STS
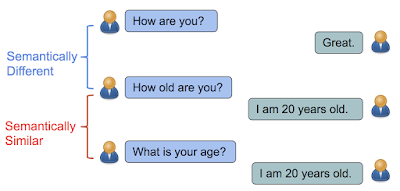
STS(Semantic Textual Similarity)는 텍스트의 의미적 유사도를 측정하는 문제입니다.
모델이 의미상 두 문장의 친밀도를 얼마나 잘 잡아내는지 또는 문장의 의미적 표현을 얼마나 잘 구현하는지 평가하는데 일반적으로 사용됩니다.
예를 들어, 음식점을 돌아다니며 고객 서비스를 제공하는 자율주행 로봇에게 다음의 질문을 하려합니다.
예: 결제는 어디에서 하나요? ≒ 계산하는 곳이 어디인지 알려주세요.
과연 로봇은 두 질문에 같은 답변을 준비할 수 있을까요? (그래야 할 텐데요..) 위의 두 문장은 의미적으로 같지만 통사적으로는 제법 달라 보입니다. 하지만 사람마다 개성이 다르듯 한 질문에 대한 표현역은 천차만별일 겁니다.
STS는 다양한 어플리케이션에 활용될 수 있습니다. 일례로 지난 리뷰에서 소개한 Quora는 대표적인 지식 공유 서비스입니다. 만일, 실생활에서 생기는 여러 질문들을 Quora에 검색해본다고 합시다. 사실상 의미적으로 중복된 질의임을 기계가 인식할 수 있다면 검색 처리 과정의 많은 비용이 절감될 것입니다.
따라서 비슷한 의미를 가진 문장을 모아서 일정한 응답를 제공할 수 있다면 서비스의 효율성이 제고되겠지요. 특히 자연어 이해(NLU)에서 STS는 핵심 과제이며, 많은 NLP 응용 프로그램 및 관련 영역의 기본 작업이 됩니다.
의미적 유사도는 어떻게 측정하는가?
초기의 연구 주제가 짧은 텍스트 단위에서의 STS 식별이었다면, 근 10년 간의 연구는 점차 더욱 방대한 문서와 개별 단어로 초점이 옮겨졌습니다.
이에 따라 의미적 유사도는 (i) 토폴로지 (ii) 통계적 유사도 (iii) 의미 기반 (iv) 벡터 공간 모델 (v) 단어 정렬 기반 및 (vi) 기계학습 방법과 같이 다양한 측정 방식을 따를 수 있습니다.
도출된 유사도는 방법론에 따라 유사성의 유/무뿐 아니라 0~5의 점수를 가진 척도로 표현되기도 합니다.
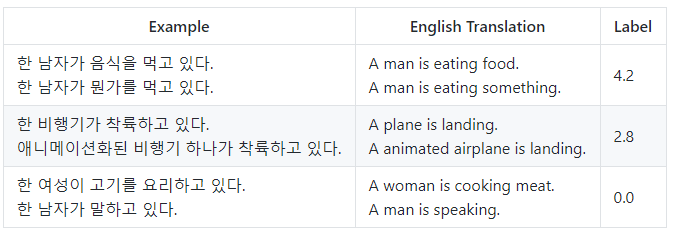
(0 - 의미적 동등성 없음, 5 - 의미적으로 동등함)
STS이 해결하고자 하는 문제는 무엇인가?
앞서 언급했듯, STS는 자연어 처리 영역 전반의 고도화에 발을 걸치고 있습니다.
STS는 정보 검색 및 추출, 문서 요약, QA(질의 응답), 단어 의미 명확화와 같은 많은 작업에 중요한 구성 요소입니다. 데이터베이스 분야에서도 텍스트 유사성은 의미론적 이질성을 해결하기 위한 스키마 매칭에 사용되거나 조인의 향상에 영향을 줄 수 있습니다.
KorSTS
KorSTS은 카카오브레인의 한국어 자연어처리 공개 데이터셋입니다.
대부분의 자연어 처리 연구는 사람들이 많이 쓰는 언어들을 바탕으로 연구가 되므로, 기존의 벤치마크 데이터셋(STS Benchmark, MRPC)은 영어로된 STS만을 제공해왔습니다. 이에 한국어로 된 자연어 데이터셋이 부족하다는 문제 의식의 발로로 KorSTS이 구축되었다고 합니다.
KorSTS의 구성
.png)
KorSTS 데이터셋은 총 8,628개의 레코드를 가지고 있으며, 각 문장은 평균 7.7개의 단어로 이루어져있습니다.
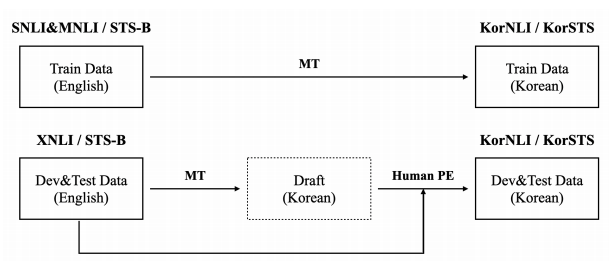
위의 그림을 통해 알 수 있듯, KorSTS은 STS-B 데이터셋을 기반으로 만들어졌습니다.
먼저 STS-B의 영어 test set, develop set, test set을 사내 엔진을 이용해 기계 번역(MT)하고, 이후 develop set과 test set는 전문 번역가에게 사후편집시키는 다단계 전략을 사용했습니다.
특히 사후편집 과정에 관한 세부 전략에서 사람이 직접 개입하는 몇몇 요소(크로스 체크, MS워드 체크 등)의 언급이 상당히 인상 깊었는데, 데이터셋의 구축 과정에 관심있으신 분들은 아래 링크를 통해 원문을 참고해주시기 바랍니다. 저 또한 가능하면 추후 추가하도록 하겠습니다.
Korean RoBERTa
Korean RoBERTa는 KorSTS의 연구진들이 선정한 한국어 STS 베이스라인입니다.
STS는 두 개의 문장이 입력으로 제공되기 때문에, 두 문장을 처리하는 방식에 따라 베이스라인이 달라질 수 있습니다. 그중 이 포스트에서 소개하는 한국어 RoBERTa는 모델이 문장을 공동으로 인코딩하는 Cross-encoding 접근법의 베이스라인입니다.
Korean RoBERTa는 65GB 크기의 한국어 말뭉치*를 RoBERTa(Liu et al., 2019) 모델에 사전 훈련하고 이후 미세 조정(fine tune)합니다.
*온라인 뉴스 기사(56GB), 백과사전(7GB), 영화 자막(∼1GB), 세종 코퍼스(∼0.5GB)로 이루어짐
Keywords
baseline
Cross-encoding


저도 이 Task에 관심이 있어서 많이 찾아봤었는데 설명 잘 해주신 것 같습니다. 수고하셨습니다.