
Dialogue Generation
오늘 소개할 대화 생성(Dialogue Generation)은 우리가 AI에게 기대하는 많은 것들을 담고 있습니다.
먼저 대화 생성을 이야기하며 빼놓을 수 없는 '챗봇'은 이미 우리의 일상에서 익숙하게 볼 수 있는 풍경이자 대화 시스템(dialogue system)의 주요 어플리케이션입니다. 이러한 대화 시스템은 크게 다음의 두 분류로 나누어볼 수 있는데요.
문제 해결형 대화Task-oriented Dialogue
: 사용자가 제시한 문제를 해결할 수 있는 응답을 생성합니다. 가상 비서인 Siri, Alexa에게 특정 태스크를 맡길 경우를 떠올리시면 됩니다.자유 대화Open domain Dialogue
: 사용자와 잡담을 이어갈 수 있도록 하는 것이 목표입니다. 어떤 주제로 말을 걸어도 적절한 응답을 생성해야합니다. 각 챗봇 마다 응답 전략이 회피/정보 제시 등 상이하게 나타납니다.
이러한 대화 시스템을 만들기 위해서는 답변을 기계가 직접 생성하거나, DB에서 답변을 고르도록 해야할 것입니다.
이중 오늘의 주제인 '대화 생성 모델'은 전자에 해당되겠지요. 대화 생성 모델이 고도화되면서 Jiwei Li 박사는 <Teaching Machines to Converse>에서 다음과 같은 연구 질문을 던지게 됩니다.
'대화 생성 모델이...'
- 좀 더 다양한 답변을 생성할 수 있을까?
- 좀 더 일관성 있는 캐릭터를 가진 챗봇을 학습시킬 수 있을까? (✓)
- 좀 더 긴 대화를 이끌 수 있을까?
- 모르는 것을 물어보는 챗봇을 만들 수 있을까?
- 인간이 직접 가르치는 챗봇을 만들 수 있을까?
캐릭터의 일관성을 지켜라
생성 모델은 수많은 사람들의 뒤엉킨 발화를 모두 학습합니다. 그렇기에 기계가 일관성 있는 문장을 생성하지 못하는 문제가 자연히 발생하게 됩니다.
일례로 아래의 대화에서 기계는 LA에 살았다가 마드리드, 잉글랜드로 말끝마다 한시 바삐 거주지를 옮기는 것처럼 보입니다. 캐릭터의 일관성을 지키지 못하면 사용자가 갖는 대화형 인공지능에 대한 기대 격차는 더욱 벌어지게 됩니다.

페르소나를 가진 인공지능
영화 'Her'을 기억하시나요? 사만다는 놀랍도록 인간을 이해하는 대화형 인공지능 시스템입니다. 주인공은 사만다에게 자신의 일상다반사를 나누며 깊은 유대를 형성해갑니다. 인간처럼 말한다고 해서 대화가 지속되는 것은 아닙니다.(나와 잘 안맞는 사람을 한 명 떠올려보세요) 이들의 자연스러운 대화는 서로의 페르소나에 대한 깊은 이해가 전제된 결과입니다.
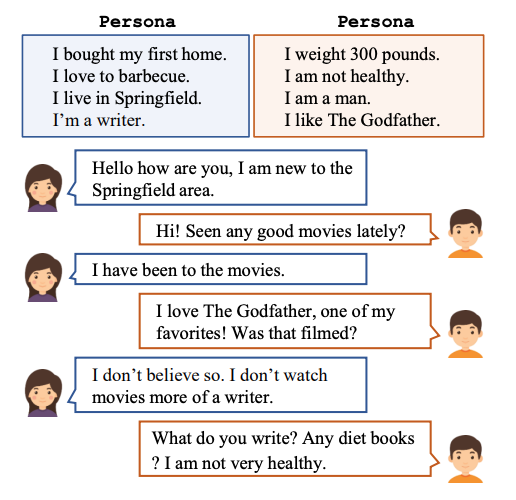
그림의 대화에서 두 명의 대담자는 "Seen any good movies lately?"라는 개인적인 주제를 제기하거나 "I don’t watch movies more of a writer."처럼 자신의 모습을 드러내기도 합니다. 이렇게 페르소나를 통해 상호 간의 이해를 구축한다면 대화의 흐름이 일관성 있게 유지될 수 있습니다.
썸네일의 구글 LaMDA(Language Model for Dialogue Applications) 또한 자신을 '명왕성'이라 롤플레잉하며 질의에 대한 답변으로 일정한 페르소나를 유지하고 있습니다.
PERSONA-CHAT
Persona-Chat 데이터셋은 크라우드소싱 마켓인 Amazon Mechanical Turk를 통해 수집되었습니다.
크라우드소싱을 통해 만든 (i) 페르소나와 (ii) 이를 수정한 페르소나를 통해 (iii) 마찬가지로 작업자들이 인공 페르소나로 대화한 데이터의 집합이라 할 수 있습니다.

PERSONA-CHAT의 구성
-
페르소나
훈련용 페르소나 955개, 검증용 100개, 테스트용 100개로 구성되어 있습니다.
이 데이터셋에서 페르소나는 일종의 몇 가지 프로필 문장으로 표현됩니다.
"나는 스키를 좋아합니다", "나는 예술가입니다", "나는 매일 아침 식사로 정어리를 먹습니다",.. -
페르소나 대화
총 10,907 건의 대화를 통해 162,064개의 발언 데이터셋이 생성되었습니다.
그 중 15,602개의 발언(1000개의 대화)이 검증을 위해, 15,024개의 발언(968개의 대화)이 테스트용으로 할당되었습니다.
더 알아보기 : https://arxiv.org/abs/1801.07243
P^2 Bot
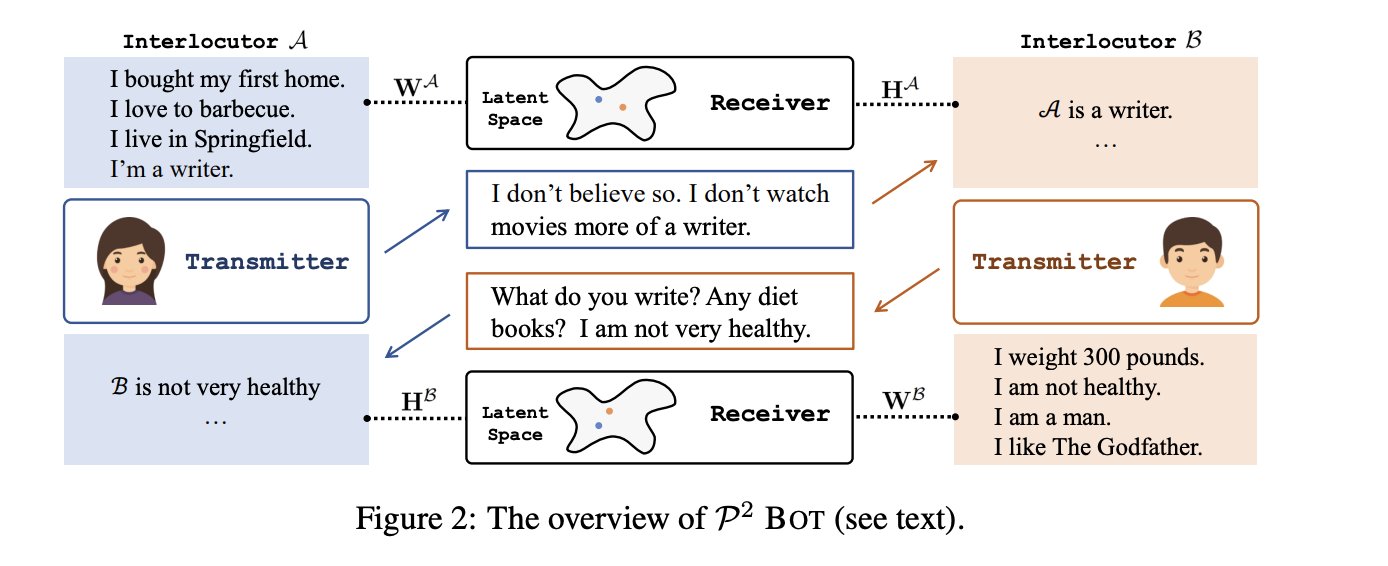
Persona Perception Bot (P2 BOT) Transmitter와 Receiver를 이용해 상호 페르소나 인식을 명시화하여 개인화된 대화형 인공지능의 성능을 향상시키는 프레임워크입니다.
그림의 화자A를 기준으로 P2 BOT의 간략한 절차를 살펴보겠습니다.
- 화자A는 페르소나 W^A를 가지고 있습니다.
이때, 화자A의 프로필 문장 집합은 {w_1^A, w_2^A, .., w_n^A}입니다. - 화자A와 화자B가 n번의 대화를 나눕니다.
- n번의 대화가 종료되면 Transmitter가 생성됩니다.
- 이후 대화가 반복되면서 서로에 대한 인상이 구축됩니다.
"I don't believe so. I don’t watch movies more of a writer." -> A is a writer...
"What do you write? Any diet books? I am not very healthy." -> B is not very healthy... - Receiver는 A에 대한 B의 인상이 A의 페르소나와 같은지 확인합니다. (그 반대의 경우도 마찬가지입니다)
더 알아보기 : https://paperswithcode.com/paper/you-impress-me-dialogue-generation-via-mutual
Keywords
Open domain Dialogue, Transmitter, Receiver
