Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations 제3부 method
Method
A. Problem setting
Zero-shot learning aims to recognize classes that have no labeled data in the training set.
제로샷 학습은 훈련 세트에 레이블이 지정된 데이터가 없는 클래스를 인식하는 것을 목표로 합니다.
We follow other embedding-based methods [23], [25], [26] to use the seen class semantics and their visual features to learn an embedding function during training.
우리는 다른 임베딩 기반 방법[23], [25], [26]을 따라 본 클래스 의미와 시각적 특징을 사용하여 훈련 중에 임베딩 기능을 학습합니다.
We denote by and the set of image visual features, and the set of image class labels, for seen (s) and unseen (u) classes, respectively.
denote 나타내다
우리는 '와 로 이미지 시각적 기능 세트, 와 는 각각 보이는 클래스와 보이지 않는 (u) 클래스에 대한 이미지 클래스 레이블 집합을 나타냅니다.
The training set for seen classes is represented as of elements and has classes in total.
보이는 클래스에 대한 학습 세트는 요소의 로 표시되며 총 클래스가 있습니다.
The test set for unseen classes is similarly represented as for elements and has classes in total.
보이지 않는 클래스에 대한 테스트 세트는 요소에 대해 로 유사하게 표시되며 총 클래스가 있습니다.
There are in total K object attributes shared between seen and unseen classes while there is no overlap between 'Ds' and Du.
와 사이에는 겹치지 않는 반면 보이는 클래스와 보이지 않는 클래스 간에 공유되는 총 K 객체 속성이 있습니다.
In the conventional ZSL, the task is to recognize only unseen classes.
기존 ZSL에서 작업은 보이지 않는 클래스만 인식하는 것입니다.
In the more realistic GZSL, the task is to recognize both the seen and unseen classes.
보다 현실적인 GZSL에서 작업은 보이는 클래스와 보이지 않는 클래스를 모두 인식하는 것입니다.
Unless specified, below we omit superscript s or u.
specified 명시하다, omit 생략하다
명시되지 않는 한 아래에서는 's 또는 u'를 생략합니다.
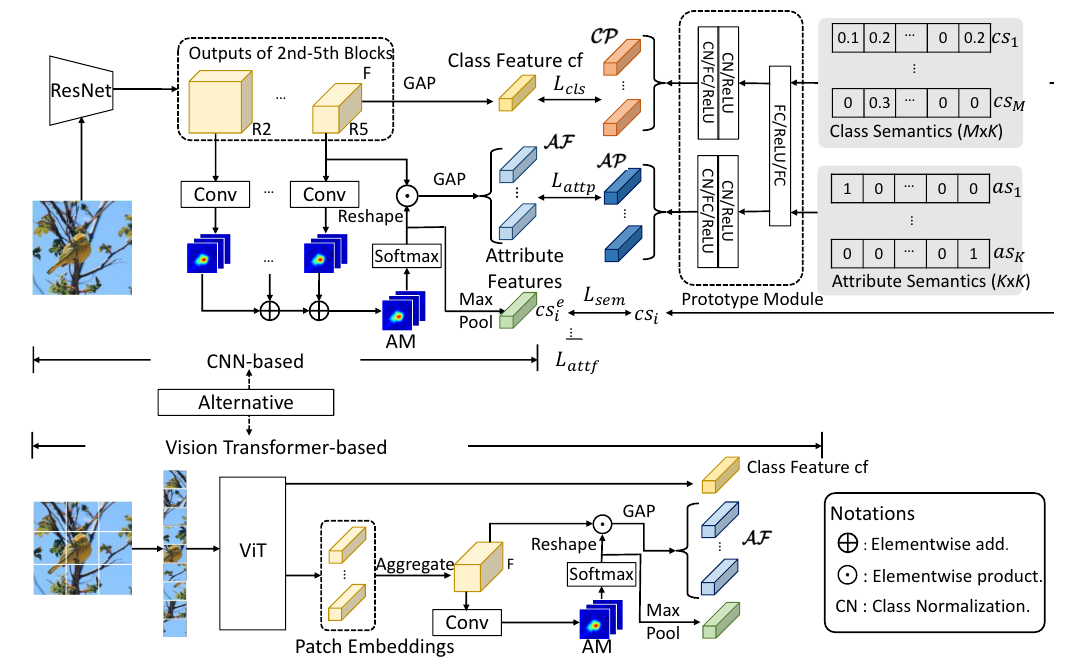

Fig. 2. Framework of our CoAR-ZSL.
Looking from the right, the prototype module takes the input of class and attribute semantics and outputs the class and attribute prototypes.
오른쪽에서 보면 프로토타입 모듈은 클래스 및 속성 의미 체계의 입력을 받아 클래스 및 속성 프로토타입을 출력합니다.
Looking from the left, for an input image, class- and attribute-level features will be extracted separately to contrastively optimize with corresponding class and attribute prototypes ( ).
separately 각각,contrastively 대조적으로
왼쪽에서 보면 입력 이미지의 경우 클래스 및 속성 수준 피쳐가 별도로 추출되어 해당 클래스 및 속성 프로토타입()과 대조적으로 최적화된다.
Another hard example-based contrastive loss ( ) is also included to reinforce the attribute representation learning; it is not specified in the figure, see Sec. III-D3 for more details.
또 다른 하드 예제 기반 대조 손실 ()은 속성 표현 학습을 강화하기 위해 또한 포함됩니다. 그림에 명시되어 있지 않으므로 자세한 내용은 Sec. III-D3을 참조하십시오.
B. Overview
The overview of our proposed new framework CoAR-ZSL is shown in Fig. 2: two main data streams flow into it from the right and left side for prototype generation and feature embedding, respectively.
제안된 새로운 프레임워크 CoAR-ZSL의 개요는 그림 2에 나와 있습니다: 프로토타입 생성 및 기능 임베딩을 위해 각각 오른쪽과 왼쪽에서 두 개의 주요 데이터 스트림이 흐릅니다.
For feature embedding, two alternative backbones, i.e. CNN-based (default) and Transformer-based, are presented.
기능 임베딩의 경우 두 가지 대체 백본, 즉 CNN 기반(기본값) 및 Transformer 기반이 제공됩니다.
1) Prototype generation: Looking from the right, we design a class and attribute prototype generation module which takes the input of class and attribute semantics, and , and outputs class and attribute prototypes, and , respectively.
1) 프로토 타입 생성 : 오른쪽에서 보면 클래스 및 속성 의미 체계 인 및 의 입력을 받아 클래스 및 속성 프로토 타입 생성 모듈을 설계하고 클래스 및 속성 프로토 타입 인 및 을 출력합니다. 각각.
2) Class representation learning: Given an input image x from the left side, we can extract its class-level global feature cf directly from the backbone.
2) 클래스 표현 학습: 왼쪽에서 입력 이미지 x가 주어지면 백본에서 직접 클래스 수준 전역 기능 cf 를 추출할 수 있습니다.
Its cosine similarity is computed against CP and optimized via the cross entropy loss for classification ().
코사인 유사성은 CP에 대해 계산되고 분류를 위한 교차 엔트로피 손실()을 통해 최적화됩니다.
3) Attribute representation learning: Given the image x, we can extract its attribute-level local features via the attention-based attribute localization scheme, which produces an attention tensor AM incorporating a set of attention maps, which are used as soft masks to localize different attribute-related regions in x and extract AF from them.
incorporating 통합
3) 속성 표현 학습: 이미지 x가 주어지면 어텐션 기반 속성 현지화 체계를 통해 속성 레벨 로컬 특징 을 추출할 수 있습니다. 이는 집합을 통합하는 어텐션 텐서 AM을 생성합니다. x에서 서로 다른 속성 관련 영역을 지역화하고 그로부터 AF를 추출하기 위해 소프트 마스크로 사용되는 어텐션 맵.
For each af in AF, it is optimized against the corresponding ap using a contrastive triplet loss ().
AF의 각 af에 대해 대조 삼중항 손실()을 사용하여 해당 ap에 대해 최적화됩니다.
For learning better af across images, another hard example-based contrastive optimization loss () is also devised to reinforce the similarity of attribute-level features corresponding to the same attribute.
이미지 전체에서 더 나은 af를 학습하기 위해 동일한 속성에 해당하는 속성 수준 기능의 유사성을 강화하기 위해 또 다른 하드 예제 기반 대조 최적화 손실()도 고안되었습니다.
Finally, to focus on the attribute-related regions, we maxpool it to obtain a semantic vector and minimize its distance to the ground truth ( ).
마지막으로, 속성 관련 영역에 AM을 집중하기 위해 의미 벡터 를 얻기 위해 최대 풀링하고 지상 진실 ( )까지의 L2 거리를 최소화합니다.
