의 rd가 일치한다면 이건 forward가 발생하는 경우인거죠
EX/MEM의 rd와 같다면 ALU연산의 결과가 operand로 들어오는거고 MEM/WB의 rd와 같다면 data memory에서 읽어온 값 자체가 operand로 들어오게되는거죠
첫번째 operand로들어갈지 두번째 operand로 들어갈지는 rd가 rs랑 같은지 rt랑 같은지를 가지고 판단하면되겠네요

방금 주절주절 길게쓴 글을 요약해서 나타내면 이렇게 되겠네요
Forward를 detecting하는데 이정도의 정보를 가지고 판단할수있을까를 생각해보면 몇가지 조건이 더 필요합니다
우리가 보던 회로는 연산은 무조건 다 하지만 control input에 의해서 그 값을 쓸지말지가 결정된다고 배웠습니다
결국 우리가 control input이 1이라면 그 값은 유의미한, 사용할 값이된다는것이고 그것만으로도 어떤 연산인지를 판별할 수있게됩니다
EX/MEM.RegWrite라는 control input과 MEM/WD.RegWrite라는 control input이 있습니다. 이 두가지 control input은 register를 write하겠다는것이고 destination register가 의미있는 연산들을 뜻하게 됩니다
추가적으로 두가지의 control input이 1인지 마지막으로 rd가 0이 아닌지를 판별해주면 forward를 detecting 할수있게됩니다

EX hazard의 경우에는 EX/MEM.RegisterWrite가 1이고 rd가 0이 아니어야하는 조건과 EX/MEM의 rd가 rs와 같은지 rt와 같은지를 판별해서 forward를 진행하게 됩니다
Truth table of Forwarding Unit
앞의 내용을 보고 누군가는 이렇게 물어볼수도 있습니다
Q. EX forwarding일지 MEM forwarding일지 어떻게 아나요?
A. 그 부분을 결정해주는 지표가 EX/MEM.RegWrite 혹은 MEM/WB.RegWrite입니다
forward의 경우 EX/MEM.RegWrite 혹은 MEM/WB.RegWrite 그리고 rd/rs/rt의 input으로 하나의 output이결정되기 combinational 회로라고 볼 수 있고
진리표를 가지고 우리가 output을 확인 할 수 있습니다
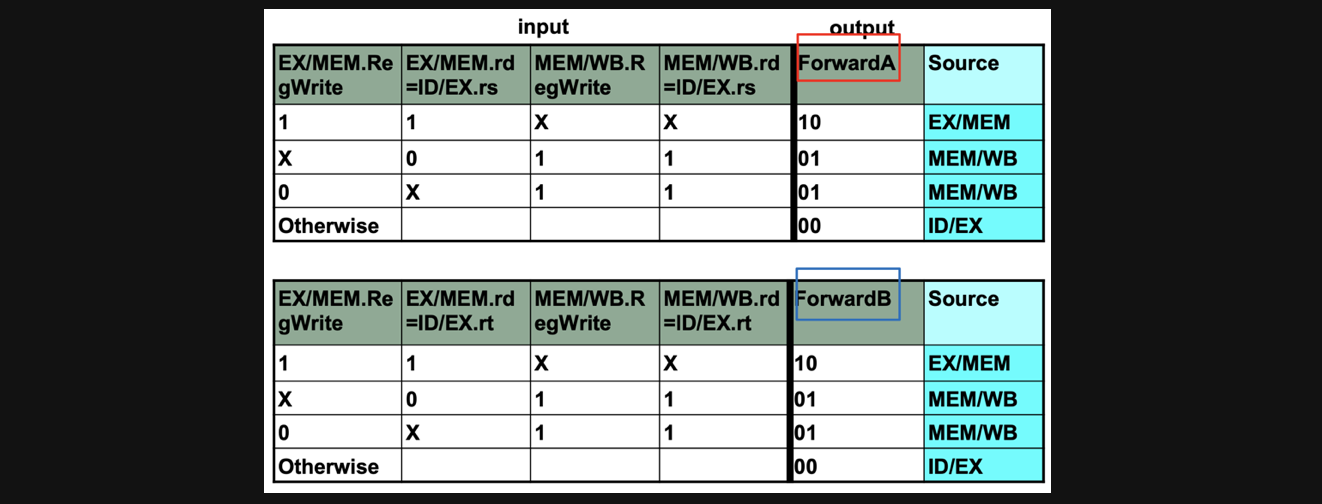
제가 조금 의문이 들었던 부분이 그러면 RegWrite가 둘다 1이면 어떻게되는거지?에 관한 의문이었는데 진리표를 보면 둘다 1이라면 각 pipeline register에 rd와 rs/rt를 비교한 값을 가지고 어떤 Source에서 데이터를 가져오는지가 결정됩니다
Otherwise는 Instruction Decode의 결과로부터 데이터를 읽어옵니다
Double Data Hazard

근데요
WB add $10, $11, $12
MEM and $10, $16, $13
EXE sub $15, $10, $14이런 경우에 맨아래 sub는 add와 and에 전부 dependency가 있는데 이런경우엔 forward를 add에 따라야하나요 and에 따라야하나요...?
라고 물어볼수도 있다고 생각합니다질문폭탄
자 우선 우리 add와 sub의 관계를 볼까요?
1. add연산의 결과가 register에 저장되어야하기때문에 MEM/WB.RegWrite는 1이되어야합니다
2. rd와 rs가 같기때문에 진리표에서 ForwardA는 01이라는걸 알 수 있습니다
결론을 해석해보면 MEM/WB에서 가져온 값을 ALU의 두번째 operand로 넣어주는 forward를 수행합니다
and와 sub의 관계도 마찬가지로 분석할 수 있습니다
1. and연산의 결과가 register에 저장되어야하기때문에 EX/MEM.RegWrite는 1이되어야합니다
2. rd와 rs가 같기때문에 진리표에서 ForwardA는 10이라는걸 알 수 있습니다
그러면 둘중에 어떤 forward연산을 해야하나요...?
sub연산이 add와 and두 연산을 수행하는데 data hazard가 발생하는데 이런경우엔 가까운 forward를 수행해주면 됩니다
sub연산은 and와의 forward인 forard인 10을 수행하주면 됩니다
forwarding example
길고길었던 이론부분은 이정도로 마무리하고 이제 예제를 하나 보겠습니다
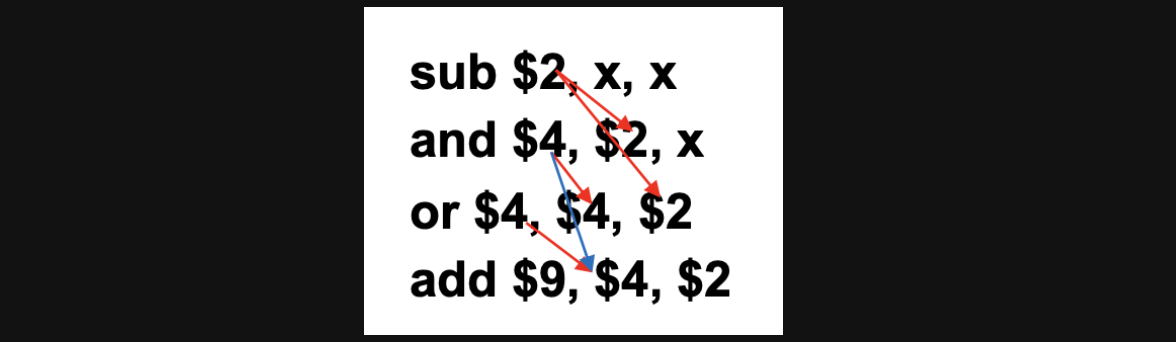
우선 딱 봐도 CC4에서 sub와 and에서 hazard가 발생하겠죠?
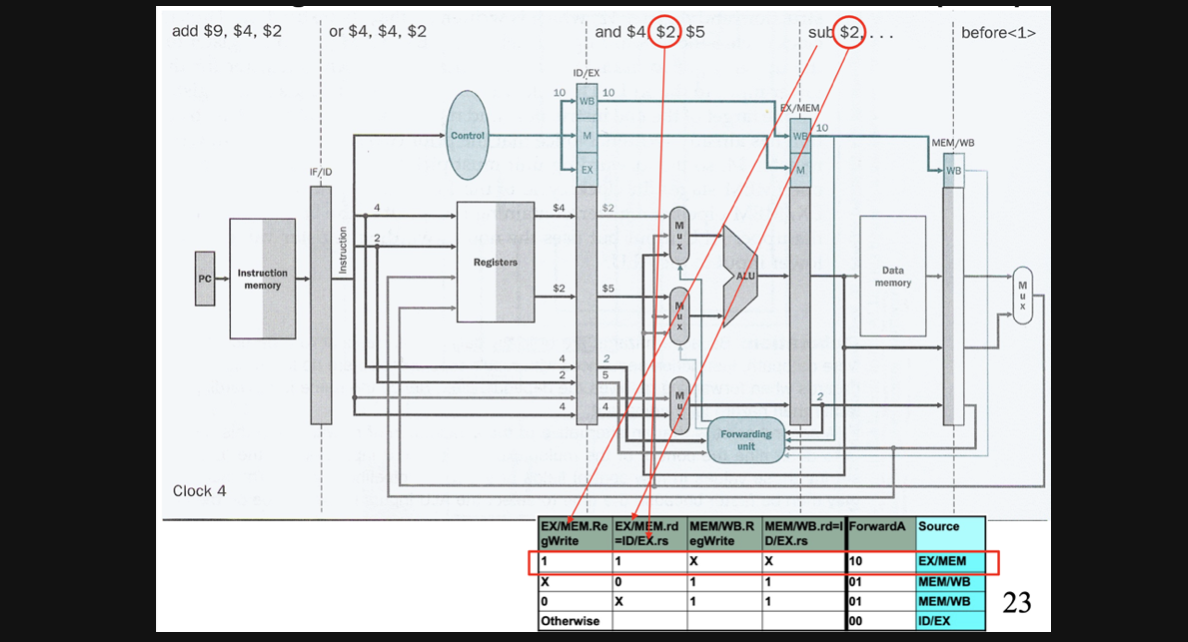
sub연산의 결과가 EX/MEM에 저장이 되어야하기때문에 EX/MEM.RegWrite는 1이 되어야하고 rd와 rs가 같기때문에 ForwardA = 10이 됩니다
CC5로 넘어가보겠습니다
sub연산은 WB에 and연산은 MEM에 or연산은 EXE에 있을겁니다

sub연산과 or연산에 hazard가 발생하고 and연산과 or연산에 hazard가 발생합니다
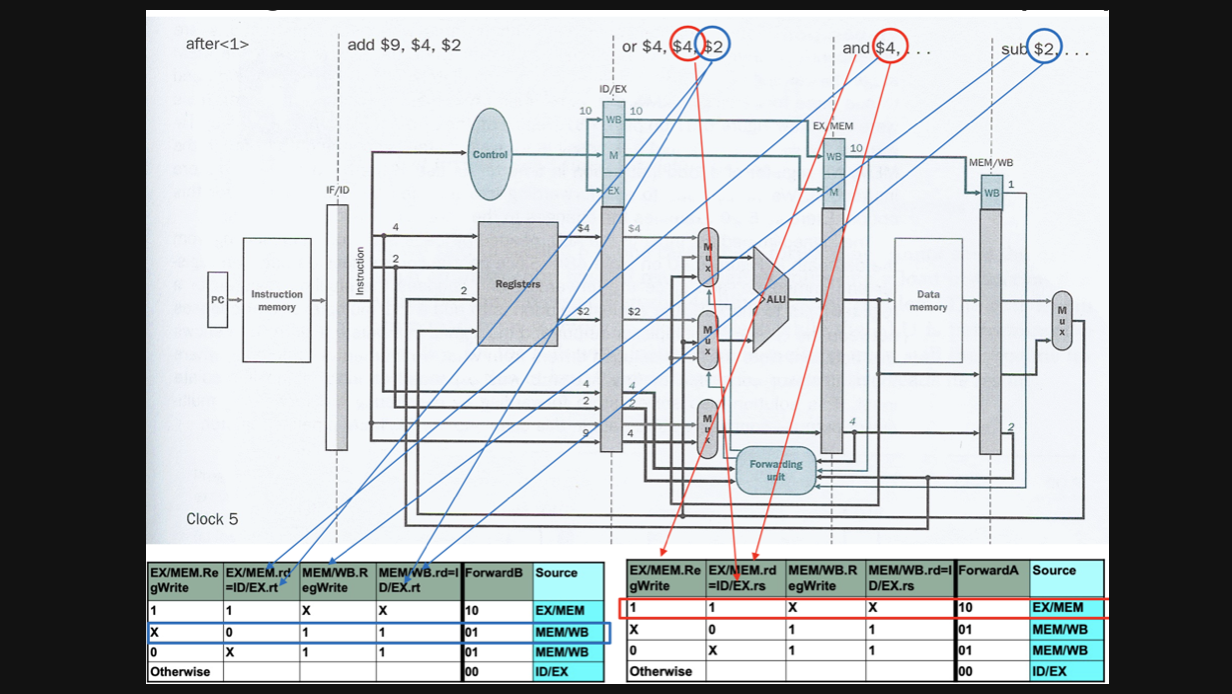
or과 sub를 먼저 보겠습니다
sub의 경우엔 MEM/WB에 register에 값을 저장해야하기때문에 MEM/WB.RegWrite가 1이 됩니다
rd와 rt가 같으니까 ForwardB = 01이 됩니다
and와 or도 동일합니다
and의 경우 EX/MEM register에 값을 저장해야해서 EX/MEM.RegWrite가 1이됩니다
rd와 rs가 같으니까 ForwardA = 10이 됩니다
마지막으로 CC6으로 가보겠습니다
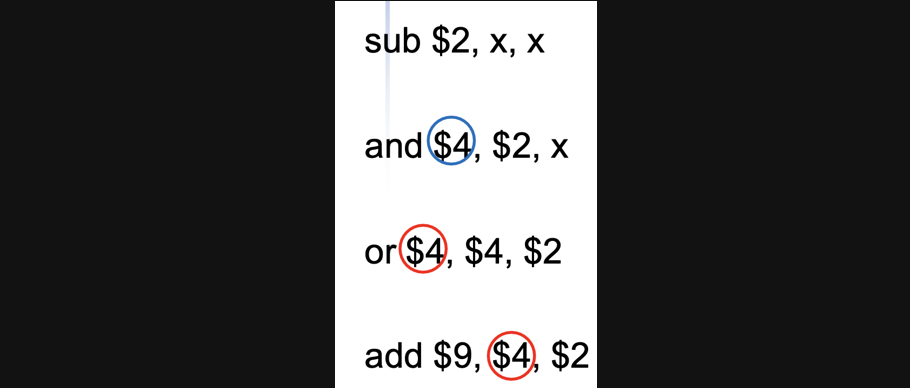
직전에 봤던 예시와 동일합니다 add연산이 and연산과 or연산 모두에 hazard가 발생합니다
이럴때는 가까운 연산과 hazard를 하면되니까 or과 add를 보면됩니다
or연산의 경우엔 데이터를 EX/MEM에 써야하므로 EX/MEM.RegWrite가 1이고 rd와 rs가 같으므로 ForwardA = 10이 됩니다
Load-Use Data Hazard

아니요 아직 안끝났습니다
진짜 마지막으로 한가지 개념이 더 남았습니다ㅎㅎ...
찐막입니다 좀만 힘내세요
사실 위에서 사용했던 방식이 lw에서는 안먹힙니다...

우리가 지금까지 hazard를 사용했던 방식이 유효했던건 결과를 register에 쓰기전에 이미 결과를 같은 cycle에서 사용할수가 있었기 때문입니다
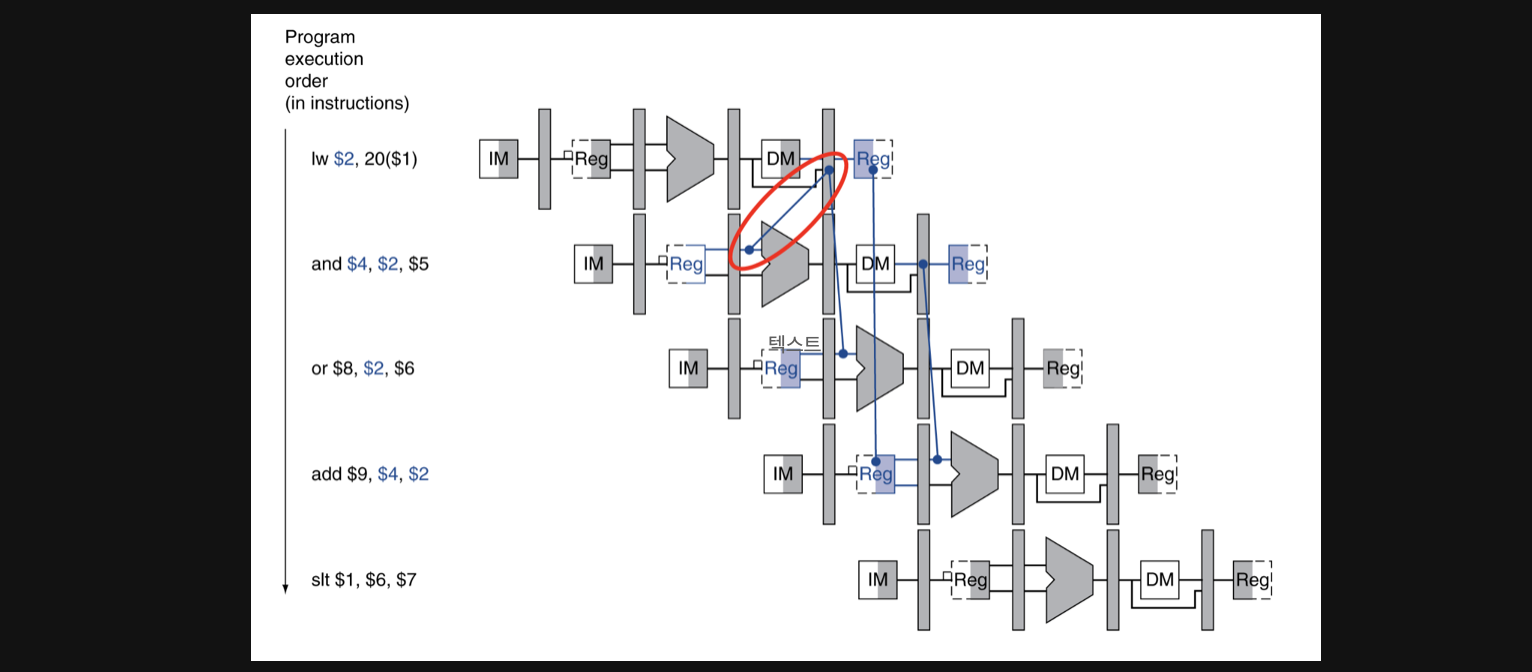
lw연산의 경우 데이터가 register에 write되는 시점은 data memory를 거치고 난 다음입니다
그런데 lw연산의 결과를 바로다음 instruction에서 사용하려고 봤더니
이게 같은cycle(그림에서는 세로축)에 물리적으로 뒤에있게됩니다
lw연산과 and연산이 동시에 실행이 시작되기때문에(lw다음연산이 and라면) lw의 결과는 연산이 끝난후에 나오는데 lw연산이 끝나면 동시에 and연산도 끝나버립니다
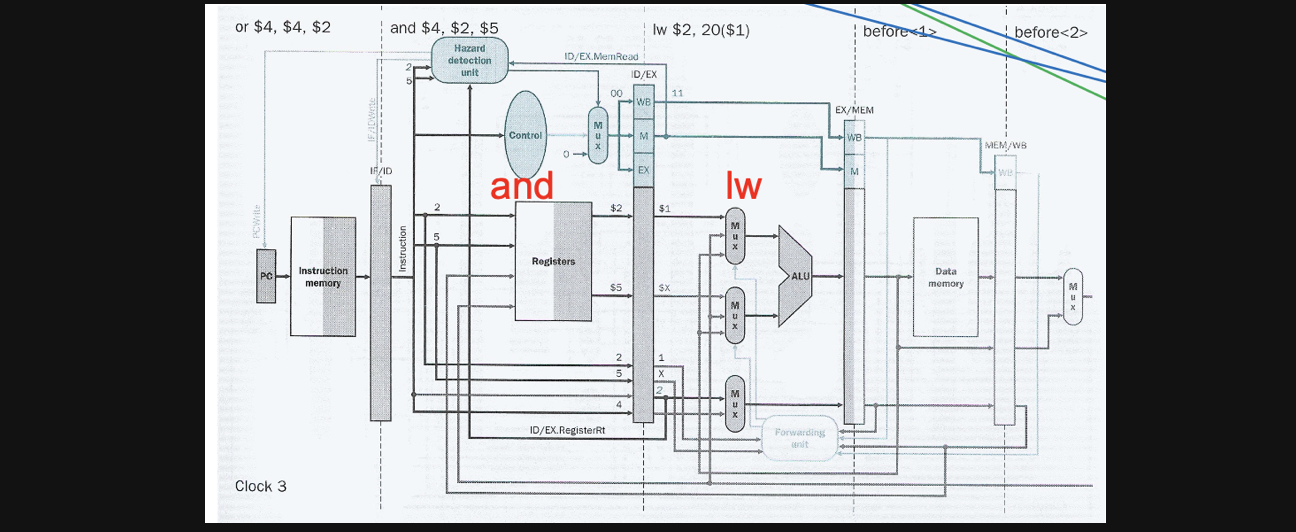
그래서 이런 lw에서의 hazard를 detect하는 방법은
lw의 연산이 ID/EX에 write되는지를 알려주는 control input과
lw의 rt가 IF/ID(and연산의 위치)의 rs나 rt와 같은지를 가지고 확인하면됩니다
이럴땐 어떻게 해야할까요??
어쩔수없이 stall을 통해서 한 cycle을 멈춰줘야합니다
stall을 하는 방법에는 두가지가 있는데요
MemWrite와 MemRead그리고 RegWrite를 전부 0으로 만들어서 강제로 아무것도 안하게 만들거나
이전 instruction을 copy해서 다시 실행하는 방법이 있습니다
그리고 한번의 stall을 하게되면 forward가 가능해져 기존에 배웠던 방식으로 forward를 수행해 hazard를 해결할 수 있게됩니다
Stall은 안좋은 거라고 헀는데 아얘 방지할 방법이 없는건가요...?
물론 Stall은 어쩔수없이 사용해야할때가 있지만 최소한으로 만들 방법은 있습니다
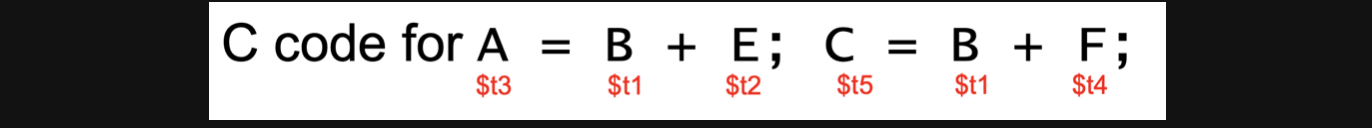
예를들어서 이런코드가 있다면 순서대로 실행한다면
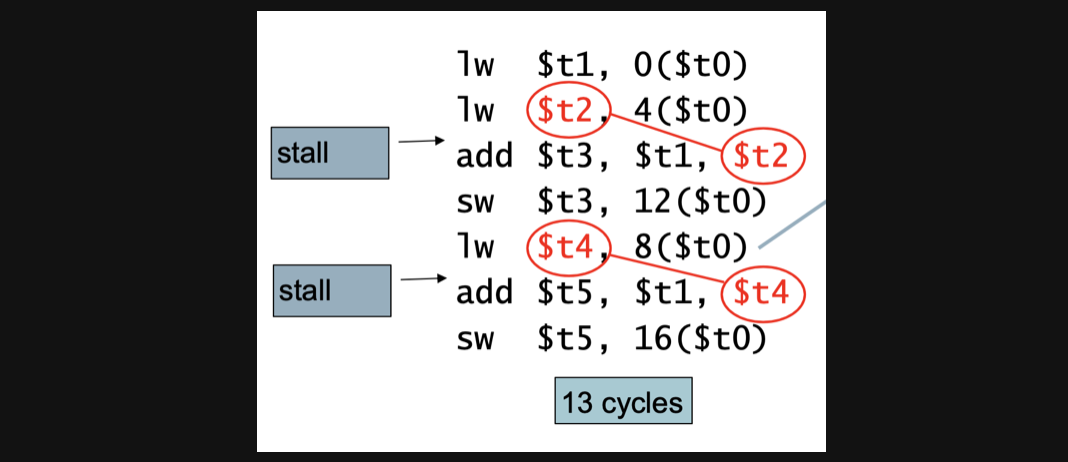
13번의 cycle을 돌아야합니다
1번 instruction을 수행하는데 5, 2번끝나면 6, 근데 2번과 3번은 load use hazard기때문에 stall이 발생해서 8이됩니다. 이렇게 쭉쭉쭉 나가면 13이라는 결론이 나오게됩니다
근데 이 연산에서 순서를 조금만 바꾸면 cycle을 줄일 수 있습니다
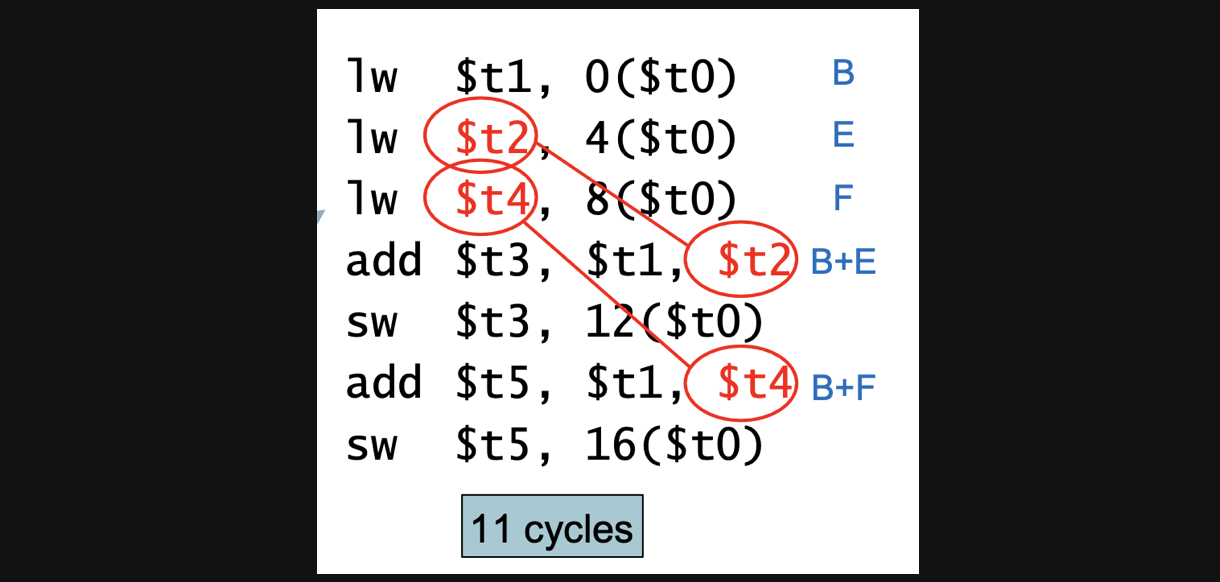
실행결과는 똑같지만 lw 바로 뒤의 연산의 register와 관련이 없어졌죠
애초에 load use hazard의 조건은 lw뒤에 rd register를 사용하는 연산이 있을때이기때문에 이 연산에서는 hazard가 발생하지않아 stall없이 11cycle만에 연산을 마칠수있습니다
결론적으로
1. stall은 performance를 떨어뜨리지만 올바른결과를 얻기위해 사용해야할떄가 있을수있다
2. 코드의 순서를 최적화해서 stall을 줄일수있기때문에 이 역할을 하는 compiler의 역할이 중요해졌다
3. compiler는 pipeline 구조에 대한 이해가 동반되어야한다
라고 할 수있습니다
어후............정말 길고길었네요.......
velog도 글을 길게 쓰니까 정말 버벅이고 있습니다
아직 branch hazard는 안적었는데 data hazard만으로도 이런 분량이 나오네요.....
어렵다기보다는 기존에있는 지식 + 시각적 자료 해석이 더해져서 조금 피곤할수도있는 섹션이었다고 생각해요
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
