
텍스트 요약의 갈래
오늘 소개할 추상적 요약(Abstractive Summarization) 은 추출적 요약과 더불어 텍스트 요약의 주요한 주제입니다.
우선 이에 앞서, 이들의 차이점을 비교하기 위해 추출적 요약(extractive summarization)을 먼저 살펴보고자 합니다.
'추출적 요약'이란
추출적 요약은 원문에 있는 중요한 핵심 문장 또는 구를 뽑아 요약 결과를 내는 방식을 말합니다. 원문에 하이라이트를 친 값을 합친 결과라 볼 수도 있겠네요. 추출적 요약을 위한 알고리즘으로는 주로 기계 학습의 그래프 기반의 비지도학습인 텍스트 랭크(TextRank)를 사용합니다.
백문이 불여일견, 이러한 텍스트 랭크을 토대로 하는 '세줄 요약기'를 이용해 쿨의 아로하를 요약해볼까요?
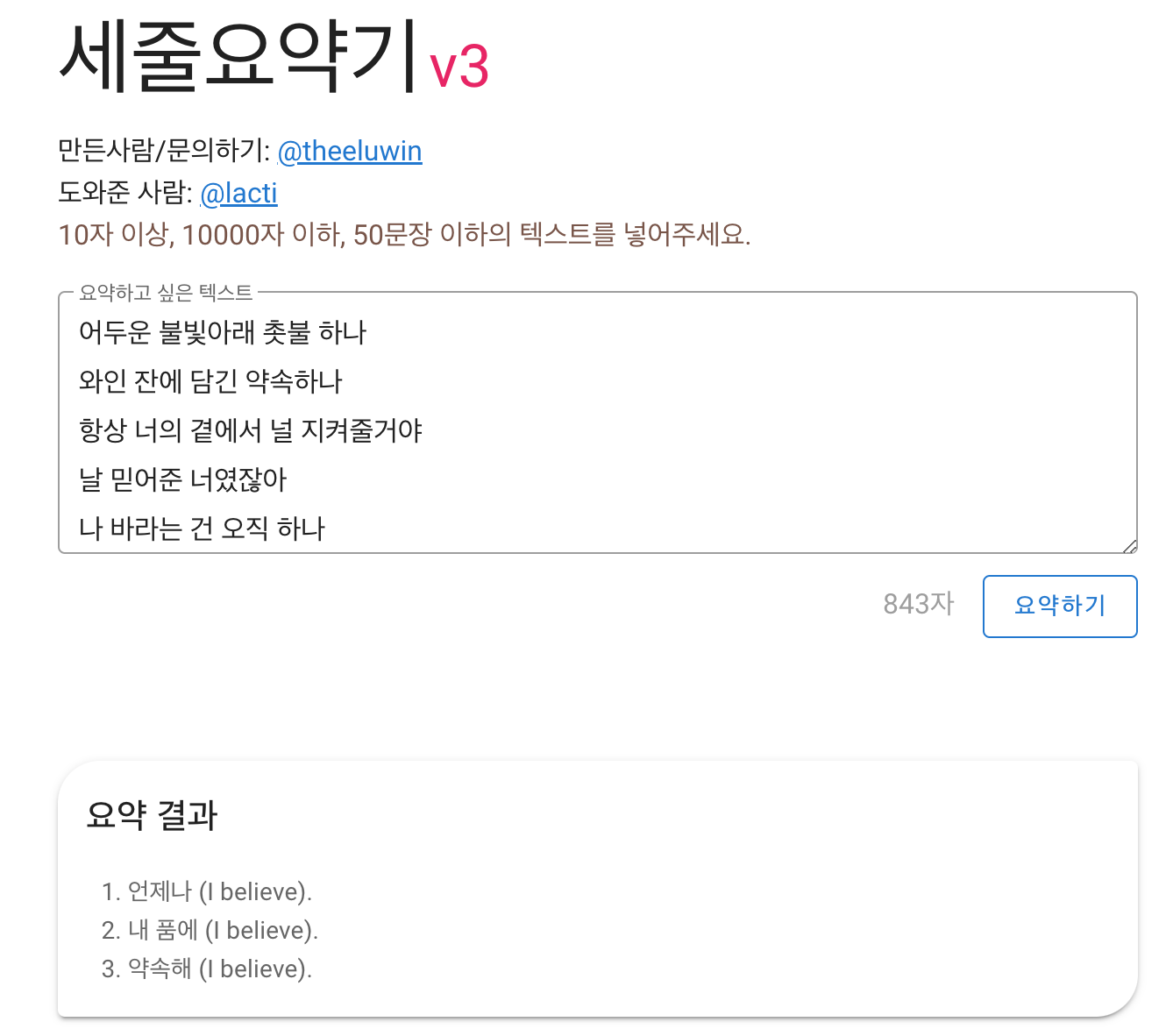
재밌게도 노래의 클라이막스 부분이 요약되었네요. 꽤나 노래의 주제를 잘 살려준 요약으로 보입니다.
'추상적 요약'이란
그렇다면 추상적 요약은 추출적 요약과 어떤 점이 다를까요?
추상적 요약은 원문에 없는 표현이라도 새로운 표현을 생성해 원문을 요약하는 방식입니다. 말그대로 인간의 영역이라 생각되는 추상적 언어 이해를 다루고 있습니다. 수능 문제집 한켠의 작품 해설 또는 줄거리란을 언젠간 기계가 작성하게 될지도 모르겠습니다. 이 포스팅도 기계가 해주면 어떨까...
문장 생성을 위해서 인공신경망이 이용되는데 RNN, Transformer encoder-decoder 모델이 주가 됩니다. 인공신경망으로 추상적 요약을 훈련하기 위해서는 레이블 데이터로 요약문이 필요합니다. 추상적 요약의 여러 SoTA 모델을 참고하던 중, Fine Tuning 데이터의 요구수가 적어도 좋은 성능을 내는 것으로 보이는 PEGASUS에 관심을 갖게 되었습니다.
AESLC
AESLC(Annotated Enron Subject Line Corpus)은 이메일 본문을 참고해 효과적인 이메일 제목을 생성하는 연구과정을 통해 만들어진 데이터셋입니다.
도메인은 비즈니스/개인이며 총 18,302개 레코드(train-14,436/val-1,960/test-1,906)로 이루어져어 있습니다. 원문은 평균 75개의 단어로, 요약문은 평균 4개 단어로 구성되어있습니다.
더 알아보기 : https://paperswithcode.com/dataset/aeslc
PEGASUS
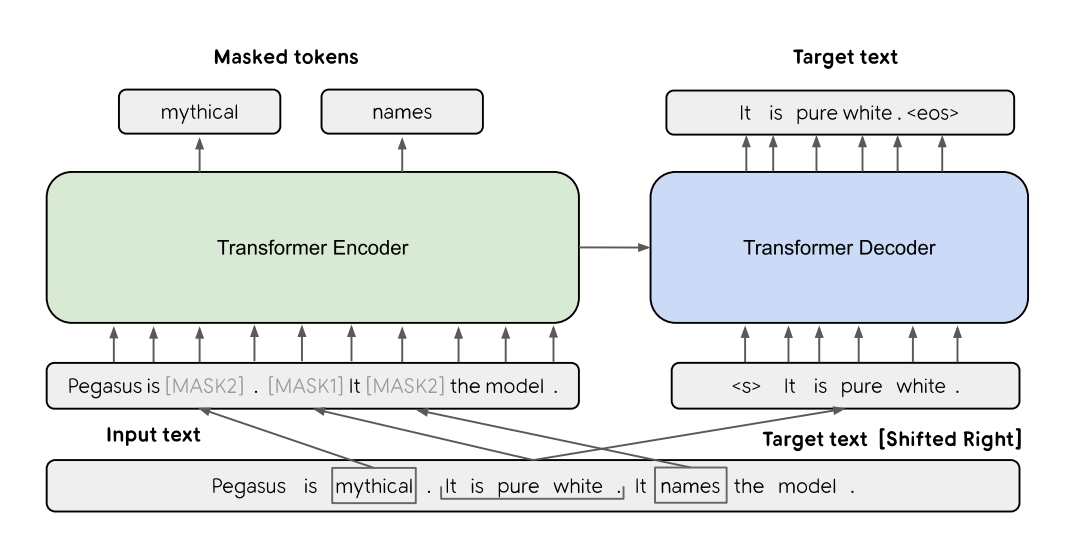
PEGASUS의 기본 아키텍쳐는 Transformer 기반의 encoder-decoder 모델입니다.
그림과 같이, pre-training 단계에서는 입력된 3개의 문장 중 한 문장은 [MASK1](Gap Sentences Generation, GSG)으로 마스킹해 타겟 생성 텍스트로 사용합니다. 입력에 남은 다른 두 문장은 [MASK2](Masked Language Model, MLM)에 의해 일부 토큰이 무작위로 마스킹됩니다. 이후 transformer를 거쳐 마스킹된 문장들이 합쳐서 결과값으로 나오게 됩니다.
Keywords
GSG
MLM
더 알아보기 : https://paperswithcode.com/paper/pegasus-pre-training-with-extracted-gap

텍스트 요약에 대해 관심 있었는데, 이번에 같이 도전해보면 좋을 것 같습니다. 고생하셨습니다!