본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다

6주차 내용으로 돌아온 킴스캐슬입니다. 아마 7주나 8주차가 되면 컴퓨터구조에 대한 정리가 끝날거같네요
끝나게되면 바로 다음 걸로 넘어가기전에 간단하게 혼공컴운이라는 책으로 전체적으로 훑어본다음에 운영체제 강의로 넘어가지 않을까 싶습니다
이번포스팅에서는 우선 저번 5주차내용에서 다루지 못했던 branch Hazard를 먼저다루고 컴퓨터의 성능(Performance)에 대해 다뤄보겠습니다
Branch Hazard
branch hazard는 왜 발생하는걸까를 한번 고민해보면 좋을거같습니다
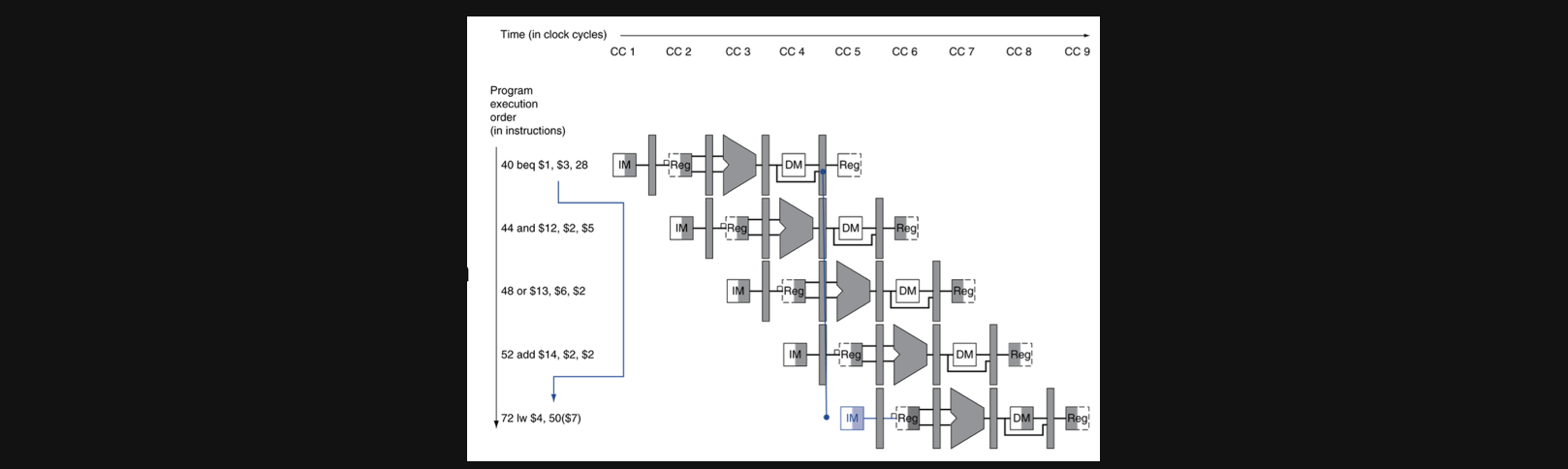
우선 branch가 된다는건 40번째 pc주소다음에 44번째 명령을 수행하는 것이 아니라 72번째줄의 instruction을 수행하라는 의미가 되고 결론적으로 branch를 하기위해 뛰어넘는 instruction은 수행할 필요가 없는 instruction이 됩니다
Solution to branch hazard
branch hazard의 해결 방식에는 크게 두가지가 있습니다
첫번째 방식은 stall입니다 말 그대로 branch되는 instruction이 수행될때까지의 모든 수행을 stall하게됩니다 하지만 역시 이방식은 전체적인 process의 효율성을 떨어뜨린다는 단점이 존재합니다
두번째 방식이자 자주 쓰이는 방식은 branch prediction입니다 이방식에는 staic과 dynamic으로 나뉘는데요 우선 기본적인 prediction의 static방식에 대해 이야기 해보겠습니다
static prediction
static방식은 prediction자체를 branch가 일어난다고 가정하거나 branch가 일어나지 않는다고 애초에 하나로 정해놓는 방식입니다
만약에 branch가 되지 않는다고 가정하고 그 가정이 맞는다면 바로 다음줄의 instruct을 수행한다고 계획을 짜놓은 상태이기때문에 stall이 없는것처럼 process가 수행됩니다 하지만 당연히 예측이 틀릴수도 있겠죠 그런 경우엔 예측이 맞을거라고 계산해놨던 결과를 지워야하고 이를 Flush라고 합니다. 그리고 예측이 틀린 경우엔 기본적으로 발생하는 stall을 그대로 수행해야합니다
우리가 공부하고 있는 MIPS에서는 not taken predict를 수행합니다
그런데 예측이 실패했을때 패널티로 다가오는 Flush와 stall을 줄일수 있는 방식은 없을까요?
기존에 우리가 예측을 실패했을때의 상황을 보겠습니다
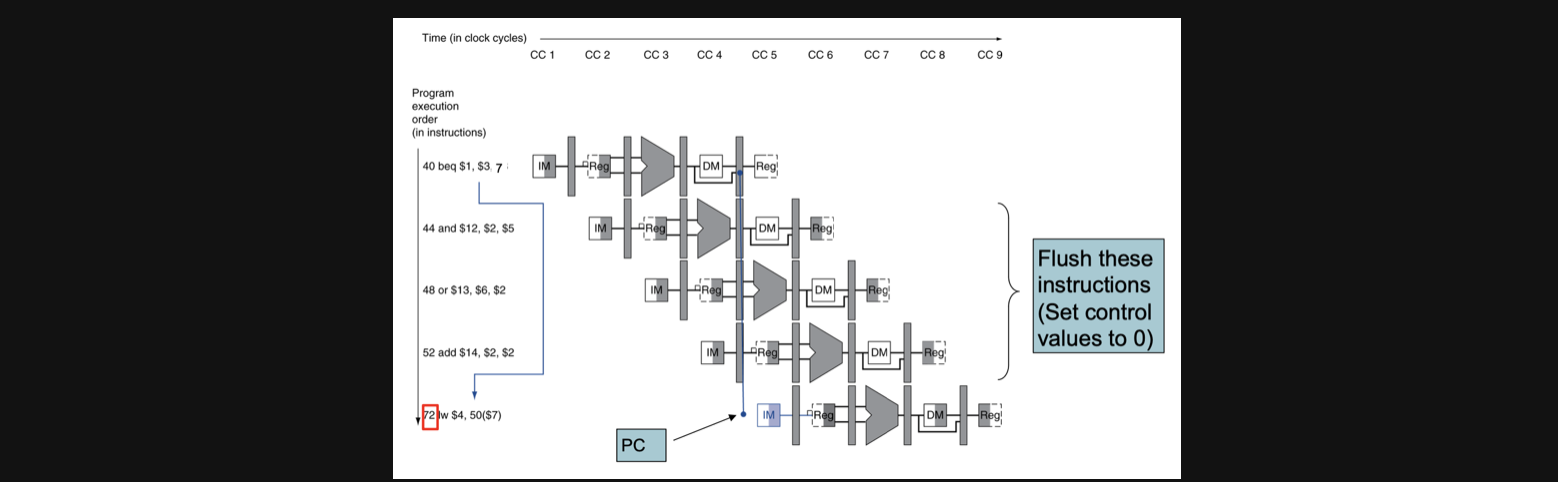
BTA의 연산결과가 CC4에서 정해지면 그때서야 branch를 해야해서 72번째 pc주소를 실행시키게 되는데 그렇게 되면 72번째 pc주소 전의 연산결과를 모두 flush해야합니다
이런 문제를 해결하기 위해서는 회로를 약간 변형시켜줘야하는데

BTA를 연산하는 adder를 ID stage로 옮겨줍니다(원래는 EX stage에 있던 연산자입니다)
그리고 register의 결과를 비교하는 연산자를 ID stage로 옮겨줍니다(원래는 EX stage에 있었음)
그렇게 되면 실제로 BTA연산과 비교연산을 실제로 하기도전에 연산 결과를 통해 branch를 할지안할지 미리 결과를 알 수있어서 예측이 실패했을때 flush해야하는 수를 조금이라도 더 줄일 수 있게됩니다
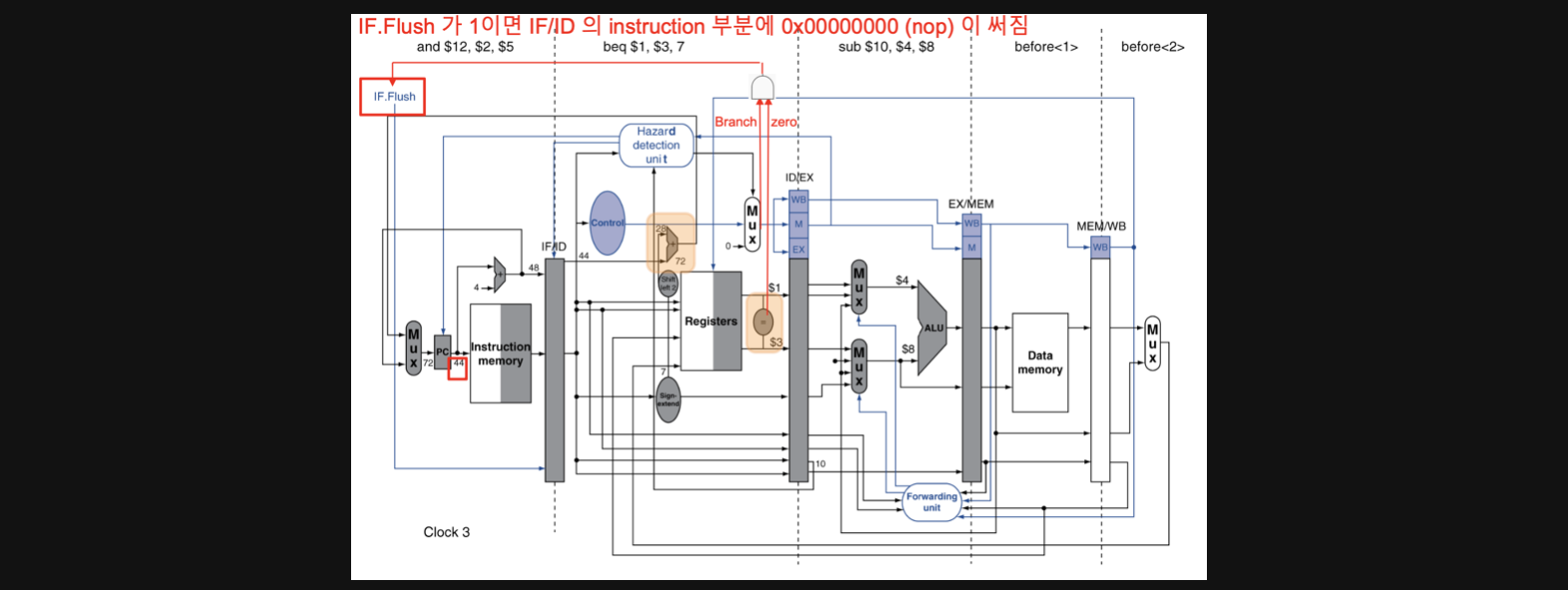
그림의 주황색 박스를 보시면 register의 return 값을 pipeline register에 보내는 와중에 비교연산을 하고 BTA를 하는 adder가 ID stage에 생긴것을 알 수 있습니다
이를통해서 branch를 하게된다면(MIPS기준으론 예측이 틀린경우) 바로 다음 clock cycle에서 바로 branch된 instruction을 수행할 수 있기때문에 stall이 한번만 실행되면되기때문에 패널티를 최대한 줄일 수 있습니다
또한 register값의 비교연산은 sub연산이 아니라 bitwise로 같은지를 파악하는 연산을 하는데 이유는 sub연산보다 bitwise연산이 빠르기 때문입니다
만약에 branch를 하게되면 원래 다음 pc주소의 instruction을 nop으로 만들어서 stall되게 해주는 방식으로 작동하게됩니다
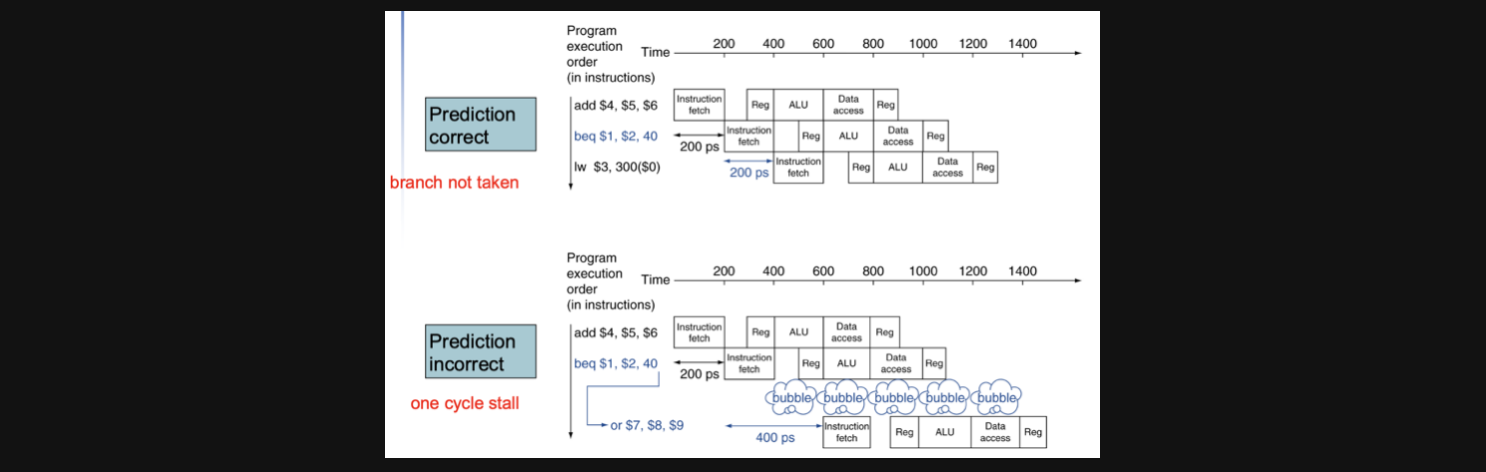
이렇게 되면 예측이 성공했을때는 아무런 문제없이 다음 연산 결과를 받아서 수행할수있고 혹여나 예측이 틀렸다 하더라도 단한번의 stall만으로 process를 수행할 수 있게됩니다
branch가 된다고 예측할지 안된다고 예측할지의 기준은 여러가지가 있겠지만
loop의 경우엔 branch보다는 순서대로의 연산수행이 많기때문에 이런경우엔 branch가 일어날 가능성이 낮아 taken(branch가 일어난다고 가정함)로 설정을 하고 보통 offset이 음수인경우에 loop일 가능성이 높아 taken으로 설정한다고 합니다
if의 경우엔 branch가 일어날 가능성이 높아서 not taken으로 prediction을 설정하고 보통 이런경우는 offset이 양수일 가능성이 높다고 합니다
dynamic prediction
dynamic방식의 경우 그때그때 상황에 따라서 taken으로할지 not taken으로 할지 결정하는 prediction방식입니다
연산의 결과들을 history에 기록해두고 그 기록들을 기반으로 dynamic하게 prediction을 수행하는 방식이라고 이해하면 될거같습니다
Performance
컴퓨터의 성능은 우리가 어떤 기준으로 좋다 나쁘다를 판별할 수 있을까요?
속도? 용량? 가격대비 속도?, 사용성?
여러가지 기준이 있기때문에 사실 한가지 기준만으로 컴퓨터의 성능을 판별할 수는 없습니다
하지만 이번 주제인 performance에서는 그중에서도 response time을 기준으로 두고 컴퓨터의 성능에 대해 알아보겠습니다
response time : 하나의 프로그램을 수행하는데 걸리는 시간
Relative Performance
Performance의 정의를 우리가
1 / ExecutionTime(수행시간)
이라고 정의할 수있습니다
따라서 우리가 X가 Y보다 n배 빠르다라는 말을 아래와 같은 수식으로 표현이 가능합니다
PerformanceX/PerformanceY = ExecutionTimeY/ExecutionTimeX = n
그래서 예를들어서 A라는 프로그램이 10초가 걸리고 B라는 프로그램이 15초가 걸릴때
A의 ExecutionTime이 10이고 B의 ExecutionTime이 15이기때문에 A가 B보다 1.4배 빠르다 라고 표현할 수 있습니다
Execution Time
그러면 정확하게 수행시간이라는건 어떻게 측정할 수 있을까요?
보통 Elapsed Time을 측정한다는 의미는 프로그램을 실행하는 동안 걸린 전체시간을 의미하는데 실제로 elapsed time을 측정해보면 아래와 같은 결과가 나옵니다

그림을 보면 user CPU time과 system CPU time과 elapsed time이 같이 나오는데 살제로 어떤 특정 프로그램을 실행하는데 수행된 시간은 user CPU time과 system CPU time입니다
그리고 우리가 앞으로 performance에 대해 공부하기 위해서 이중에서도 user CPU time을 중점적으로 볼 예정입니다
CPU Clocking

우리가 지금까지 clock cycle에 대해서 배울때 데이터의 변화가 생기는 순간 그 값이 쓰여지는것이 아니라 clock이 rising되는 순간에 데이터의 변화를 쓴다고 이야기를 했었는데요
한 clock cycle의 너비를 Clock period라고 합니다 이는 한번의 clock cycle동안 걸리는 시간을 의미합니다(우리가 과학시간에 배웠던 용어로는 주기정도가 되겠네요)
주기가 있다면 진동수도 있겠죠?
그리고 1초에 몇번의 clock cycle이 수행되는지를 나타내는 지표로 Clock frequency가 있습니다
이는 clock period와 역수관계입니다
CPU Time
이제 CPU Time을 정의할 수 있는 기본개념에 대해서 다 배웠습니다

CPU Time은 CPU의 clock cycle의 갯수와 하나의 clock cycle당 걸리는 시간을 곱해주면 됩니다
당연히 clock cycle time은 clock period를 의미하니 역수를 취하면 clock frequency 즉, clock rate가 됩니다
결국 우리가 CPU Time을 좋게 만드려면 식에 의해서 Clock Rate를 높이고 CPU의 Clock cycle을 낮추면 되겠죠
하지만 아쉽게도 Clock Cycle과 Clock Rate는 Trade off관계이기때문에 하나의 성능을 좋게만들면 그에 따라 다른 하나의 성능이 나빠지는 그런 관계성을 가지고 있다고 합니다
그럼 한가지 문제를 풀어보겠습니다
2GHz 클럭의 컴퓨터 A 에서 10초에 수행되는 프로그램이 있다.
이 프로그램을 6초에 수행하는 컴퓨터를 설계하고자 한다.
클럭속도는얼마든지빠르게만들수있는데이렇게하면CPU다른 부분의 설계에 영향을 미쳐 같은 프로그램에 대해 A보다 1.2 배 많은 클럭 사이클이 필요하게 된다고 한다.
컴퓨터 B의 클럭 속도는 얼마로 해야 하겠는가?
실제로 이 문제를 우리가 지금까지 배웠던 풀이에 적용을 해보면 아래와 같은 풀이과정을 도출해낼 수 있습니다

풀이보다는 결과를 한번 해석해보는게 중요할것같습니다
분명히 A컴퓨터의 Clock rate가 2GHz였고 B컴퓨터가 4GHz가 되었으면 2배의 성능향상이 이루어져야할거같은데 문제에서 보면 10초에서 6초로 빨라졌으니 10/6배가 빨라졌습니다
이렇게 clock rate가 2배늘어났어도 clock cycle이 trade off로 늘어나 실제로는 2배보다 적은 성능향상 결과를 얻게 됩니다
Instruction Count and CPI
자 그러면 우리 이번엔 Clock Cycle을 구하는 방법에 대해 알아보죠

결국 우리가 clock cycle을 구하기 위해서는 instruction당 필요한 clock cycle의 갯수와 instruction의 갯수를 알아야합니다. 그래야 우리가 원하는 연산을 하는데 총 몇개의 clock cycle이 필요한지 계산이 되니까요
그러면 이전에 배웠던 CPU Time에 clock cycle공식을 대입해보겠습니다

여기서 CPI는 Cycles per Instruction의 약자입니다 앞으로 많이 나올테니 기억해두면 좋을거같아요
CPU Time을 줄이기 위해선 Instruction Count와 CPI의 곱이 낮으면 좋은데 Instruction Count는 어떤 요소에의해 결정되는지를 생각해보면 우리가 배웠던 MIPS같은 ISA에 의해서 결정되고 Compiler에 의해서도 결정이 되기도 합니다
그리고 CPI의 경우엔 이런 경우가 있죠
연산마다 필요한 cycle이 다른경우
이런 경우엔 CPI를 어떻게 계산해야할까요?
결론부터 말씀드리면 weighted average라는 방식으로 평균치를 계산합니다 단순히 산술적인 평균값이 아니라 자주 등장하는 instruction의 경우엔 가중치를 더 주는 방식으로 평균을 내서 CPI를 결정합니다
CPI예제를 한가지 가져와봤습니다
Computer A: Cycle Time = 250, CPI = 2.0
Computer B: Cycle Time = 500, CPI = 1.2
위와 같은 조건에서 뭐가 더 빠르며 얼마나 더 빠른가?
(같은 ISA를 사용한다 = instructon count는 동일한 조건이다)
A의 CPU Time을 계산해봅시다
A의 CPU Time = Instruction Count * CPI * Cycle Time = I * 2.0 * 250 = 500IB의 CPU Time을 계산해봅시다
B의 CPU Time = Instruction Count * CPI * Cycle Time = I * 1.2 * 500 = 600IA가 더 작은값이니까 A가 6/5배 즉 1.2배 더 빠르다는 답을 낼 수 있습니다
CPI의 weight average

CPI의 i라는건 i종류의 instruction당 걸리는 cycle의 갯수를 의미합니다
그리고 i종류의 instruction이 전체 instruction갯수에 비해 몇개 존재하는지를 곱한값을 전체적으로 다 더한 결과가 weight average방식으로 CPI를 구한 결과가 됩니다
여기서 weight의 의미는 특정 instruction이 전체 갯수중에 얼만큼의 비율로 있느냐라고 생각하시면 좋을거같습니다
Performance Summary

CPU Time은 세가지 요소의 곱으로 나타낼 수 있습니다
우선 맨 앞의 요소는 Instruction의 갯수입니다 프로그램당 instruction의 갯수니까 결국 instruction의 갯수가 됩니다(IC)
두번쨰 요소는 instruction당 clock cycles수입니다 좀전에 배웠던 CPI입니다(CPI)
마지막 요소는 clock cycle당 걸리는 시간을 의미합니다(T)
우리 아래와같은 방식으로 CPU의 performance를 좋게 할 수 있습니다
알고리즘을 잘짜면 IC와 CPI에 영향을 줄 수 있습니다
프로그램 언어를 선택함에 따라서 IC와 CPI에 영향을 줄 수 있습니다
컴파일러를 선택함에 따라서 IC와 CPI에 영향을 줄 수있습니다
ISA를 선택함에 따라서 IC, CPI, T에 영향을 줄 수있습니다
Instruction Set Architecture(ISA)
이번에는 우리가 지금까지 배웠던 ISA에 대한 약간의 요약을 해보려합니다
ISA는 중요한 추상체라고 합니다
이게 무슨뜻일까를 좀더 고민 해보면 Instruction이 어떤게 있으며 그 Instruction이 어떤 연산을 하고 기계어로 표현할때는 어떻게 표현될지를 표준화한게 ISA이고 이런 것들에 대한 추상을 제공한다는 의미로 해석하면 될거같습니다
hardware와 low-level의 software의 접접에 있습니다
이 말은 그림을 보시면 바로 이해하실수있을거같습니다

ISA는 software의 아랫단계와 hardware의 사이에서 상호작용하는것을 도와주는 역할을 한다는걸 그림을 통해 확인할 수있습니다
Reduced Instruction Set Computer Architecture
예전에는 CPU Time을 좋게하기 위해서 어떻게 했을까에 대한 부분을 알아보려합니다
그림에서 첫번째 요소를 IC 두번째 요소를 CPI 세번째 요소를 T라고 하겠습니다
예전에는 하나의 instruction이 여러 종류의 연산을 수행하기 위해서 하나의 instruction을 복잡하게 설계했다고 합니다
그러다 보니 instruction의 갯수는 줄어 IC는 줄었지만 하나의 연산을하는데 걸리는 시간과 cycle수가 늘어서 CPI와 T가 늘어났습니다
하지만 현대에 와서 instruction의 갯수를 줄이고 규칙성을 가지고 명령을따르도록 instruction set을 구성했습니다 그러다보니 instruction의 갯수는 늘어났지만 CPI와 T가 줄어서 CPU Time을 향상시킬수있었다고 합니다
T가 줄어들었단 말은 clock rate가 증가했다는 말과 일맥상통합니다 frequency가 증가하려면 어떤게 필요할까요? 더 높은 출력의 power가 필요하고 이를 통해 발생하는 열을 해결해야합니다
Power Trends
컴퓨터가 처음나왔을때 비해서 현대의 컴퓨터는 1000배의 frequency를 가지게 되었습니다
1초에 1000배나 많이 clock cycle이 발생한다는 의미기도 합니다
그리고 frequency는 power와 비례합니다
그렇다면 frequency가 1000배 늘었으니까 필요한 power도 과거에 비해 1000배가 늘었을까요?

컴퓨터가 발전하는 동안 capacity의 load를 줄이고 voltage를 5분의 1로 줄인 덕에 frequency가 1000배 늘어난것에 비해 power는 30배정도만 늘어난 상태입니다
그러면 frequency를 계속늘리고 voltage랑 capacity를 줄이면 되는거네요?
하지만 이는 한계가 있습니다
voltage랑 capacity를 줄이는데 한계가 있기때문에 frequency를 무한정 늘릴수가 없게됩니다
이러한 한계를 the power wall이라고 합니다
대신 그래서 물리적으로 processor를 두개이상 사용하는 multi processor방식을 사용해서 컴퓨터의 성능을향상시키게 됩니다
이번포스팅은 뭔가 엄청나게 이론적인 내용이 있었다기 보다는 앞으로 배울 muti processor에 관한 내용을 배우기 위한 온보딩 세션이었던거같습니다
컴퓨터의성능을 수치화 하는방법과 과거에서 현재까지의 성능의 변화 그 결과로 우리는 지금 어떤 선택을 해서 컴퓨터의 성능을 발전시키고 있는지의 스토리를 따라서 한번 쭉 읽어보시면 좋을거같아요
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
